GPU Cheatsheet - A History of Modern Consumer Graphics Processors
by Jarred Walton on September 6, 2004 12:00 AM EST- Posted in
- GPUs
Estimating Die Size
Disclaimer: Although we have close and ready contact with ATI and NVIDIA, the fact remains that some of the more technical issues concerning actual architecture and design are either closely guarded or extremely obscured to the public. Thus we attempt to estimate some die sizes and transistor counts based on information we already know - and some of these estimations are slightly incorrect.
One of the pieces of information a lot of people might like to know is the die size of the various graphics chips. Unfortunately, ATI and NVIDIA are pretty tight-lipped about such information. Sure, you could rip the heatsink off of your graphics card and get a relatively good estimate of the die size, but unless you've got some serious cash flow, this probably isn't the best idea. Of course, some people have done that for at least a few chips, which will be somewhat useful later. Without resorting to empirical methods of measuring, though, how do we estimate the size of a processor?
Before getting into the estimating portions, let's talk about how microprocessors are made, as it is rather important. When a chip is built up, it starts as a simple ingot of silicon cut into wafers on which silicon dioxide is grown. This silicon dioxide is cut away using photolithography in order to expose the silicon in certain parts. Next, polysilicon is laid down and etched, and the exposed silicon is doped (ionized). Finally, another mask is added with smaller connections to the doped areas and the polysilicon, resulting in a layer of transistors, with three contacts for each newly created transistor. After the transistors are built up, metal layers are added to connect them in the fashion required for the chip. These metal layers are not actually transistors but are connections between transistors that form the "logic" of the chip. They are a miniaturized version of the metal wires you can see in a motherboard.
Microprocessors will of course require multiple layers, but the transistors are on the one polysilicon layer. Modern chips typically have between 15 and 20 layers, although we really only talk about the metal layers. In between each set of metal layers is a layer of insulation, so we usually end up with 6 to 9 metal layers. On modern AMD processors, there are 8 metal layers and the polysilicon layer. On Intel processors, there are 6 to 8 metal layers plus the polysilicon layer, depending on the processor: i.e. 6 for Northwood, 7 on Prescott and 8 on most of their server/workstation chips like the Gallatin.
Having more layers isn't necessarily good or bad; it's simply a necessary element. More complex designs require more complex routing, and since two crossing wires cannot touch each, they need to run on separate layers. Potentially, having more metal layers can help to simplify the layout of the transistors and pack them closer together, but it also adds to the cost as there are now more steps in the production, and more layers results in more internal heat. There are trade offs that can be made in many areas of chip production. In AMD's case, where they only have 200 mm wafers compared to the 300 mm wafers that Intel currently uses, adding extra layers in order to shrink the die size and/or increase speeds would probably be a good idea.
Other factors also come into play, however. Certain structures can be packed more densely than others. For example, the standard SRAM cell used in caches consists of six transistors and is one of the smaller structures in use on processors. This means that adding a lot of cache to a chip won't increase the size as quickly as adding other types chip logic. The materials used in the various layers of a chip can also affect the speed at which the chip can run as well as the density of the transistors and routing in the other metal layers. Copper interconnects conduct electricity better than aluminum, for instance, and the Silicon On Insulator (SOI) technology pioneered by IBM can also have an impact on speed and chip size. Many companies are also using low-k dielectric materials, which can help gates to switch faster. All of these technologies add to the cost of the chip, however, so it is not necessarily true that a chip which uses, i.e. low-k dielectric, will be faster and cheaper to produce than a chip without it.
What all this means is that there is no specific way to arrive at an accurate estimate of die size without having in-depth knowledge of the manufacturing technologies, design goals, costs, etc. Such information is usually a closely guarded secret for obvious reasons. You don't want to let your competitors know about your plans and capabilities any sooner than necessary. Anyway, we now have enough background information to move on to estimating die sizes.
