Upgrading from an Intel Core i7-2600K: Testing Sandy Bridge in 2019
by Ian Cutress on May 10, 2019 10:30 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
- Overclocking
- 7700K
- Coffee Lake
- i7-2600K
- 9700K
Sandy Bridge: Outside the Core
With the growth of multi-core processors, managing how data flows between the cores and memory has been an important topic of late. We have seen a variety of different ways to move the data around a CPU, such as crossbars, rings, meshes, and in the future, completely separate central IO chips. The battle of the next decade (2020+), as mentioned previously here on AnandTech, is going to the battle of the interconnect, and how it develops moving forward.
What makes Sandy Bridge special in this instance is that it was the first consumer CPU from Intel to use a ring bus that connects all the cores, the memory, the last level cache, and the integrated graphics. This is still a similar design to the eight core Coffee Lake parts we see today.
The Ring Bus
With Nehalem/Westmere all of the cores had their own private path to the last level (L3) cache. That’s roughly 1000 wires per core, and more wires consume more power as well as being more difficult to implement the more you have. The problem with this approach is that it doesn’t work well as you scale up in things that need access to the L3 cache.
As Sandy Bridge adds a GPU and video transcoding engine on-die that share the L3 cache, rather than laying out more wires to the L3, Intel introduced a ring bus.
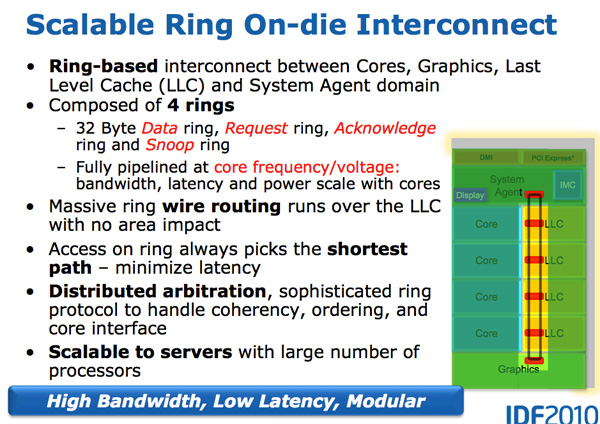
Architecturally, this is the same ring bus used in Nehalem EX and Westmere EX. Each core, each slice of L3 (LLC) cache, the on-die GPU, media engine and the system agent (fancy word for North Bridge) all have a stop on the ring bus. The bus is made up of four independent rings: a data ring, request ring, acknowledge ring and snoop ring. Each stop for each ring can accept 32-bytes of data per clock. As you increase core count and cache size, your cache bandwidth increases accordingly.
Per core you get the same amount of L3 cache bandwidth as in high end Westmere parts - 96GB/s. Aggregate bandwidth is 4x that in a quad-core system since you get a ring stop per core (384GB/s).
This means that L3 latency is significantly reduced from around 36 cycles in Westmere to 26 - 31 cycles in Sandy Bridge, with some variable cache latency as it depends on what core is accessing what slice of cache. Also unlike Westmere, the L3 cache now runs at the core clock speed - the concept of the un-core still exists but Intel calls it the “system agent” instead and it no longer includes the L3 cache. (The term ‘un-core’ is still in use today to describe interconnects.)
With the L3 cache running at the core clock you get the benefit of a much faster cache. The downside is the L3 underclocks itself in tandem with the processor cores as turbo and idle modes come into play. If the GPU needs the L3 while the CPUs are downclocked, the L3 cache won’t be running as fast as it could had it been independent, or the system has to power on the core and consume extra power.
The L3 cache is divided into slices, one associated with each core. As Sandy Bridge has a fully accessible L3 cache, each core can address the entire cache. Each slice gets its own stop and each slice has a full cache pipeline. In Westmere there was a single cache pipeline and queue that all cores forwarded requests to, but in Sandy Bridge it’s distributed per cache slice. The use of ring wire routing means that there is no big die area impact as more stops are added to the ring. Despite each of the consumers/producers on the ring get their own stop, the ring always takes the shortest path. Bus arbitration is distributed on the ring, each stop knows if there’s an empty slot on the ring one clock before.
