AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTPCIe 4.0
As the first commerical x86 server CPU supporting PCIe 4.0, the I/O capabilities of second generation EPYC servers are top of the class. One PCIe 4.0 x16 offers up to 32 GB/s in both direction, so each socket offers up to 256 GB/s in both directions, for a full 128 PCIe 4.0 lanes per CPU.

Each CPU has 8 x16 PCIe 4.0 links available which can be split up among up to 8 devices per PCIe root, as shown above. There is also full PCIe peer-to-peer support both within a single socket and across sockets.
With the previous generation, in order to enable a dual socket configuration, 64 PCIe lanes from each CPU were used to link them together. For EPYC, AMD still allows for 64 PCIe lanes to be used, but these are PCIe 4.0 lanes now. There is also another feature that AMD has here - socket-to-socket IF link bandwidth management - which allows OEM partners to design dual-socket systems with less socket-to-socket bandwidth and more PCIe lanes if needed.
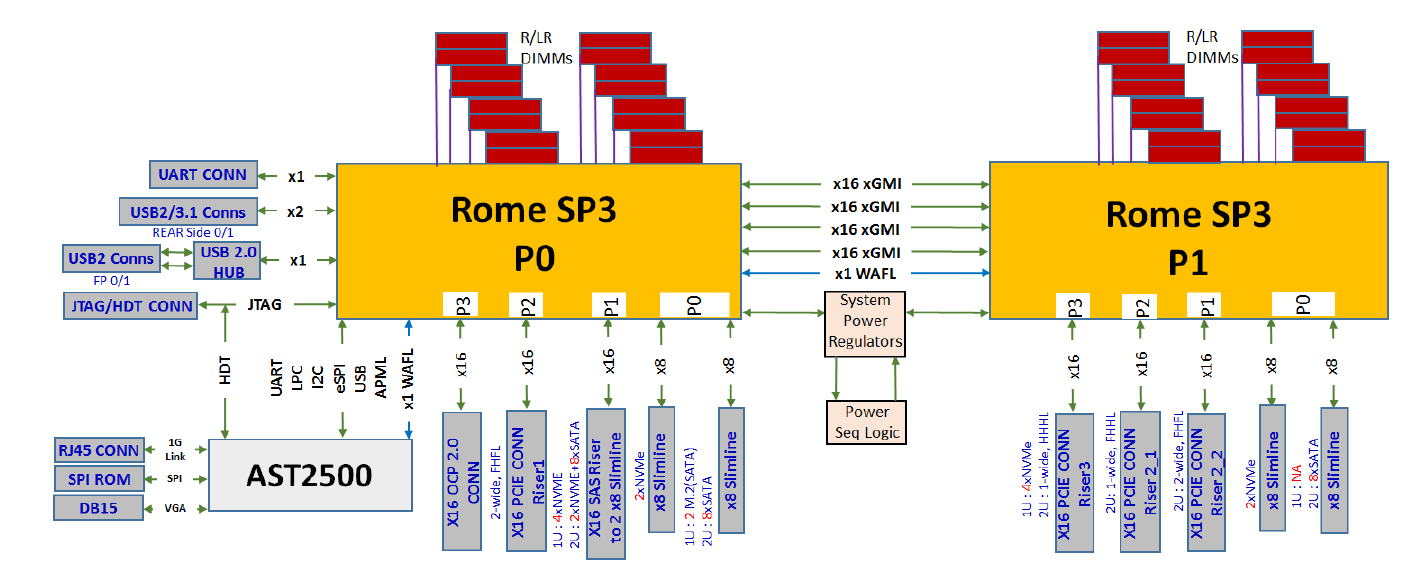
We also learned that there are in fact 129 PCIe 4.0 lanes on each CPU. On each CPU there is one extra PCIe lane for the BMC (the chip that controls the server). Considering we are living in the age of AI acceleration, the EPYC 7002 servers will be great as hosts for quite a few GPUs or TPUs. Density has never looked so fun.








180 Comments
View All Comments
AnonCPU - Friday, August 9, 2019 - link
The gain in hmmer on EPYC with GCC8 is not due to TAGE predictor.Hmmer gains a lot on EPYC only because of GCC8.
GCC8 vectorizer has been improved in GCC8 and hmmer gets vectorized heavily while it was not the case for GCC7. The same run on an Intel machine would have shown the same kind of improvement.
JohanAnandtech - Sunday, August 11, 2019 - link
Thanks, do you have a source for that? Interested in learning more!AnonCPU - Monday, August 12, 2019 - link
That should be due to the improvements on loop distribution:https://gcc.gnu.org/gcc-8/changes.html
"The classic loop nest optimization pass -ftree-loop-distribution has been improved and enabled by default at -O3 and above. It supports loop nest distribution in some restricted scenarios;"
There are also some references here in what was missing for hmmer vectorization in GCC some years ago:
https://gcc.gnu.org/ml/gcc/2017-03/msg00012.html
And a page where you can see that LLVM was missing (at least in 2015) a good loop distribution algo useful for hmmer:
https://www.phoronix.com/scan.php?page=news_item&a...