If we're talking about 130 nm process technology, how many transistors of that thickness would fit in 1 mm? Easy enough to figure out: 1 mm / .00013 mm = 7692 T/mm (note that .00013 mm = 130 nm). If we're working in two dimensions, we square that value: 59166864 T/mm2 ("transistors" is abbreviated to "T"). This is assuming square or circular transistors, which isn't necessarily the case, but it is close enough. So, does anyone actually think that they can pack transistors that tightly? No? Good, because right now that's a solid sheet of metal. If 59 million T/ mm2 is the maximum, what is a realistic value? To find that out, we need to look at some actual processors.
The current Northwood core has 55 million transistors and is 131 mm2. That equals 419847 T/mm2, assuming uniform distribution. That sounds reasonable, but how does it compare with the theoretical packing of transistors? It's off by a factor of 141! Again, assuming uniform distribution of materials, it means that 11.9 times (the square root of 141) as much empty space is present in each direction as the actual metal of the transistors. Basically, electromagnetic interference (EMI) and other factors force chip designers to keep transistors and traces a certain distance apart. In the case of the P4, that distance is roughly 11.9 times the process technology in both width and depth. (We ignore height, as the insulation layers are several times thicker than this). So, we'll call this value of 11.9 on the Northwood the "Insulation Factor" or "IF" of the design.
We now have a number we can use to derive die size, given transistor counts and process technology:
Die Size = Transistor Count / (1 / ((Process in mm) * IF)^2)
Again, notice that the process size is in millimeters, so that it matches with the standard unit of measurement for die size. Using the Northwood, we can check our results:
Die Size = 55000000 / (1 / ((0.00013) * 11.9)^2)Die Size = 131.6 mm2
So that works, but how do we know what the IF is on different processors? If it were a constant, things would be easy, but it's not. If we have a similar chip, though, the values will hopefully be pretty similar as well. Looking at the Barton core, it has 54.3 million transistors in 101 mm2. That gives it 537624 T/ mm2, which is obviously different than the Northwood, with the end IF being 10.5. Other 130 nm chips have different values as well. Part of the reason may be due to differences in counting the number of transistors. Transistor counts are really a guess, as not all of the transistors within the chip area are used. Materials used and other factors also come into play. To save time, here's a chart of IF values for various processors (based on their estimated transistor counts), with averages for the same process technology included.
| Calculated Process Insulation Values | ||||||||
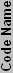 |
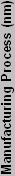 |
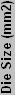 |
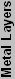 |
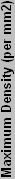 |
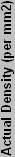 |
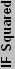 |
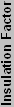 |
|
| AMD | ||||||||
| K6 | 8800000 | 250 | 68 | 5 | 16000000 | 129411.76 | 123.636 | 11.119 |
| K6-2 | 9300000 | 250 | 81 | 6 | 16000000 | 114814.81 | 139.355 | 11.805 |
| K6-3 | 21300000 | 250 | 135 | 7 | 16000000 | 157777.78 | 101.408 | 10.070 |
| Argon | 22000000 | 250 | 184 | 7 | 16000000 | 119565.22 | 133.818 | 11.568 |
| Average for 250 nm | 124.554 | 11.141 | ||||||