The System Agent
For some reason Intel stopped using the term un-core in SB, and for Sandy Bridge it’s called the System Agent. (Again, un-core is now back in vogue for interconnects, IO, and memory controllers). The System Agent houses the traditional North Bridge. You get 16 PCIe 2.0 lanes that can be split into two x8s. There’s a redesigned dual-channel DDR3 memory controller that finally restores memory latency to around Lynnfield levels (Clarkdale moved the memory controller off the CPU die and onto the GPU).
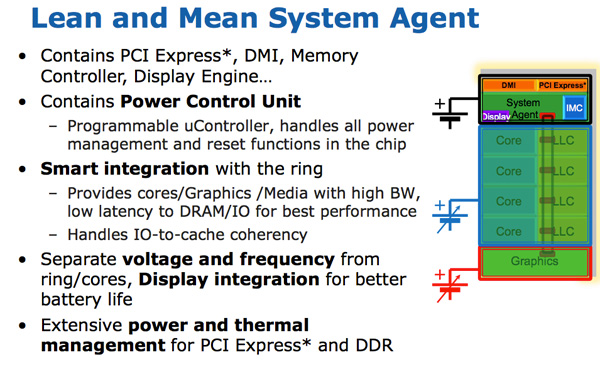
The SA also has the DMI interface, display engine and the PCU (Power Control Unit). The SA clock speed is lower than the rest of the core and it is on its own power plane.
Sandy Bridge Graphics
Another large performance improvement on Sandy Bridge vs. Westmere is in the graphics. While the CPU cores show a 10 - 30% improvement in performance, Sandy Bridge graphics performance is easily double what Intel delivered with pre-Westmere (Clarkdale/Arrandale). Despite the jump from 45nm to 32nm, SNB graphics improves through a significant increase in IPC.
The Sandy Bridge GPU is on-die built out of the same 32nm transistors as the CPU cores. The GPU is on its own power island and clock domain. The GPU can be powered down or clocked up independently of the CPU. Graphics turbo is available on both desktop and mobile parts, and you get more graphics turbo on Sandy Bridge.
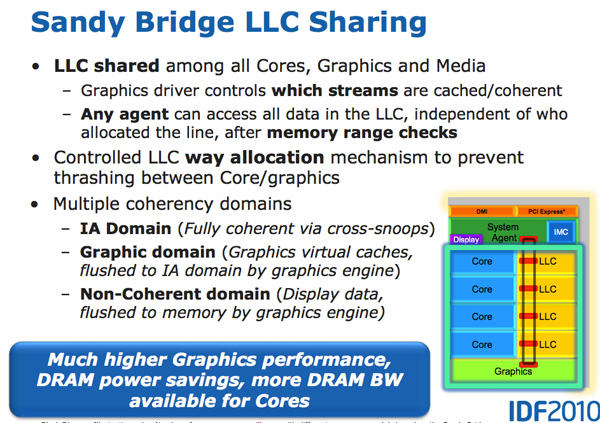
The GPU is treated like an equal citizen in the Sandy Bridge world, it gets equal access to the L3 cache. The graphics driver controls what gets into the L3 cache and you can even limit how much cache the GPU is able to use. Storing graphics data in the cache is particularly important as it saves trips to main memory which are costly from both a performance and power standpoint. Redesigning a GPU to make use of a cache isn’t a simple task.
SNB graphics (internally referred to as Gen 6 graphics) makes extensive use of fixed function hardware. The design mentality was anything that could be described by a fixed function should be implemented in fixed function hardware. The benefit is performance/power/die area efficiency, at the expense of flexibility.
