AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Fetch/Prefetch
Starting with the front end of the processor, the prefetchers.
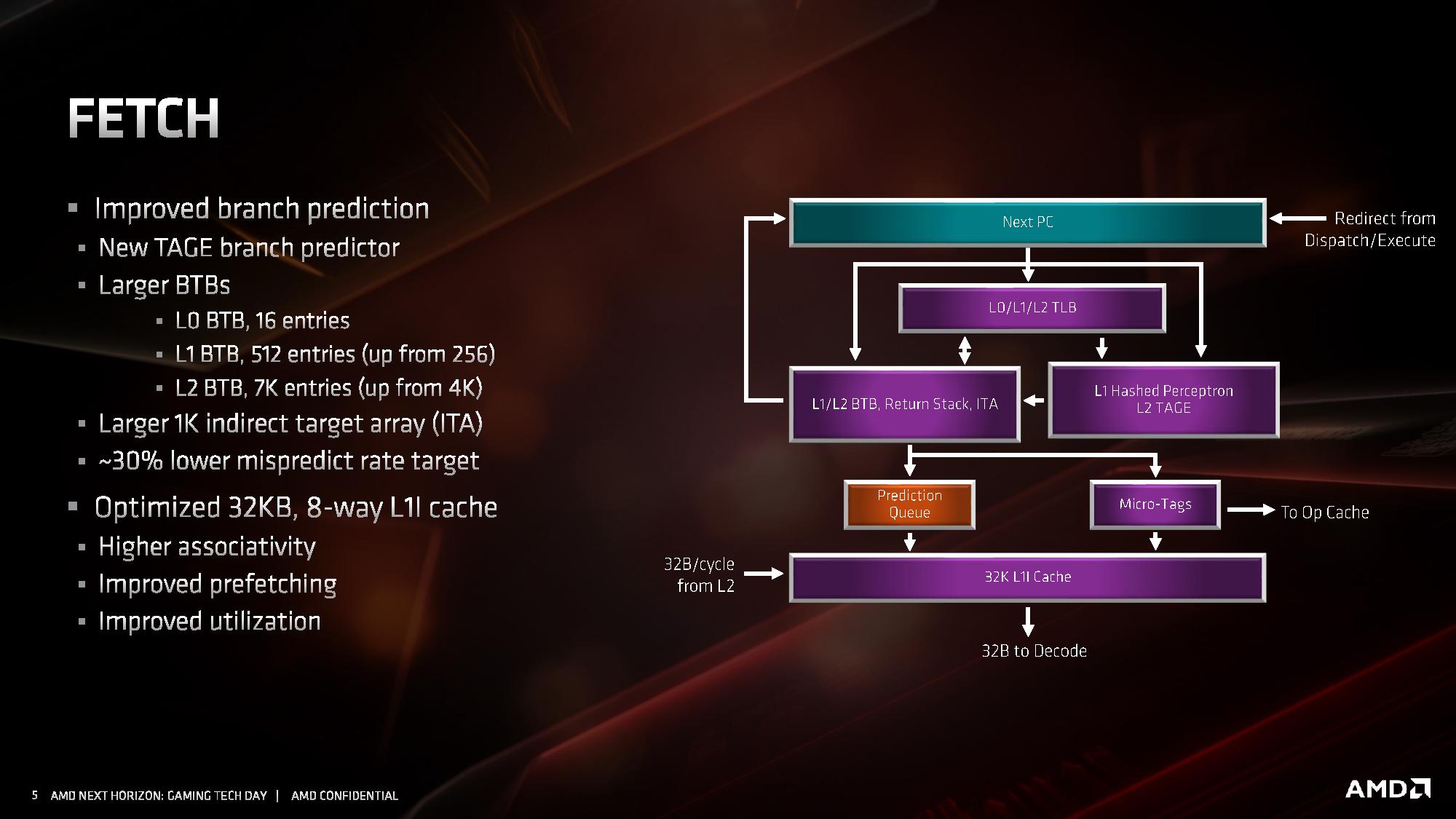
AMD’s primary advertised improvement here is the use of a TAGE predictor, although it is only used for non-L1 fetches. This might not sound too impressive: AMD is still using a hashed perceptron prefetch engine for L1 fetches, which is going to be as many fetches as possible, but the TAGE L2 branch predictor uses additional tagging to enable longer branch histories for better prediction pathways. This becomes more important for the L2 prefetches and beyond, with the hashed perceptron preferred for short prefetches in the L1 based on power.