| Pluto/Orion | 22000000 | 180 | 102 | 7 | 30864198 | 215686.27 | 143.098 | 11.962 |
| Spitfire | 25000000 | 180 | 100 | 7 | 30864198 | 250000.00 | 123.457 | 11.111 |
| Morgan | 25200000 | 180 | 106 | 7 | 30864198 | 237735.85 | 129.826 | 11.394 |
| Thunderbird | 37000000 | 180 | 117 | 7 | 30864198 | 316239.32 | 97.598 | 9.879 |
| Palomino | 37500000 | 180 | 129 | 8 | 30864198 | 290697.67 | 106.173 | 10.304 |
| Average for 180 nm | 120.030 | 10.930 | ||||||
| Thoroughbred A | 37500000 | 130 | 80 | 8 | 59171598 | 468750.00 | 126.233 | 11.235 |
| Thoroughbred B | 37500000 | 130 | 84 | 9 | 59171598 | 446428.57 | 132.544 | 11.513 |
| Barton | 54300000 | 130 | 101 | 9 | 59171598 | 537623.76 | 110.061 | 10.491 |
| Sledgehammer SOI | 105900000 | 130 | 193 | 9 | 59171598 | 548704.66 | 107.839 | 10.385 |
| Average for 130 nm | 119.169 | 10.906 | ||||||
| San Diego SOI | 105900000 | 90 | 114 | 9 | 123456790 | 928947.37 | 132.900 | 11.528 |
| Intel | ||||||||
| Deschutes | 7500000 | 250 | 118 | 5 | 16000000 | 63559.32 | 251.733 | 15.866 |
| Katmai | 9500000 | 250 | 131 | 5 | 16000000 | 72519.08 | 220.632 | 14.854 |
| Mendocino | 19000000 | 250 | 154 | 6 | 16000000 | 123376.62 | 129.684 | 11.388 |
| Average for 250 nm | 200.683 | 14.036 | ||||||
| Coppermine First | 28100000 | 180 | 106 | 6 | 30864198 | 265094.34 | 116.427 | 10.790 |
| Coppermine Last | 28100000 | 180 | 90 | 6 | 30864198 | 312222.22 | 98.853 | 9.942 |
| Willamette | 42000000 | 180 | 217 | 6 | 30864198 | 193548.39 | 159.465 | 12.628 |
| Average for 180 nm | 124.915 | 11.120 | ||||||
| Tualatin | 28100000 | 130 | 80 | 6 | 59171598 | 351250.00 | 168.460 | 12.979 |
| Northwood First | 55000000 | 130 | 146 | 6 | 59171598 | 376712.33 | 157.074 | 12.533 |
| Northwood Last | 55000000 | 130 | 131 | 6 | 59171598 | 419847.33 | 140.936 | 11.872 |
| Average for 130 nm | 155.490 | 12.461 | ||||||
| Prescott | 125000000 | 90 | 112 | 7 | 123456790 | 1116071.43 | 110.617 | 10.517 |
| ATI | ||||||||
| RV350 | 75000000 | 130 | 91 | 8 | 59171598 | 824175.82 | 71.795 | 8.473 |
| Nvidia | ||||||||
| NV10 | 23000000 | 220 | 110 | 8 | 20661157 | 209090.91 | 98.814 | 9.941 |
| Average Insulation Factors | ||||||||
| 250 nm | 12.588 | |||||||
| 220 nm | 9.941 | |||||||
| 180 nm | 11.025 | |||||||
| 150 nm | 10.819 | |||||||
| 130 nm | 10.613 | |||||||
| 90 nm | 11.023 | |||||||
Lacking anything better than that, then, we will use the averages of the Intel and AMD values for the matching ATI and NVIDIA chips, with a little discretionary rounding to keep things simple. In cases where we have better estimates on die size, we will derive the IF and use those same IF values on the other chips from the same company. Looking at the numbers, the IF for AMD and Intel chips tends to range between 10 on a mature process up to 16 for initial chips on a new process. The two figures from GPUs are much lower than the typical CPU values, so we will assume GPUs tend to have more densely packed transistors (or else AMD and Intel are less aggressive in counting transistors).
These initial IF values could be off by as much as 20%, which means the end results could be off by as much as 44%. (How's that, you ask? 120% squared = 144%.) So, if this isn't abundantly clear yet, you should take these values with a HUGE dose of skepticism. If you have a better reference to an approximate die size (i.e. a web site with an images and/or die size measurements), please send an email or post a comment. Getting accurate figures would be really nice, but it is virtually impossible. Anyway, here are the IF values used in the estimates, with a brief explanation of why they were used.
