Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC

Last week, Soft Machines announced that their 'VISC' architecture was available for licensing, following the announcement of the original concepts over a year ago. VISC, in a nutshell, is designed as a solution to improving the number of instructions per clock a single thread can process in a given time, which potentially makes it a very interesting design in an era where IPC gains are harder and harder to realize.
The concepts behind their new ‘VISC’ architecture, which splits the workload of a single linear thread across multiple cores, are intriguing and exciting. But as with any new fundamental change in computer processing, subject to a large barrage of questions. We were invited to a presentation and call with the President and Chief Technical Officer Mohammed Abdallah and the VP Marketing and Business Mark Casey, and I put a number of questions on the lips of analysts to them.
Identifying Single Thread Performance Bottlenecks
Any discussion about processor performance over the last couple of decades has involved several factors, including getting better performance through an increased power budget, a higher frequency, extracting instruction level parallelism (ILP), getting better at minimizing delays through better branch prediction, or adding more cores and improving thread level parallelism (TLP). Each of these methods have varying degrees of success at increasing performance – long-time readers will remember the Pentium 4 days of hitting a frequency and power wall which then switched the focus to efficiency. Some tasks, like graphics, are inherently parallel and can take advantage of multiple hundreds or thousands of cores, or the software can be optimized. However, the nature of most software code and instructions is that they are single threaded by nature, and their performance relies on how fast the instructions can be processed within a single thread.
The main way of increasing performance, or in this case the instructions per unit frequency (instructions per clock, or IPC), is to expand the CPU architecture to allow more commands to be processed at once. Moving from a 3-wide out-of-order architecture to a 5-wide out-of-order architecture theoretically allows for a 66% increase in instruction throughput if (and only if) the code is sufficiently dense enough to extract those operations, and the other features in the architecture can ensure all the operations are fed every clock cycle.
