AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTBetter Core in Zen 2
Just in case you have missed it, in our microarchitecture analysis article Ian has explained in great detail why AMD claims that its new Zen2 is significantly better architecture than Zen1:
- a different second-stage branch predictor, known as a TAGE predictor
- doubling of the micro-op cache
- doubling of the L3 cache
- increase in integer resources
- increase in load/store resources
- support for two AVX-256 instructions per cycle (instead of having to combine two 128 bit units).
All of these on-paper improvements show that AMD is attacking its key markets in both consumer and enterprise performance. With the extra compute and promised efficiency, we can surmise that AMD has the ambition to take the high-performance market back too. Unlike the Xeon, the 2nd gen EPYC does not declare lower clocks when running AVX2 - instead it runs on a power aware scheduler that supplies as much frequency as possible within the power constraints of the platform.
Users might question, especially with Intel so embedded in high performance and machine learning, why AMD hasn't gone with an AVX-512 design? As a snap back to the incumbent market leader, AMD has stated that not all 'routines can be parallelized to that degree', as well as a very clear signal that 'it is not a good use of our silicon budget'. I do believe that we may require pistols at dawn. Nonetheless, it will be interesting how each company approaches vector parallelisation as new generations of hardware come out. But as it stands, AMD is pumping its FP performance without going full-on AVX-512.
In response to AMD's claims of an overall 15% IPC increase for Zen 2, we saw these results borne out of our analysis of Zen 2 in the consumer processor line, which was released last month. In our analysis, Andrei checked and found that it is indeed 15-17% faster. Along with the performance improvements, there have been also security hardening updates, improved virtualization support, and new but proprietary instructions for cache and memory bandwidth Quality of Service (QoS). (The QoS features seem very similar to what Intel has introduced in Broadwell/Xeon E5 version 4 and Skylake - AMD is catching up in that area).
Rome Layout: Simple Makes It a Lot Easier
When we analyzed AMD's first generation of EPYC, one of the big disadvantages was the complexity. AMD had built its 32-core Naples processors by enabling four 8-core silicon dies, and attaching each one to two memory channels, resulting in a non-uniform memory architecutre (NUMA). Due to this 'quad NUMA' layout, a number of applications saw quite a few NUMA balancing issues. This happened in almost every OS, and in some cases we saw reports that system administrators and others had to do quite a bit optimization work to get the best performance out of the EPYC 7001 series.
The New 2nd Gen EPYC, Rome, has solved this. The CPU design implements a central I/O hub through which all communications off-chip occur. The full design uses eight core chiplets, called Core Complex Dies (CCDs), with one central die for I/O, called the I/O Die (IOD). All of the CCDs communicate with this this central I/O hub through dedicated high-speed Infinity Fabric (IF) links, and through this the cores can communicate to the DRAM and PCIe lanes contained within, or other cores.
The CCDs consist of two four-core Core CompleXes (1 CCD = 2 CCX). Each CCX consist of a four cores and 16 MB of L3 cache, which are at the heart of Rome. The top 64-core Rome processors overall have 16 CCX, and those CCX can only communicate with each other over the central I/O die. There is no inter-chiplet CCD communication.

This is what this diagram shows. On the left we have Naples, first Gen EPYC, which uses four Zepellin dies each connected to the other with an IF link. On the right is Rome, with eight CCDs in green around the outside, and a centralized IO die in the middle with the DDR and PCIe interfaces.
As Ian reported, while the CCDs are made at TSMC, using its latest 7 nm process technology. The IO die by contrast is built on GlobalFoundries' 14nm process. Since I/O circuitry, especially when compared to caching/processing and logic circuitry, is notoriously hard to scale down to smaller process nodes, AMD is being clever here and using a very mature process technology to help improve time to market, and definitely has advantages.
This topology is clearly visible when you take off the hood.