| Chipset | IF | Notes |
| NV1x | 10.0 | Size is ~110 mm2 |
| NV2x | 10.00 | No real information and this seems a common value for GPUs of the era. |
| NV30, NV31 | 10.00 | Initial use of 130 nm was likely not optimal. |
| NV34 | 9.50 | Use of mature 150 nm process. |
| NV35, NV36, NV38 | 9.5 | Size is ~207 mm2 |
| NV40 | 8.75 | Size is ~288 mm2 |
| NV43 | 9.50 | Initial use of 110 nm process will not be as optimal as 130 nm. |
| R300, R350, R360 | 9.00 | Mature 150 nm process should be better than initial results. |
| RV350, RV360, RV380 | 8.50 | Size is ~91 mm2 |
| RV370 | 9.00 | No real information, but assuming the final chip will be smaller than RV360. Otherwise 110 nm is useless. |
| R420 | 9.75 | Size is ~260 mm2 |
| Other ATI Chips | 10.00 | Standard guess lacking any other information. |
Note also that there are reports that ATI is more conservative in transistor counts, so their 160 million could be equal to 180 or even 200 million of NVIDIA's transistors. Basically, transistor counts are estimates, and ATI is more conservative while NVIDIA likes to count everything they can. Neither is "right", but looking at die sizes, the 6800 is not much larger than the X800, despite a supposed 60 million transistor weight advantage. Either the IBM 130 nm fabs are not as advanced as the TSMC 130 nm fabs, or ATI's transistor counts are somewhat low, or NVIDIA's counts are somewhat high - most likely it's a combination of all these factors.
So, those are the values we'll use initially for our estimates. The most recent TSMC and IBM chips are using 8 metal layers, and since it does not really affect the estimates, we have put 8 metal layers on all of the GPUs. Again, if you have a source that gives an actual die size for any of the chips other than the few that we already have, please send them to us, and we can update the charts.








43 Comments
View All Comments
MODEL 3 - Wednesday, September 8, 2004 - link
A lot of mistakes for a professional hardware review site the size of Anandtech.I will only mention the de facto mistakes since I have doubts for more.I am actually surprised about the amount of mistakes in this article.I mean since I live in Greece (not the center of the world in 3d technology or hardware market) I always thought that the editors in the best hardware review sites of the world (like Anandtech) have at least the basic knowledge related to technology and they make research and doublecheck if their articles are correct.I mean they get paid, right?I mean if I can find so easily their mistakes (I have no technology related degree although I was purchase and product manager in the best Greek IT companies) they must be doing something very,very wrong indeed.Now onto the mistakes:ATI :
X700 6 vertex pipelines: Actually this is no mistake since I have no information about this new part but it seems strange if X700 will have the same (6) vertex pipelines as X800XT.I guess more logical would be half as many (3) (like 6800Ultra-6600GT) or double as many as X600 (4).We will see.
Radeon VE 183/183: The actual speed was 166/166SDR 128bit for ATI parts and as low as 143/143 for 3rd party bulk part
Radeon 7000 PCI 166/333 The actual speed was 166/166SDR 128bit for ATI parts and as low as 143/143 for 3rd party bulk part (note that anandtech suggests 166DDR and the correct is 166 SDR)
Radeon 7000 AGP 183/366 32/64(MB): The actual speed was 166/166SDR for ATI parts and as low as 143/143 for 3rd party bulk part (note that anandtech suggests 166DDR and the correct is 166 SDR) also at launch and for a whole year (if ever) it didn't exist a 64MB part
Radeon 7200 64bit ram bus: The 7200 was exactly the same as Radeon DDR so the ram bus width was 128bit
ATI has unofficial DX 9 with SM2.0b support: Actually ATI has official DX 9.0b support and Microsoft certified this "in between" version of DX9.When they enable their 2.0b feutures they don't fail WHQL compliance since 2.0b is official microsoft version (get it?).Feutures like 3Dc normal map compression are activated only in open GL mode but 3Dc compression is not part of DX9.0b.