The problem with moving to a wider architecture is typically power and design complexity. As shown by various chip designs over the years, the wider the architecture the more silicon has to be set aside for assets like buffers, re-order windows and caching. If there is a silicon budget and enough power headroom, we see designs like the six-wide Intel Skylake cores or the seven wide NVIDIA Denver cores able to extract peak performance when code is written that matches the hardware. However the potential downside of a wide architecture is that it remains inefficient for sets of instructions that only need a 2-wide or a 3-wide architecture. Alternatively, if multiple programs or threads want to use the hardware, then a single core is inaccessible to additional threads while the first thread is still in use (though this can be avoided somewhat by simultaneous multithreading or SMT which will let another thread have access when the first has encountered a stall such as waiting for L1/L2 memory).
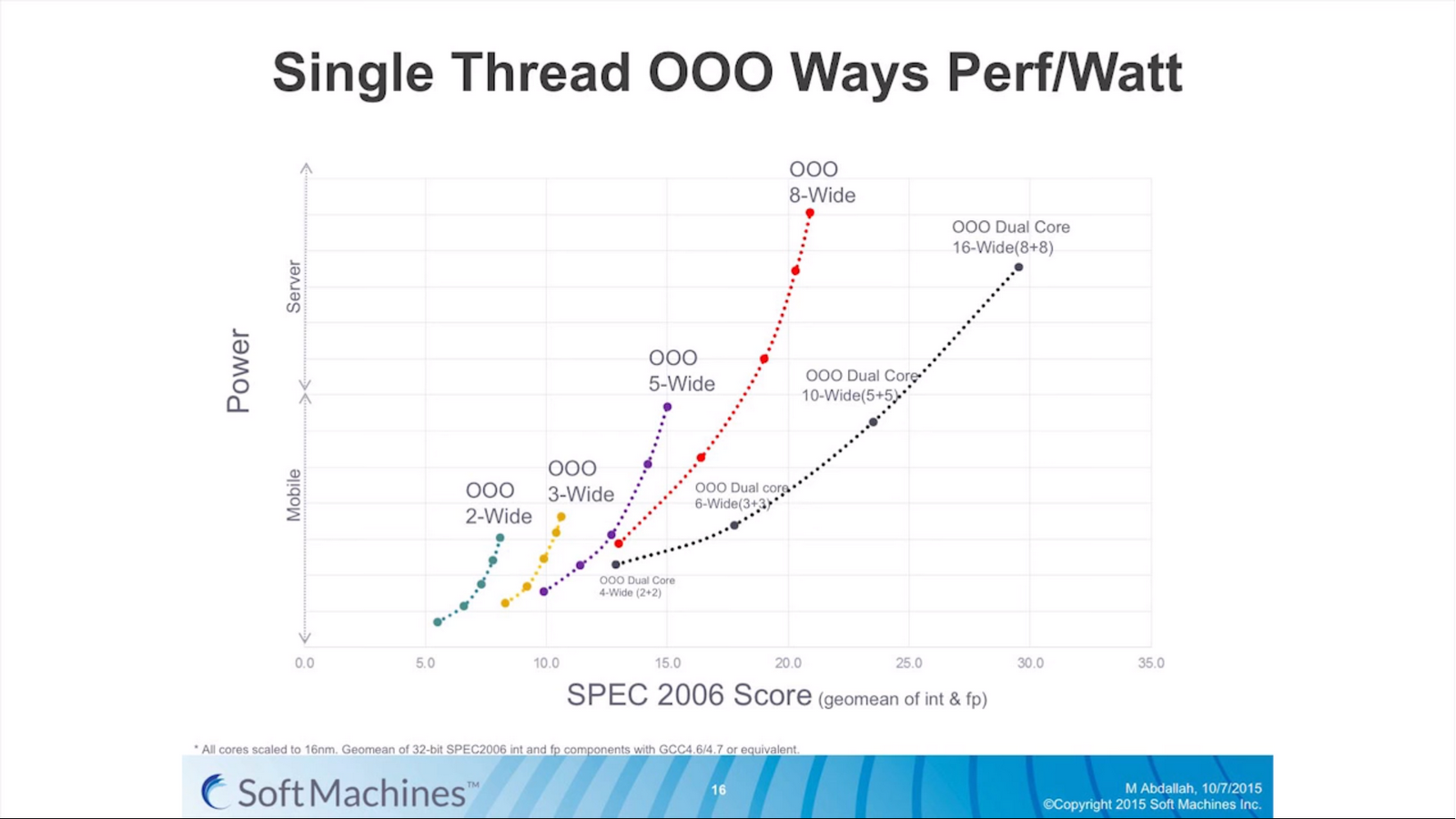
As a result, modern designs also include a number of cores to handle the multile thread/multiple program scenario. Generally speaking this works well, especially with high-performance cores, but it becomes a bit of an issue itself when much of the world’s hardware is actually composed of many cores that have poor single threaded performance. Older Core 2 / Conroe systems, basic Bulldozer, or ARM Cortex-A7 designs are (still) widely used and often ship with multiple cores to allow for multiple programs at once. And while they can scale up with additional threads to the number of cores they offer, if any single or lightly-threaded software needs more performance, those extra cores are not used or are only minimally beneficial overall.
This brings us to Soft Machines, whose VISC architecture aims to change this.
Meet VISC
I should start by saying that despite the similarities to other architectural names, VISC is not an acronym. I asked directly and it is merely a noun for the purposes of trademarking. People can interpret it as a ‘virtual instruction set computing’ or something similar, but the company doesn’t apply any acronym to the letters.
