GPU Cheatsheet - A History of Modern Consumer Graphics Processors
by Jarred Walton on September 6, 2004 12:00 AM EST- Posted in
- GPUs
DirectX 8 Performance
Below you can see our plot of the DirectX 8 components.
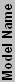 |
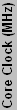 |
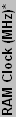 |
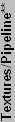 |
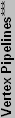 |
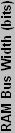 |
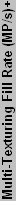 |
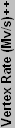 |
 |
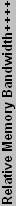 |
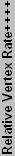 |
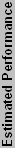 |
||
| GF4 Ti4200 64 | 250 | 500 | 4 | 2 | 2 | 128 | 2000 | 113 | 7629 | 100.0% | 100.0% | 100.0% | 100.0% |
| DirectX 8 and 8.1 | |||||||||||||
| GF4 Ti4800 | 300 | 650 | 4 | 2 | 2 | 128 | 2400 | 135 | 9918 | 120.0% | 130.0% | 120.0% | 123.3% |
| GF4 Ti4600 | 300 | 600 | 4 | 2 | 2 | 128 | 2400 | 135 | 9155 | 120.0% | 120.0% | 120.0% | 120.0% |
| GF4 Ti4400 | 275 | 550 | 4 | 2 | 2 | 128 | 2200 | 124 | 8392 | 110.0% | 110.0% | 110.0% | 110.0% |
| GF4 Ti4800 SE | 275 | 550 | 4 | 2 | 2 | 128 | 2200 | 124 | 8392 | 110.0% | 110.0% | 110.0% | 110.0% |
| GF4 Ti4200 8X | 250 | 514 | 4 | 2 | 2 | 128 | 2000 | 113 | 7843 | 100.0% | 102.8% | 100.0% | 100.9% |
| GF4 Ti4200 64 | 250 | 500 | 4 | 2 | 2 | 128 | 2000 | 113 | 7629 | 100.0% | 100.0% | 100.0% | 100.0% |
| GF4 Ti4200 128 | 250 | 444 | 4 | 2 | 2 | 128 | 2000 | 113 | 6775 | 100.0% | 88.8% | 100.0% | 96.3% |
| 8500 | 275 | 550 | 4 | 2 | 1 | 128 | 2200 | 69 | 8392 | 110.0% | 110.0% | 61.1% | 93.7% |
| 9100 Pro | 275 | 550 | 4 | 2 | 1 | 128 | 2200 | 69 | 8392 | 110.0% | 110.0% | 61.1% | 93.7% |
| 9100 | 250 | 500 | 4 | 2 | 1 | 128 | 2000 | 63 | 7629 | 100.0% | 100.0% | 55.6% | 85.2% |
| 8500 LE | 250 | 500 | 4 | 2 | 1 | 128 | 2000 | 63 | 7629 | 100.0% | 100.0% | 55.6% | 85.2% |
| 9200 Pro | 300 | 600 | 4 | 1 | 1 | 128 | 1200 | 75 | 9155 | 60.0% | 120.0% | 66.7% | 82.2% |
| GF3 Ti500 | 240 | 500 | 4 | 2 | 1 | 128 | 1920 | 54 | 7629 | 96.0% | 100.0% | 48.0% | 81.3% |
| 9000 Pro | 275 | 550 | 4 | 1 | 1 | 128 | 1100 | 69 | 8392 | 55.0% | 110.0% | 61.1% | 75.4% |
| GeForce 3 | 200 | 460 | 4 | 2 | 1 | 128 | 1600 | 45 | 7019 | 80.0% | 92.0% | 40.0% | 70.7% |
| 9000 | 250 | 400 | 4 | 1 | 1 | 128 | 1000 | 63 | 6104 | 50.0% | 80.0% | 55.6% | 61.9% |
| 9200 | 250 | 400 | 4 | 1 | 1 | 128 | 1000 | 63 | 6104 | 50.0% | 80.0% | 55.6% | 61.9% |
| GF3 Ti200 | 175 | 400 | 4 | 2 | 1 | 128 | 1400 | 39 | 6104 | 70.0% | 80.0% | 35.0% | 61.7% |
| 9250 | 240 | 400 | 4 | 1 | 1 | 128 | 960 | 60 | 6104 | 48.0% | 80.0% | 53.3% | 60.4% |
| 9200 SE | 200 | 333 | 4 | 1 | 1 | 64 | 800 | 50 | 2541 | 40.0% | 33.3% | 44.4% | 39.2% |
| * RAM clock is the effective clock speed, so 250 MHz DDR is listed as 500 MHz. | |||||||||||||
| ** Textures/Pipeline is the maximum number of texture lookups per pipeline. | |||||||||||||
| *** NVIDIA says their GFFX cards have a "vertex array", but in practice it generally functions as indicated. | |||||||||||||
| **** Single-texturing fill rate = core speed * pixel pipelines | |||||||||||||
| + Multi-texturing fill rate = core speed * maximum textures per pipe * pixel pipelines | |||||||||||||
| ++ Vertex rates can vary by implementation. The listed values reflect the manufacturers' advertised rates. | |||||||||||||
| +++ Bandwidth is expressed in actual MB/s, where 1 MB = 1024 KB = 1048576 Bytes. | |||||||||||||
| ++++ Relative performance is normalized to the GF4 Ti4200 64, but these values are at best a rough estimate. | |||||||||||||
No weighting has been applied to the DirectX 8 charts, and performance in games generally falls in line with what is represented in the above chart. Back in the DirectX 8 era, NVIDIA really had a huge lead in performance over ATI. The Radeon 8500 was able to offer better performance than the GeForce 3, but that lasted all of two months before the launch of the GeForce 4 Ti line. Of course, many people today continue running GeForce4 Ti cards with few complaints about performance - only high quality rendering modes and DX9-only applications are really forcing people to upgrade. For casual gamers, finding a used GF4Ti card for $50 or less may be preferable to buying a low-end DX9 card. It really isn't until the FX5700 Ultra and FX5600 Ultra that the GF4Ti cards are outclassed, and those cards still cost well over $100 new.