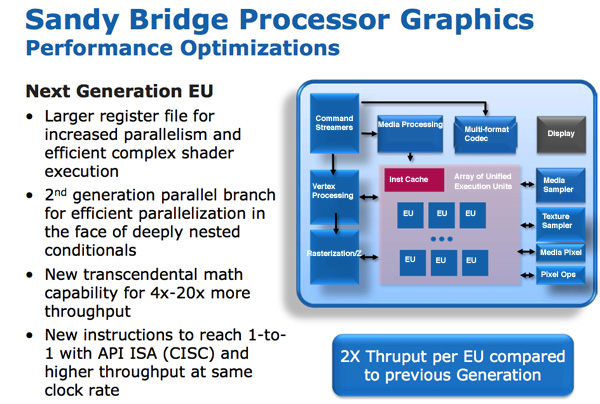
The programmable shader hardware is composed of shaders/cores/execution units that Intel calls EUs. Each EU can dual issue picking instructions from multiple threads. The internal ISA maps one-to-one with most DirectX 10 API instructions resulting in a very CISC-like architecture. Moving to one-to-one API to instruction mapping increases IPC by effectively increasing the width of the EUs.
There are other improvements within the EU. Transcendental math is handled by hardware in the EU and its performance has been sped up considerably. Intel told us that sine and cosine operations are several orders of magnitude faster now than they were in pre-Westmere graphics.
In previous Intel graphics architectures, the register file was repartitioned on the fly. If a thread needed fewer registers, the remaining registers could be allocated to another thread. While this was a great approach for saving die area, it proved to be a limiter for performance. In many cases threads couldn’t be worked on as there were no registers available for use. Intel moved from 64 to 80 registers per thread and finally to 120 for Sandy Bridge. The register count limiting thread count scenarios were alleviated.
At the time, all of these enhancements resulted in 2x the instruction throughput per EU.

Sandy Bridge vs. NVIDIA GeForce 310M Playing Starcraft 2
At launch there were two versions of Sandy Bridge graphics: one with 6 EUs and one with 12 EUs. All mobile parts (at launch) will use 12 EUs, while desktop SKUs may either use 6 or 12 depending on the model. Sandy Bridge was a step in the right direction for Intel, where integrated graphics were starting to become a requirement in anything consumer related, and Intel would slowly start to push the percentage of die area dedicated to GPU. Modern day equivalent desktop processors (2019) have 24 EUs (Gen 9.5), while future 10nm CPUs will have ~64 EUs (Gen11).
Sandy Bridge Media Engine
Sitting alongside the GPU is Sandy Bridge’s Media processor. Media processing in SNB is composed of two major components: video decode, and video encode.
The hardware accelerated decode engine is improved from the current generation: the entire video pipeline is now decoded via fixed function units. This is contrast to Intel’s pre-SNB design that uses the EU array for some video decode stages. As a result, Intel claims that SNB processor power is cut in half for HD video playback.
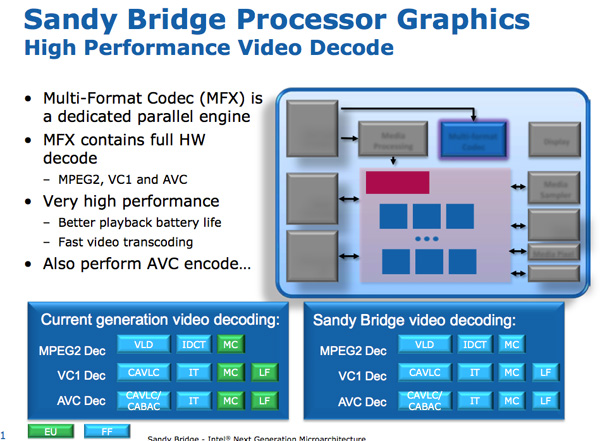
The video encode engine was a brand new addition to Sandy Bridge. Intel took a ~3 minute 1080p 30Mbps source video and transcoded it to a 640 x 360 iPhone video format. The total process took 14 seconds and completed at a rate of roughly 400 frames per second.
The fixed function encode/decode mentality is now pervasive in any graphics hardware for desktops and even smartphones. At the time, Sandy Bridge was using 3mm2 of the die for this basic encode/decode structure.
