Apple Announces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14
by Andrei Frumusanu on November 10, 2020 3:00 PM EST- Posted in
- Apple
- Apple A14
- Apple Silicon
- Apple M1
From Mobile to Mac: What to Expect?
To date, our performance comparisons for Apple’s chipsets have always been in the context of iPhone reviews, with the juxtaposition to x86 designs being a rather small footnote within the context of the articles. Today’s Apple Silicon launch event completely changes the narrative of what we portray in terms of performance, setting aside the typical apples vs oranges comparisons people usually argument with.
We currently do not have Apple Silicon devices and likely won’t get our hands on them for another few weeks, but we do have the A14, and expect the new Mac chips to be strongly based on the microarchitecture we’re seeing employed in the iPhone designs. Of course, we’re still comparing a phone chip versus a high-end laptop and even a high-end desktop chip, but given the performance numbers, that’s also exactly the point we’re trying to make here, setting the stage as the bare minimum of what Apple could achieve with their new Apple Silicon Mac chips.
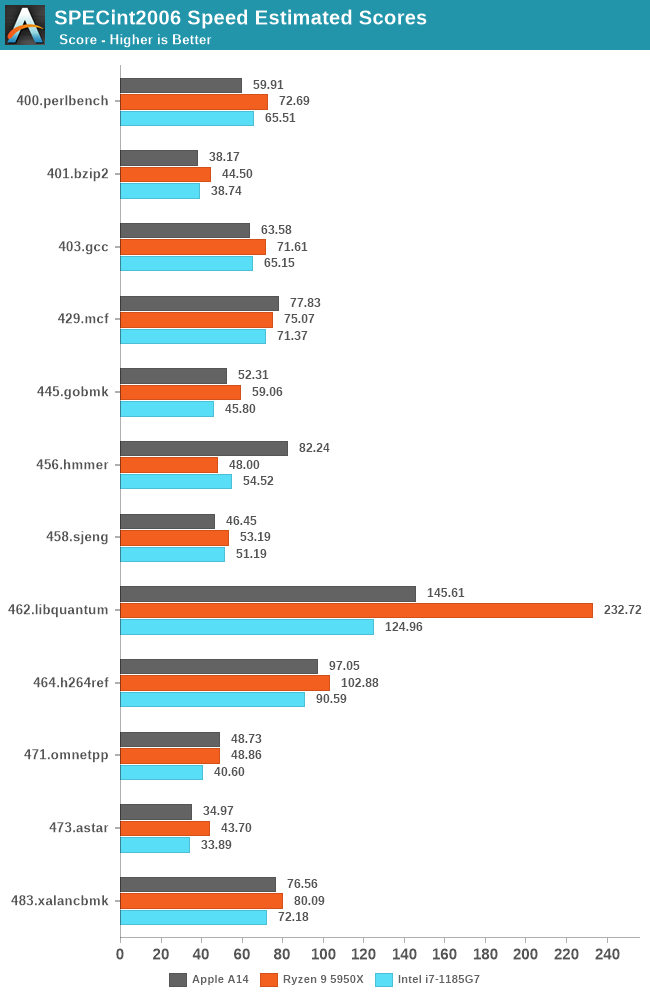
The performance numbers of the A14 on this chart is relatively mind-boggling. If I were to release this data with the label of the A14 hidden, one would guess that the data-points came from some other x86 SKU from either AMD or Intel. The fact that the A14 currently competes with the very best top-performance designs that the x86 vendors have on the market today is just an astonishing feat.
Looking into the detailed scores, what again amazes me is the fact that the A14 not only keeps up, but actually beats both these competitors in memory-latency sensitive workloads such as 429.mcf and 471.omnetpp, even though they either have the same memory (i7-1185G7 with LPDDR4X-4266), or desktop-grade memory (5950X with DDR-3200).
Again, disregard the 456.hmmer score advantage of the A14, that’s majorly due to compiler discrepancies, subtract 33% for a more apt comparison figure.