NVIDIA:
GF 6800LE with 8 pixel pipelines has according to Anandtech 5 vertex pipelines: Actually this is no mistake since I have no information about this part but since 6800GT/Ultra is built with four (4) quads with 4 pixel pipelines each isn't more logical the 6800LE with half the quads to have half the pixel (8) AND half (3) the vertex pipelines?
GFFX 5700 3 vertex pipelines: GFFX 5700 has half the number of pixel AND vertex pipelines of 5900 so if you convert the vertex array of 5900 into 3 vertex pipes (which is correct) then the 5700 would have 1,5
GF4 4600 300/600: The actual speed is 300/325DDR 128bit
GF2MX 175/333: The actual speed is 175/166SDR 128bit
GF4MX series 0.5 vertex shader: Actually the GF4MX series had twice the amount of vertex shaders of GF2 so the correct number of vertex shader is 1
According to Anandtech, the GF3 cards only show a slight performance increase over the GF2 Ultra, and that is only in more recent games : Actually GF3 (Q1 01) was based in 0,18 nm technology and the yields was extremely low.In reality GF3 parts in acceptable quantity came in Q3 01 with GF3Ti series 0,15 nm technology .If you check the performance in open GL games at and after Q3 01 and DX8 games at and after Q3 02 you will clearly see GF3 to have double the performance of GF2 clock for clock (GF3Ti500 Vs GF2Ultra)
Now, the rest of the article is not bad and I also appreciate the effort.
JarredWalton - Wednesday, September 8, 2004 - link
Sorry, ViRGE - I actually took your suggestion to heart and updated page 3 initially, since you are right about it being more common. However, I forgot to modify the DX7 performance charts. There are probably quite a few other corrections that should be made as well....ViRGE - Tuesday, September 7, 2004 - link
Jared, like I said, you're technically right about how the GF2 MX could be outfitted with either 128bit SDR or 64bit SDR/DDR, but you said it yourself that the cards were mostly 128bit SDR. Obviously any change won't have an impact, but in my humble opinion, it would be best to change the GF2 MX to better represent what historically happened, so that if someone uses this chart as a reference for a GF2 MX, they're more likely to be getting the "right" data.BigLan - Tuesday, September 7, 2004 - link
Good job with the articleLove the office reference...
"Can I put it in my mouth?"
darth_beavis - Tuesday, September 7, 2004 - link
Sorry, now it's suddenly working. I don't know what my problem is (but I'm sure it's hard to pronounce).darth_beavis - Tuesday, September 7, 2004 - link
Actually it looks like none of them have labels. Is anandtech not mozilla compatible or something. Just use jpgs pleaz.darth_beavis - Tuesday, September 7, 2004 - link
Why is there no descriptions for the columns on the graph on pg 2. Are just supposed to guess what the numbers mean?JarredWalton - Tuesday, September 7, 2004 - link
Yes, Questar, laden with errors. All over the place. Thanks for pointing them out so that they could be corrected. I'm sure that took you quite some time.Seriously, though, point them out (other than omissions, as making a complete list of every single variation of every single card would be difficult at best) and we will be happy to correct them provided that they actually are incorrect. And if you really want a card included, send the details of the card, and we can add that as well.
Regarding the ATI AIW (All In Wonder, for those that don't know) cards, they often varied from the clock and RAM speeds of the standard chips. Later models may have faster RAM or core speeds, while earlier models often had slower RAM and core speeds.
blckgrffn - Tuesday, September 7, 2004 - link
Questar - if you don't like it, leave. The article clearly stated its bounds and did a great job. My $.02 - the 7500 AIW is 64 meg DDR only, unsure of the speed however. Do you want me to check that out?mikecel79 - Tuesday, September 7, 2004 - link
#22 The Geforce256 was released in October of 1999 so this is roughly the last 5 years of chips from ATI and Nvidia. If it were to include all other manufacturers it would be quite a bit longer.How about examples of this article being "laden or errors" instead of just stating it.