In the front end we also get larger BTBs, to help keep track of instruction branches and cache requests. The L1 BTB has doubled in size from 256 entry to 512 entry, and the L2 is almost doubled to 7K from 4K. The L0 BTB stays at 16 entries, but the Indirect target array goes up to 1K entries. Overall, these changes according to AMD affords a 30% lower mispredict rate, saving power.
One other major change is the L1 instruction cache. We noted that it is smaller for Zen 2: only 32 KB rather than 64 KB, however the associativity has doubled, from 4-way to 8-way. Given the way a cache works, these two effects ultimately don’t cancel each other out, however the 32 KB L1-I cache should be more power efficient, and experience higher utilization. The L1-I cache hasn’t just decreased in isolation – one of the benefits of reducing the size of the I-cache is that it has allowed AMD to double the size of the micro-op cache. These two structures are next to each other inside the core, and so even at 7nm we have an instance of space limitations causing a trade-off between structures within a core. AMD stated that this configuration, the smaller L1 with the larger micro-op cache, ended up being better in more of the scenarios it tested.








216 Comments
View All Comments
Smell This - Sunday, June 16, 2019 - link
AND ...
it might be 12- to 16 IF links or, another substrate ?
Targon - Thursday, June 13, 2019 - link
Epyc and Ryzen CCX units are TSMC, the true CPU cores. The I/O unit is the only part that comes from Global Foundries, and is probably at TSMC just to satisfy the contracts currently in place.YukaKun - Monday, June 10, 2019 - link
"Users focused on performance will love the new 16-core Ryzen 9 3950X, while the processor seems nice an efficient at 65W, so it will be interesting so see what happens at lower power."Shouldn't that be 105W?
And great read as usual.
Cheers!
jjj - Monday, June 10, 2019 - link
The big problem with this platform is that ST perf per dollar gains are from zero to minimal, depending on SKU.They give us around 20% ST gains (IPC+clocks) but at a cost. Would rather have 10-15% gains for free than to pay for 20%. Pretty much all SKUs need a price drop to become exciting, some about 50$, some a bit less and the 16 cores a lot more.
Got to wonder about memory BW with the 16 cores. 2 channels with 8 cores is one thing but at 16 cores, it might become a limiting factor here and there.
Threska - Tuesday, June 11, 2019 - link
That could be said of any processor. "Yeah, drop the price of whatever it is and we'll love you for it." Improvements cost, just like DVD's costed more than VHS.jjj - Tuesday, June 11, 2019 - link
In the semi business the entire point is to offer significantly more perf per dollar every year. That's what Moore's Law was, 2x the perf at same price every 2 years. Now progress is slower but consumers aren't getting anything anymore.And in pretty much all tech driven areas, products become better every year, even cars. When there is no innovation, it means that the market is dysfunctional. AMD certainly does not innovate here, except on the balance sheet. Innovation means that you get better value and that is missing here. TSMC gives them more perf per dollar, they have additional gains from packaging but those gains do not trickle down to us. At the end of the day even Intel tries to offer 10-15% perf per dollar gains every cycle.
AlyxSharkBite - Tuesday, June 11, 2019 - link
That’s not Moore’s Law at all. It stated that the number of transistors would double. Also it’s been dead a whileSandy bridge 4c 1.16b
Coffee lake 4c is 2.1b (can’t compare the 6c or 8c)
And that’s a lot more than 2 years.
mode_13h - Tuesday, June 11, 2019 - link
Yeah, but those two chips occupy different market segments. So, you should compare Sandybridge i7 vs. Coffelake i7.Teutorix - Tuesday, June 11, 2019 - link
The number of transistors in an IC, not the number of transistors per CPU core. This is an important distinction since a CPU core in Moore's day had very little in it besides registers and an ALU. They didn't integrate FPUs until relatively recently.It's about overall transistor density, nothing more. You absolutely can compare an 8c to a 4c chip, because they are both a single IC.
An 8 core coffee lake chip is 20% smaller than a quad core sandy bridge chip. That's double the CPU cores, double the GPU cores, with probably a massive increase in the transistors/core also.
Moore's law had a minor slowdown with intel stuck at 14nm but its not dead.
Wilco1 - Tuesday, June 11, 2019 - link
Moore's Law is actually accelerating. Just not at Intel. See https://en.wikipedia.org/wiki/Transistor_count - the largest chips now have ~20 Billion transistors, and with 7nm and 5nm it looks like we're getting some more doublings soon.