But a virtual instruction set is a good description here. For the most part, processor architectures were traditionally built around either CISC (complex) or RISC (reduced) instruction sets and execution models, while more modern designs (e.g. Intel Core) are increasingly a mix, or so-called ‘CRISC’ design. The difference between CISC and RISC boils down to the fact that simpler designs can be more power efficient, but complex designs can do more complicated things in fewer cycles, all the while CRISC essentially meets the two paradigms in the middle in an attempt to gain the benefits of both, though not without inheriting some of the drawbacks as well. VISC, for lack of a better description, is a RISC design using a custom instruction set over a translation layer which allows a single thread of operations to be dispatched over multiple physical cores. The base diagram looks something like this:
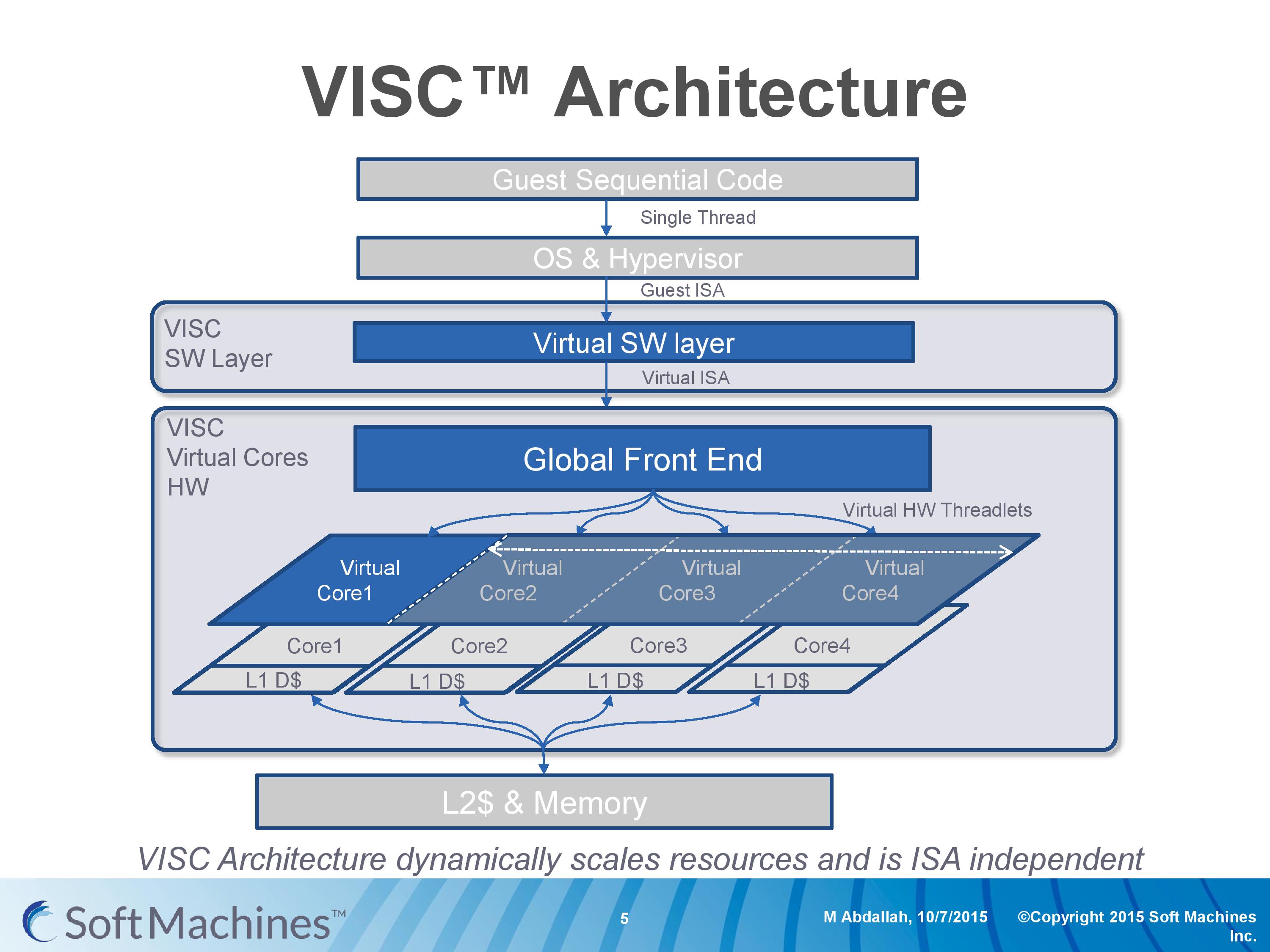
Here is an example of a VISC design with four physical cores. The design can handle four ‘virtual cores’ or threads as well, but what makes the VISC design different is that when the virtual core has a thread of instructions, it can use the resources of any physical core. Thus, if each physical core is a 4-wide out-of-order design, if a thread running on a virtual core can utilize the resources of all four cores essentially making a giant 16-wide design, then under VISC can do so.