New, More Aggressive Turbo
Lynnfield was the first Intel CPU to aggressively pursue the idea of dynamically increasing the core clock of active CPU cores while powering down idle cores. The idea is that if you have a 95W TDP for a quad-core CPU, but three of those four cores are idle, then you can increase the clock speed of the one active core until you hit a turbo limit.
In all current generation processors the assumption is that the CPU reaches a turbo power limit immediately upon enabling turbo. In reality however, the CPU doesn’t heat up immediately - there’s a period of time where the CPU isn’t dissipating its full power consumption - there’s a ramp.
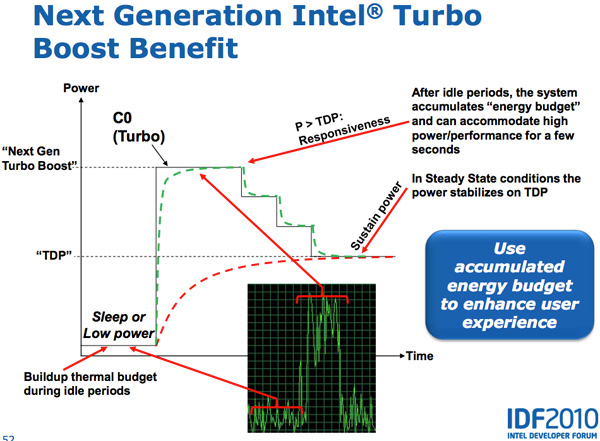
Sandy Bridge takes advantage of this by allowing the PCU to turbo up active cores above TDP for short periods of time (up to 25 seconds). The PCU keeps track of available thermal budget while idle and spends it when CPU demand goes up. The longer the CPU remains idle, the more potential it has to ramp up above TDP later on. When a workload comes around, the CPU can turbo above its TDP and step down as the processor heats up, eventually settling down at its TDP. While SNB can turbo up beyond its TDP, the PCU won’t allow the chip to exceed any reliability limits.
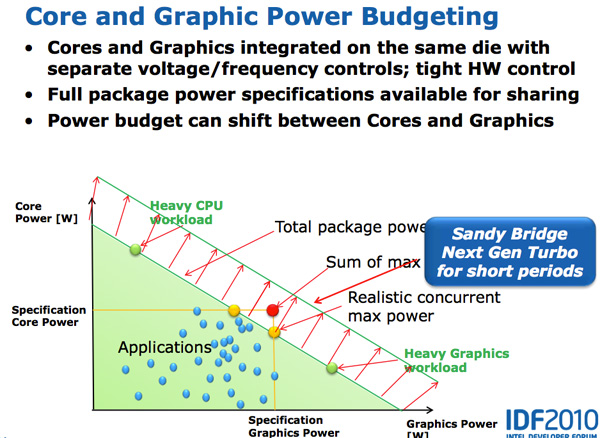
Both CPU and GPU turbo can work in tandem. Workloads that are more GPU bound running on SNB can result in the CPU cores clocking down and the GPU clocking up, while CPU bound tasks can drop the GPU frequency and increase CPU frequency. Sandy Bridge as a whole was a much more dynamic of a beast than anything that’s come before it.








213 Comments
View All Comments
MxClood - Saturday, May 18, 2019 - link
In most test here it's around 100% or more increase in perf, i don't see where it's 40%.Also when you increase the graphics/resolution in gaming, the FPS are the same because the GPU becomes the bottleneck of FPS. You could put any futuristic cpu, the fps would be the same.
So why is it an argument about disappointing/abysmal performance.
Beaver M. - Wednesday, May 22, 2019 - link
After so many decades being wrong you guys still claim CPU power doesnt matter much in games.Youre wrong. Again. Common bottleneck today in games is the CPU, especially because the GPU advancement has been very slow.
Spunjji - Wednesday, May 22, 2019 - link
GPU advancement slowing down *makes the CPU less relevant, not more*. The CPU is only relevant to performance when it can't meet the bare minimum requirements to serve the GPU fast enough. If the GPU is your limit, no amount of CPU power increase will help.LoneWolf15 - Friday, May 17, 2019 - link
Is it abysmal because of the CPU though, or because of the software?Lots of software isn't written to take advantage of more than four cores tops, aside from the heavy hitters, and to an extent, we've hit a celing with clock speeds for awhile, with 5GHz being (not exactly, but a fair representation of) the ceiling.
