Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
by Andrei Frumusanu on May 27, 2019 12:01 AM ESTThe Cortex-A77 µarch: Added ALUs & Better Load/Stores
Having covered the front-end and middle-core, we move onto the back-end of the Cortex-A77 and investigate what kind of changes Arm has made to the execution units and data pipelines.
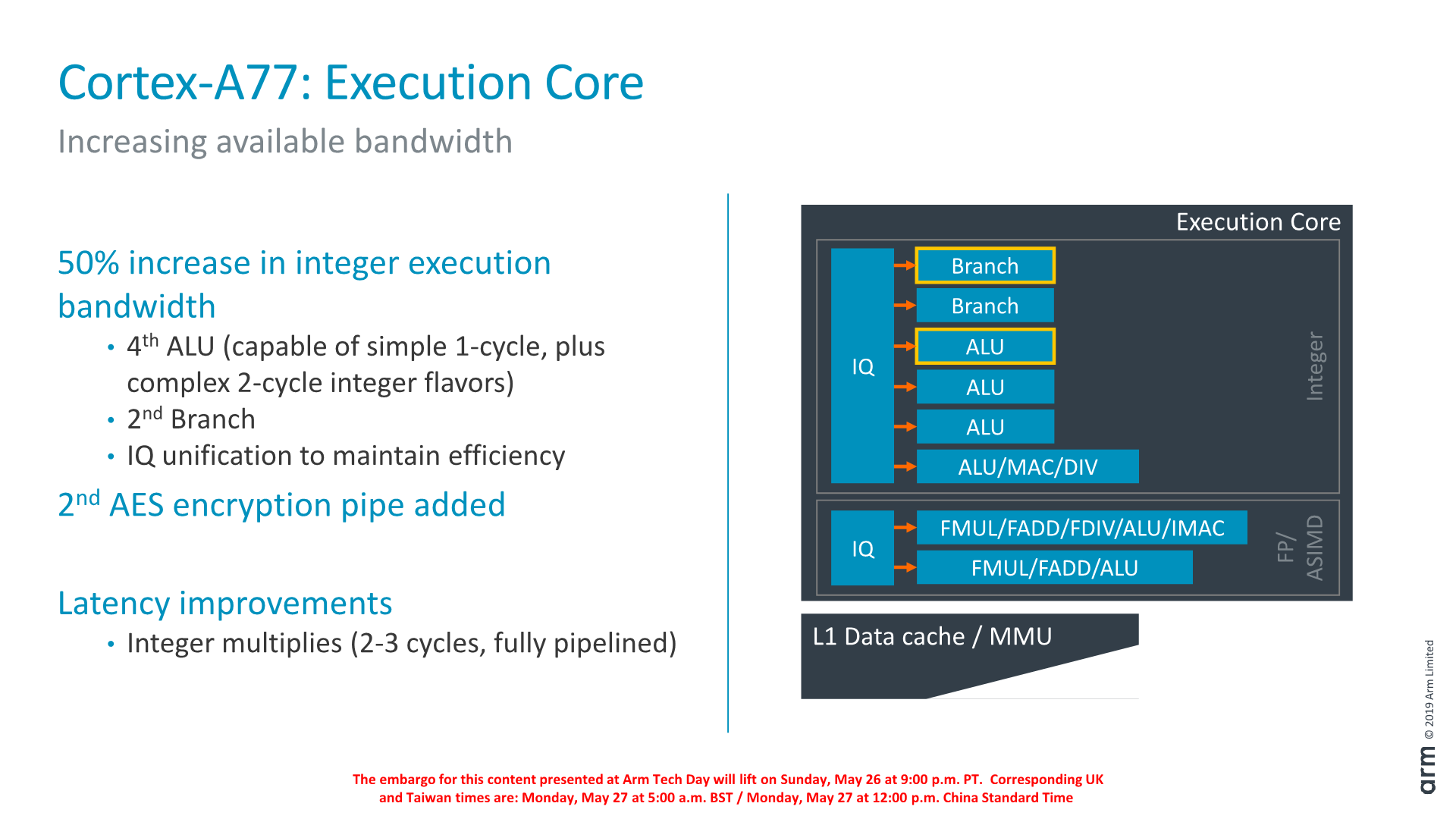
On the integer execution side of the core we’ve seen the addition of a second branch port, which goes along with the doubling of the branch-predictor bandwidth of the front-end.
We also see the addition on an additional integer ALU. This new unit goes half-way between a simple single-cycle ALU and the existing complex ALU pipeline: It naturally still has the ability of single-cycle ALU operations but also is able to support the more complex 2-cycle operations (Some shift combination instructions, logical instructions, move instructions, test/compare instructions). Arm says that the addition of this new pipeline saw a surprising amount of performance uplift: As the core gets wider, the back-end can become a bottleneck and this was a case of the execution units needing to grow along with the rest of the core.
A larger change in the execution core was the unification of the issue queues. Arm explains that this was done in order to maintain efficiency of the core with the added execution ports.
Finally, existing execution pipelines haven’t seen much changes. One latency improvement was the pipelining of the integer multiply unit on the complex ALU which allows it to achieve 2-3 cycle multiplications as opposed to 4.
Oddly enough, Arm didn’t make much mention of the floating-point / ASIMD pipelines for the Cortex-A77. Here it seems the A76’s “state-of-the-art” design was good enough for them to focus the efforts elsewhere on the core for this generation.