AnonCPU - Monday, August 12, 2019 - link
And more:https://community.arm.com/developer/tools-software...
just4U - Friday, August 9, 2019 - link
I guess the question to ask now is can they churn these puppies out like no tomorrow? Is the demand there? What about other Hardware? Motherboards and the like..Do they have 100 000 of these ready to go? The window of opportunity for AMD is always fleeting.. and if their going to capitalize on this they need to be able to put the product out there.
name99 - Friday, August 9, 2019 - link
No obvious reason why not. The chiplets are not large and TSMC ships 200 million Apple chips a year on essentially the same process. So yields should be there.Manufacturing the chiplet assembly also doesn't look any different from the Naples assembly (details differ, yes, but no new envelopes being pushed: no much higher frequency signals or denser traces -- the flip side to that is that there's scope there for some optimization come Milan...)
So it seems like there is nothing to obviously hold them back...
fallaha56 - Saturday, August 10, 2019 - link
Perhaps Hypertheading should be off on the Intel systems to better reflect eg Google’s reality / proper security standards now we know Intel isn’t secure?Targon - Monday, August 12, 2019 - link
That is why Google is going to be buying many Epyc based servers going forward. Mitigations do not mean a problem has been fixed.imaskar - Wednesday, August 14, 2019 - link
Why do you think AWS, GCP, Azure, etc. mitigated the vulnerabilities? They only patched Meltdown at most. All other things are too costly and hard to execute. They just don't care so much for your data. Too loose 2x cloud capacity for that? No way. And for security conscious serious customers they offer private clusters, so your workloads run on separate servers.ballsystemlord - Saturday, August 10, 2019 - link
Spelling and grammar errors:"This happened in almost every OS, and in some cases we saw reports that system administrators and others had to do quite a bit optimization work to get the best performance out of the EPYC 7001 series."
Missing "of":
"This happened in almost every OS, and in some cases we saw reports that system administrators and others had to do quite a bit of optimization work to get the best performance out of the EPYC 7001 series."
"...to us it is simply is ridiculous that Intel expect enterprise users to cough up another few thousand dollars per CPU for a model that supports 2 TB,..."
Excess "is" and missing "s":
"...to us it is simply ridiculous that Intel expects enterprise users to cough up another few thousand dollars per CPU for a model that supports 2 TB,..."
"Although the 225W TDP CPUs needs extra heatspipes and heatsinks, there are still running on air cooling..."
Excess "s" and incorrect "there",
"Although the 225W TDP CPUs need extra heatspipes and heatsinks, they're still running on air cooling..."
"The Intel L3-cache keeps latency consistingy low as long as you stay within the L3-cache."
"consistently" not "consistingy":
"The Intel L3-cache keeps latency consistently low as long as you stay within the L3-cache."
"For example keeping a large part of the index in the cache improve performance..."
Missing comma and missing "s" (you might also consider making cache plural, but you seem to be talking strictly about the L3):
"For example, keeping a large part of the index in the cache improves performance..."
"That is a real thing is shown by the fact that Intel states that the OLTP hammerDB runs 60% faster on a 28-core Intel Xeon 8280 than on EPYC 7601."
Missing "it":
"That it is a real thing is shown by the fact that Intel states that the OLTP hammerDB runs 60% faster on a 28-core Intel Xeon 8280 than on EPYC 7601."
In general, the beginning of the sentance appears quite poorly worded, how about:
"That L3 cache latency is a matter for concern is shown by the fact that Intel states that the OLTP hammerDB runs 60% faster on a 28-core Intel Xeon 8280 than on EPYC 7601."
"In NPS4, the NUMA domains are reported to software in such a way as it chiplets always access the near (2 channels) DRAM."
Missing "s":
"In NPS4, the NUMA domains are reported to software in such a way as its chiplets always access the near (2 channels) DRAM."
"The fact that the EPYC 7002 has higher DRAM bandwidth is clearly visible."
Wrong numbers (maybet you ment, series?):
"The fact that the EPYC 7742 has higher DRAM bandwidth is clearly visible."
"...but show very significant improvements on EPYC 7002."
Wrong numbers (maybet you ment, series?):
"...but show very significant improvements on EPYC 7742."
"Using older garbage collector because they happen to better at Specjbb"
Badly worded.
"Using an older garbage collector because it happens to be better at Specjbb"
"For those with little time: at the high end with socketed x86 CPUs, AMD offers you up to 50 to 100% higher performance while offering a 40% lower price."
"Up to" requires 1 metric, not 2. Try:
"For those with little time: at the high end with socketed x86 CPUs, AMD offers you from 50 up to 100% higher performance while offering a 40% lower price."