This should instantly throw up a number of questions on ‘What!? How?! Why?! Power? Frequency? Performance? Efficiency? Complexity?’ and as well as many others in the industry, we had the same questions.








97 Comments
View All Comments
vladx - Sunday, February 14, 2016 - link
If it works, Intel or ARM won't be abke to copy them because they've already patented the techniques used.vladx - Sunday, February 14, 2016 - link
*able tovalinor89 - Saturday, February 13, 2016 - link
AMD, Samsung and Globalfoundries are chief investors so it is doubtful Intel or Nvidia will be able to aquire this company.xthetenth - Friday, February 12, 2016 - link
Why is that such a red flag? They show the optimal part of the curve for A72, and they show the suboptimal tail for all of them, although they extend it farther for the A72 to show what it takes to get it up to the same performance level (basically it's non-viable and that they're in a different class if accurate), and they say as much. There's a huge list of objections the article raises and that isn't on it for pretty good reason. It's just not nearly as big a deal as the rest.Andrei Frumusanu - Friday, February 12, 2016 - link
It's incorrect to simply extend a curve of an existing design beyond its design operating range. It's perfectly possible to design the physical implementation to be optimized at very high frequencies - in such a case the curve would less steep but consume higher power at the low frequencies. Extending the curve of a low-power design is relatively misleading in this case.extide - Friday, February 12, 2016 - link
Yeah, and I don't think they should adjust the Intel cores at all. Intel chips come as Intel makes them, that's it. You will never see the skylake arch on TSMC or GF foundry processes. You should take the results from the Intel chip as they are because that is what you will be competing against, not some made up adjusted result that will never exist in the wild.As for adjusting the OTHER chips, well, ok I see what they are going at here, but I still think they took it a bit too far, like adjusting for more or less cache. Although you can see those other chips on various processes, form GF and TSMC, so the process correction isn't really as big of a red flag to me.
name99 - Saturday, February 13, 2016 - link
The curve is not illegitimate because you're missing the point. The goal of the curve is not to show how great their CPU is, it is to show how great their TECHNOLOGY is (ie their microarchitecture). This is best done by comparisons that hold all else equal (ie same process, same compiler, same caches, etc; only different microarchitecture).If you're going to criticize the presentation, criticize it on grounds that actually make sense:
- their "performance" score is garbage because they claim to be in the business of speeding up SINGLE-THREADED code, but then mix in a number of benchmarks that are very naturally parallelized. This is much like comparing an ARMv8 CPU with NEON switched off to an x86 using AVX-512, to test matrix multiplication speed --- it's simply NOT telling you anything about single-threaded performance.
- the robustness of their normalizations is dodgy and they provide little evidence that the ways in which they have normalized are legit.
gamerk2 - Friday, February 12, 2016 - link
This is where CPUs are eventually going to go, since it's really the only way to get maximized CPU performance without adding a lot of power-hungry components onto the die.That being said, the likely outcome is someone (Intel most likely, possibly NVIDIA) acquires Soft Machines and integrates their IP onto their own chips.
vladx - Sunday, February 14, 2016 - link
Doubt it, the only chance for NVidia would be to license it and Intel would most likely be blocked from nuying such a company.Avendit - Friday, February 12, 2016 - link
How doe this all compare to the Transmetta/Crusoe parts? That had a different purpose but did have the translation abstraction layer approach, but didn't seem to go anywhere unfortunetly. Are there any parallels or learnings to be had?