Main advantage is that the 2nd Gen 'EPYC 7002' family is much easier to understand and optimize for, especially from a software point of view, compared to Naples. Ultimately each processor only has one memory latency environment, as each core has the same latency to speak to all eight memory channels simultanously - this is compared to the first generation Naples, which had two NUMA regions per CPU due to direct attached memory.
As seen in the image below, this means that in a dual socket setup, a Naples processor will act like a traditional NUMA environment that most software engineers are familiar with.

Ultimately the only other way to do this is with a large monolithic die, which for smaller process nodes is becoming less palatable when it comes to yields and pricing. In that respect, AMD has a significant advantage in being able to develop small 7nm silicon with high yields and also provide a substantial advantage when it comes to binning for frequency.
How a system sees the new NUMA environment is quite interesting. For the Naples EPYC 7001 CPUs, this was rather complicated in a dual socket setup:
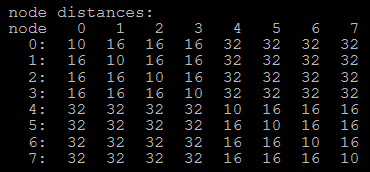
Here each number shows the 'weighting' given to the delay to access each of the other NUMA domains. Within the same domain, the weighting is light at only 10, but then a NUMA domain on the same chip was given a 16. Jumping off the chip bumped this up to 32.
This changed significantly on Rome EPYC 7002:

Although there are situations where the EPYC 7001 CPUs communicated faster, but the fact that the topology is much simpler from the software point of view is worth a lot. It makes getting good performance out of the chip much easier for everyone that has to used it, which will save a lot of money in Enterprise, but also help accelerate adoption.








180 Comments
View All Comments
Zoolook - Saturday, August 10, 2019 - link
It's been a pretty good investment for me, bought at 8$ two years ago, seems like I'll keep it for a while longer.CheapSushi - Wednesday, August 7, 2019 - link
It's glorious...one might say.... even EPYC.abufrejoval - Wednesday, August 7, 2019 - link
Hard to believe a 64 core CPU can be had for the price of a used middle class car or the price of four GTX 2080ti.Of course once you add 2TB of RAM and as many PCIe 4 SSDs as those lanes will feed, it no longer feels that affordable.
There is a lot of clouds still running ancient Sandy/Ivy Bridge and Haswell CPUs: I guess replacing those will eat quite a lot of chips.
And to think that it's the very same 8-core part that powers the engire range: That stroke of simplicity and genius took so many years of planning ahead and staying on track during times when AMD was really not doing well. Almost makes you believe that corporations owned by share holders can actually sometimes actually execute a strategy, without Facebook type voting rights.
Raising my coffee mug in a salute!
schujj07 - Thursday, August 8, 2019 - link
Sandy Bridge maxed out at 8c/16t.Ivy Bridge maxed out at 15c/30t.
Haswell maxed out at 18c/36t.
That means that a single socket Epyc 64c/128t can give you more CPU cores than a quad socket Sandy Bridge (32c/64t) or Ivy Bridge (60c/120t) and only a few less cores that a quad socket Haswell (72c/144t).
Eris_Floralia - Wednesday, August 7, 2019 - link
This is what we've all been waiting for!Eris_Floralia - Wednesday, August 7, 2019 - link
Thank you for all the work!quorm - Wednesday, August 7, 2019 - link
Given the range of configurations and prices here, I don't see much room for threadripper. Maybe 16 - 32 cores with higher clock speeds? Really wondering what a new threadripper can bring to the table.willis936 - Wednesday, August 7, 2019 - link
A reduced feature set and lower prices, namely.quorm - Wednesday, August 7, 2019 - link
Reduced in what way, though? I'm assuming threadripper will be 4 chiplets, 64 pcie lanes, single socket only. All ryzen support ecc.So, what can it offer? At 32 cores, 8 channel memory becomes useful for a lot of workloads. Seems like a lot of professionals would just choose epyc this time. On the other end, I don't think any gamers need more than a 3900x/3950x. Is threadripper just going to be for bragging rights?
quorm - Wednesday, August 7, 2019 - link
Sorry, forgot to add, 3950x is $750, epyc 7302p is $825. Where is threadripper going to fit?