AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM EST
If you examine the CPU industry and ask where the big money is, you have to look at the server and datacenter market. Ever since the Opteron days, AMD's market share has been rounded to zero percent, and with its first generation of EPYC processors using its new Zen microarchitecture, that number skipped up a small handful of points, but everyone has been waiting with bated breath for the second swing at the ball. AMD's Rome platform solves the concerns that first gen Naples had, plus this CPU family is designed to do many things: a new CPU microarchitecture on 7nm, offer up to 64 cores, offer 128 lanes of PCIe 4.0, offer 8 memory channels, and offer a unified memory architecture based on chiplets. Today marks the launch of Rome, and we have some of our own data to share on its performance.
Review edited by Dr. Ian Cutress
First Boot
Sixty-four cores. Each core with an improved Zen 2 core, offering ~15% better IPC performance than Naples (as tested in our consumer CPU review), and doubled AVX2/FP performance. The chip has a total of 256 MB of L3 cache, and 128 PCIe 4.0 lanes. AMD's second generation EPYC, in this case the EPYC 7742, is a behemoth.
Boot to BIOS, check the node information.
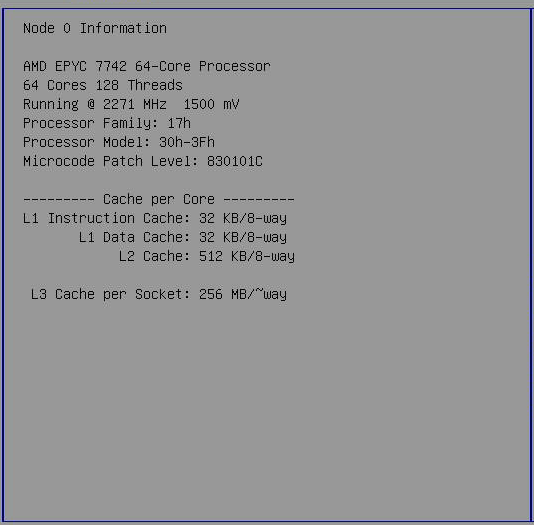
[Note: That 1500 mV reading in the screenshot is the same reading we see on consumer Ryzen platforms; it seems to be the non-DVFS voltage as listed in the firmware, but isn't actually observed]
It is clear that the raw specifications of our new Rome CPU is some of the most impressive on the market. The question then goes to whether or not this is the the new fastest server chip on the market - a claim that AMD is putting all its weight behind. If this is the new fastest CPU on the market, the question then becomes 'by how much?', and 'how much does it cost?'.
I have been covering server CPUs since the launch of the Opteron in 2003, but this is nothing like I have seen before: a competitive core and twice as much of them on a chip than what the competition (Intel, Cavium, even IBM) can offer. To quote AMD's SVP of its Enterprise division, Forrest Norrod:
"We designed this part to compete with Ice Lake, expecting to make some headway on single threaded performance. We did not expect to be facing re-warmed Skylake instead. This is going to be one of the highlights of our careers"
Self-confidence is at all times high at AMD, and on paper it would appear to be warranted. The new Rome server CPUs have improved core IPC, a doubling of the core count at the high end, and it is using a new manufacturing process (7 nm) technology in one swoop. Typically we see a server company do one of those things at a time, not all three. It is indeed a big risk to take, and the potential to be exciting if everything falls into place.

To put this into perspective: promising up to 2x FP performance, 2x cores, and a new process technology would have sounded so odd a few years ago. At the tail end of the Opteron days, just 4-5 years ago, Intel's best CPUs were up to three times faster. At the time, there was little to no reason whatsoever to buy a server with AMD Opterons. Two years ago, EPYC got AMD back into the server market, but although the performance per dollar ratio was a lot better than Intel's, it was not a complete victory. Not only was AMD was still trailing in database performance and AVX/FP performance, but partners and OEMs were also reluctant to partner with the company without a proven product.
So now that AMD has proven its worth with Naples, and AMD promising more than double the deployed designs of Rome with a very quick ramp to customers, we have to compare the old to the new. For the launch of the new hardware, AMD provided us with a dual EPYC 7742 system from Quanta, featuring two 64-core CPUs.








180 Comments
View All Comments
steepedrostee - Thursday, August 8, 2019 - link
if i had to guess who is more full of crapola, i would think youSmell This - Thursday, August 8, 2019 - link
Pooper Lake?
Cascade is obviously, The Mistake By The Lake
Chipzillah will certainly strike back but it reminds me of the old 'virgin' joke. "My first wife was an OB/GYN, and all she wanted to do was look at it. My second wife was a psychiatrist, and all she wanted to do was talk about it, and ...
My third wife was an Intel Fan Girl, and all she could say was, "Wait until next year!"
HA!
RSAUser - Thursday, August 8, 2019 - link
Do we finally have a contender to run Crysis on max?Tunnah - Thursday, August 8, 2019 - link
I'd normally just ignore this but this really needs proofreading, There's multiple mistakes on every page, becomes a bit difficult to follow.cerealspiller - Thursday, August 8, 2019 - link
Well, 50% of the sentences in your post have a grammatical error, so I will just try to ignore it.GreenReaper - Friday, August 9, 2019 - link
He's a reader, not a writer. ;-)Oliseo - Thursday, August 8, 2019 - link
Pot. Meet Kettle.steepedrostee - Thursday, August 8, 2019 - link
wow amd !umano - Thursday, August 8, 2019 - link
Intel people will welcome "Rome" like gladiators "Ave, Caesar, morituri te salutant"I am really happy for Amd and I really hope their sells will be a lot more than they could ever dream.
Because they become more than competitive with the most rightful strategy, just deliver an awesome product. The fact they think that they will just double their shares shows how sick the market(s) are. The epyc is faster, greener and way way cheaper.
29a - Thursday, August 8, 2019 - link
"AMD does not blow fuses on cheaper SKUs to create artificial 'value' for buying more expensive SKUs"I like this guy, more reviews from him. He's not afraid to bite the hand that feeds him.