On the part of the load/store units, we still find two units, however Arm has added two additional dedicated store ports to the units, which in effect doubles the issue bandwidth. In effect this means the L/S units are 4-wide with 2 address generation µOps and 2 store data µOps.
The issue queues themselves again have been unified and Arm has increased the capacity by 25% in order to expose more memory-level parallelism.

Data prefetching is incredibly important in order to hide memory latency of a system: Shaving off cycles by avoiding to having to wait for data can be a big performance boost. I tried to cover the Cortex-A76’s new prefetchers and contrast it against other CPUs in the industry in our review of the Galaxy S10. What stood out for Arm is that the A76’s new prefetchers were outstandingly performant and were able to deal with some very complex patterns. In fact the A76 did far better than any other tested microarchitecture, which is quite a feat.
For the A77, Arm improved the prefetchers and added in even new additional prefetching engines to improve this even further. Arm is quite tight-lipped about the details here, but we’re promised increased pattern coverages and better prefetching accuracy. One such change is claimed to be “increased maximum distance”, which means the prefetchers will recognize repeated access patterns over larger virtual memory distances.
One new functional addition in the A77 is so called “system-aware prefetching”. Here Arm is trying to solve the issue of having to use a single IP in loads of different systems; some systems might have better or worse memory characteristics such as latency than others. In order to deal with this variance between memory subsystems, the new prefetchers will change the behaviour and aggressiveness based on how the current system is behaving.
A thought of mine would be that this could signify some interesting performance improvements under some DVFS conditions – where the prefetchers will alter their behaviour based on the current memory frequency.
Another aspect of this new system-awareness is more knowledge of the cache pressure of the DSU’s L3 cache. In case that other CPU cores would be highly active, the core’s prefetchers would see this and scale down its aggressiveness in order to possibly avoid thrashing the shared cache needlessly, increasing overall system performance.








108 Comments
View All Comments
Raqia - Tuesday, May 28, 2019 - link
Another interesting development in the big AX CPUs is that they've moved from a more complex cache hierarchy in the A10 to a 2 level hierarchy with a much bigger L2 since the A11 that had better bandwidth and latency; L1's were also further boosted in size and bandwidth in the A12. This likely accounts for the continuation of growth in single threaded benchmark scores but seems to indicate that the CPU complex is oriented toward client type workloads.ARM has gone full steam ahead with more multi-processing oriented cache designs with some SoCs sporting a further layer of L4 cache and server designs sporting sophisticated un-cores. Their ambitions seem rather different than Apple's and this year's A77's will likely be implemented into servers designs sometime soon.
Apple's 3-wide OoOE little cores continue to be even more impressive than their big cores, and hold their own against the A73 in performance with much higher efficiency. One wonders if the 2-wide A73 or even the A75 could be tweaked and underclocked to be the "little" in future designs. It certainly fits the bill in terms of die area.
peevee - Tuesday, May 28, 2019 - link
"The results is that the Kirin 980 as well as the Snapdragon 855 both represented major jumps over their predecessors. Qualcomm has proclaimed a 45% leap in CPU performance compared to the previous generation Snapdragon 855 with Cortex-A76 cores, the biggest generational leap ever."Wat?
peevee - Tuesday, May 28, 2019 - link
"In the A77’s case the structure is 1.5K entries big, which if one would assume macro-ops having a similar 32-bit density as Arm instructions, would equate to about 48KB."You mean Kb, right? And of course this assumption is nonsense.
peevee - Tuesday, May 28, 2019 - link
"web-browsing is the killer-app that happens to be floating point heavy"Why? Because ECMAScript has just one number type?
I suspect WebAssembly would eliminate this problem.
ballsystemlord - Tuesday, May 28, 2019 - link
Spelling and grammar corrections:"Having less capacity would take reduce the hit-rate more significantly, while going for a larger cache would have diminishing returns."
Extra word "take":
"Having less capacity would reduce the hit-rate more significantly, while going for a larger cache would have diminishing returns."
"...and again this imbalance with a more "fat" front-end bandwidth allows the core to hide to quickly hide branch bubbles and pipeline flushes."
More extra words "to hide":
"...and again this imbalance with a more "fat" front-end bandwidth allows the core to quickly hide branch bubbles and pipeline flushes."
sireangelus - Tuesday, May 28, 2019 - link
Are there any news or rumors regarding the succesor of the cortex a55? not even just working on reducing power consumption?tuxRoller - Tuesday, May 28, 2019 - link
"The combination of the brand-new microarchitecture alongside the major improvements that the 7nm TSMC process node has brought some of the biggest performance and efficiency jumps we’ve ever seen in the industry."Or, to paraphrase many a cynical AT commenter: same old incremental improvement, nothing exciting... where's my mr fusion?!!!
AshlayW - Tuesday, May 28, 2019 - link
Can someone tell me how this stacks up to a high-performance X86 core, like Zen or Skylake please? If ARM is so powerful and efficient why are they not developing Desktop CPUs? Is it just because the software ecosystem is dominated by proprietary X86?Wilco1 - Wednesday, May 29, 2019 - link
The IPC is higher than the latest x86 cores. There are Arm server CPUs which are competitive with Skylake and beat it on HPC applications in super computers. Currently you can buy desktops based on ThunderX2 and Ampere, see https://store.avantek.co.uk/arm-desktops.html .Farfolomew - Thursday, June 6, 2019 - link
I wish this were talked about more. As awesome as Zen2 is, and as cool as the story is regarding AMD finally getting on level playing field with Intel again (ie, circa 2004), in the back of my mind I find it a bit silly when all the while that's been happening, a better architecture in all regards has managed to catch up and pass x86. That should be where the computing industry focus is, and how Intel+AMD is planning on battling that threat.