ATI did have one advantage over NVIDIA in the DirectX 8 era, however. They worked with Microsoft to create an updated version of DirectX; version 8.1. This added support for some "advanced pixel shader" effects, which brought the Pixel Shader version up to 1.4. There wasn't anything that could be done in DX8.1 that couldn't be done with DX8.0, but several operations could be done in one pass instead of two passes. Support for DirectX 8 games was very late in coming, however, and support for ATI's extensions was, if possible, even more so. There are a few titles which now support the DX8.1 extensions, but even then the older DX8.1 ATI cards are generally incapable of running these games well.
It is worth noting that the vertex rates on the NVIDIA cards are calculated as 90% of the clock speed times the number of vertex pipelines, divided by four. Why is that important? It's not, really, but on the FX and GF6 series of cards, NVIDIA uses clock speed times vertex pipelines divided by four for the claimed vertex rate. It could be that architectural improvements made the vertex rate faster. Such detail was lacking on the ATI side of things, although 68 million vertices/second for the 8500 was claimed in a few places, which matches the calculation used on NVIDIA's DX9 cards. You don't have to look any further than such benchmarks as 3DMark01 to find that these theoretical maximum are never reached, of course - even with one light source and no textures, the high polygon count scene doesn't come near the claimed rate.








43 Comments
View All Comments
suryad - Monday, September 6, 2004 - link
What about the mobility x800 graphics card? I didnt see that thrown into the mix?coldpower27 - Monday, September 6, 2004 - link
Thank you Bloodshredder, yeh after reading a little about the Radeon LE, it's almost as good as a Radeon DDR, except with lower working frequencies.so if it's DDR then the correct no. are 148/296 and 32MB VRAM only.
Bloodshedder - Monday, September 6, 2004 - link
For the Radeon LE, I noticed a question mark next to the amount of RAM. I own one of these cards, and can confirm that 32MB DDR is the only configuration it comes in.Draven31 - Monday, September 6, 2004 - link
You skipped which OpenGL version and features the various cards support... maybe add that when you add the various workstation cards to the listings...coldpower27 - Monday, September 6, 2004 - link
Yeh, Nvidia learned it's lesson, last gen, with the 0.13 micron new at the time process delaying the introduction of the NV30, thy learned to play it safe using a tried and tested process is a good idea for such high complexity chips initially, though they of course plan to shift these chips to the 110nm process when the process matures enough, possibly on the NV48 and R480 hopefully allowing higher clocks in the process:D, maybe not for R480 unless low-k is ready for 110nm by that time.
It does make more sense to use the newer manufacturing process to help save costs on the volume shipping GPU, as the cost savings will beaccumulated much better in the mainstream and value arena's thanks to sheer volume.
We also see this with Intel, when Intel yields on the 90nm were only so so, they introduced Prescott up to 3.2GHZ in quanitity, but introduced their Pentium 4 3.4GHZ on the northwood core on 0.13 micron. Though over time Intel is making all efforts to transfer everything to 90nm, with Prescott and Prescott 2M w/1066FSB for EE Edition.
JarredWalton - Monday, September 6, 2004 - link
8 - Intel does this as well, testing a new process on their non-flagship parts. For example, after the launch of the P4, Intel piloted their 130 nm copper technology with the Tualatin CPU before releasing the Northwood. It probably has something to do with the amount of extra time a more complex design takes to test and verify.stephenbrooks - Monday, September 6, 2004 - link
Interesting how on the die sizes chart, I notice they're phasing in the 110nm process only for their mid-range-ish cards and sticking to the tried and tested 130nm for the high-end one. I suppose you can't blame them for that really, given it's their flagship product and all, but it could contribute to the huge die sizes.JarredWalton - Monday, September 6, 2004 - link
Thank, AtaStrumf - any errors in the numbers are ColdPower's fault. Heheheh. Really, he already caught a bunch of small mistakes, so hopefully the number of remaining errors is very small.For what it's worth, there are various versions of some of the chips that have different clock speeds and RAM speeds from what is listed. The models in the chart should reflect the most common configurations, though.
BTW, the article text is now tweaked somewhat on the ATI and NVIDIA overview pages. Derek Wilson provided some additional insight on the subject of AA and AF that clarified things a little.
JarredWalton - Monday, September 6, 2004 - link
Argon was the name for the .25 micron K7, while Pluto and Orion were .18 micron.#2 and #4: I realize you're kidding, but in all seriousness we did think about including other architectures. With the broken features on some of the more recent cards and the lack of T&L on 3dfx and older cards, we just decided to stick with the two major players. And hey - it's all fair, as we didn't include Cyrix/Via or Transmeta processors in the CPU cheatsheet! ;)
AtaStrumf - Monday, September 6, 2004 - link
OMFG, this is awsome!!!! You really outdid youself this time! I have been collecting data on GPUs for quite a while and have been planing on making a spreadsheet just like the first two for my, so called, web site, but WAU, this rocks. Thanks for saving me a lot of work :)When I get the time, I'll check your munbers a bit, just to make sure there aren't any typos in there.