AMD has caught up in a big way, and for server apps and rendering, it's an awesome value and a great CPU. Even with that, it still doesn't match up with a 9700K in games, all other things being equal, unless a game is dependent on GPU alone.
I think most mainstream software isn't optimized beyond a certain point for any of our current great CPUs, largely because until recently, CPU development and growth has stagnated. I'm really hoping real competition drives improved software.
Note also that it hasn't been like the 90s in some time, where we were doubling CPU performance every 16 months. Some of that is because there's too many limitations to achieving that doubling, both software and hardware.
I'm finding considerable speed boosts over my i7-4790K that was running at 4.4GHz (going to an i9-9900K running constantly at 4.7GHz on all cores) in regular apps and gaming (at 1900x1200 with two GTX 1070 cards in SLI), and I got a deal on the CPU, so I'm perfectly happy with my first mainboard/CPU upgrade in five years (my first board was a 386DX back in `93).
peevee - Tuesday, May 14, 2019 - link
Same here. i7-2600k from may 2011, with the same OCZ Vertex 3.8 years, twice the cores, not even twice the performance in real world. Just essentially overclocked to the max from the factory.
Remember when real life performance more than doubled every 2 years? On the same 1 core, in all apps, not just heavily multithreaded? Good thing AMD at least forced Intel go from 4 to 6 to 8 in 2 years. Now they need to double their memory controllers, it's the same 128 bits since what, Pentium Pro?
Mr Perfect - Friday, May 10, 2019 - link
Same here. Over the years I've stuffed it full of RAM and SSD and been pleased with the performance. I'm thinking it's time for it to go though.In 2016 I put a 1060 in the machine and was mildly disappointed in the random framerate drops in games (at 1200p). Assuming it was the GPU's fault, I upgraded further in 2018 to a 1070 Ti some bitcoin miner was selling for cheap when the market crashed. The average framerates went up, but all of the lows are just as low as they ever where. So either Fallout 4 runs like absolute garbage in certain areas, or the CPU was choking up both GPUs.
When something that isn't PCIe 3 comes out I suppose I can try again and see.
ImOnMy116 - Friday, May 10, 2019 - link
For whatever it's worth, in my experience Fallout 4 (and Skyrim/Skyrim SE/maybe all Bethesda titles) are poorly optimized. It seems their engine is highly dependent on IPC, but even in spite of running an overclocked 6700K/1080 Ti, I get frame drops in certain parts of the map. I think it's likely at least partially dependent on where your character is facing at any given point in time. There can be long draw distances or lots of NPCs near by taxing the CPU (i.e. Diamond City).Mr Perfect - Friday, May 10, 2019 - link
Yeah, that makes sense. F4's drops are definitely depended on location and where the character is facing for me too.The country side, building interiors and winding city streets you can't see very far down are just fine. Even Diamond City is okay. It's when I stand at an intersection of one of the roads that runs arrow straight through Boston or get up on rooftops with a view over the city that rates die. If the engine wants pure CPU grunt for that, then the 2600 just isn't up to it.
Strangely, Skyrim SE has been fine. The world is pretty sparse compared to F4 though.
Vayra - Monday, May 13, 2019 - link
Fallout 4 is simply a game of asset overload. That happens especially in the urban areas. It shows us that the engine is past expiry date and unable to keep up to the game's demands of this time. The game needs all those assets to at least look somewhat bearable. And its not efficient about it at all; a big part of all those little items also need to be fully interactive objects.So its not 'strange' at all, really. More objects = more cpu load and none of them can be 'cooked' beforehand. They are literally placed in the world as you move around in it.
Vayra - Monday, May 13, 2019 - link
This is also part of the reason why the engine has trouble with anything over 60 fps, and why you can sometimes see objects falling from the sky as you zone in.