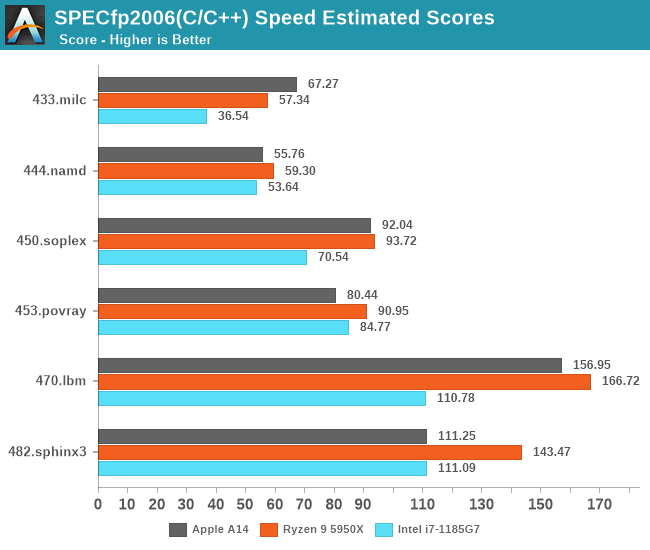
Even in SPECfp which is even more dominated by memory heavy workloads, the A14 not only keeps up, but generally beats the Intel CPU design more often than not. AMD also wouldn’t be looking good if not for the recently released Zen3 design.
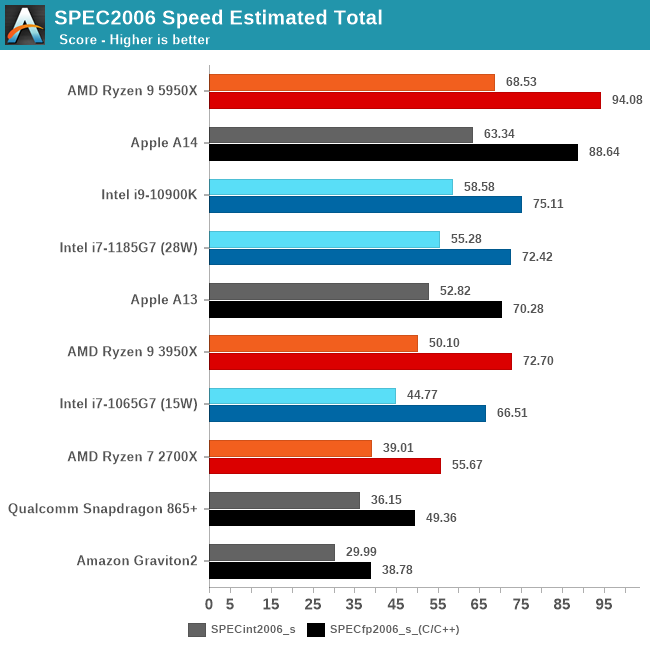
In the overall SPEC2006 chart, the A14 is performing absolutely fantastic, taking the lead in absolute performance only falling short of AMD’s recent Ryzen 5000 series.
The fact that Apple is able to achieve this in a total device power consumption of 5W including the SoC, DRAM, and regulators, versus +21W (1185G7) and 49W (5950X) package power figures, without DRAM or regulation, is absolutely mind-blowing.
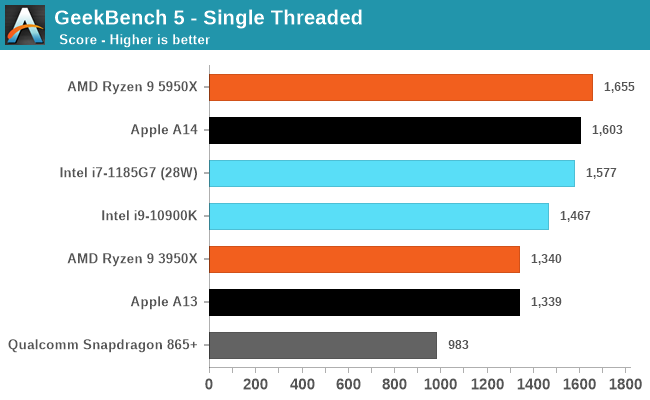
There’s been a lot of criticism about more common benchmark suites such as GeekBench, but frankly I've found these concerns or arguments to be quite unfounded. The only factual differences between workloads in SPEC and workloads in GB5 is that the latter has less outlier tests which are memory-heavy, meaning it’s more of a CPU benchmark whereas SPEC has more tendency towards CPU+DRAM.
The fact that Apple does well in both workloads is evidence that they have an extremely well-balanced microarchitecture, and that Apple Silicon will be able to scale up to “desktop workloads” in terms of performance without much issue.
Where the Performance Trajectory Finally Intersects
During the release of the A7, people were pretty dismissive of the fact that Apple had called their microarchitecture a desktop-class design. People were also very dismissive of us calling the A11 and A12 reaching near desktop level performance figures a few years back, and today marks an important moment in time for the industry as Apple’s A14 now clearly is able to showcase performance that’s beyond the best that Intel can offer. It’s been a performance trajectory that’s been steadily executing and progressing for years:
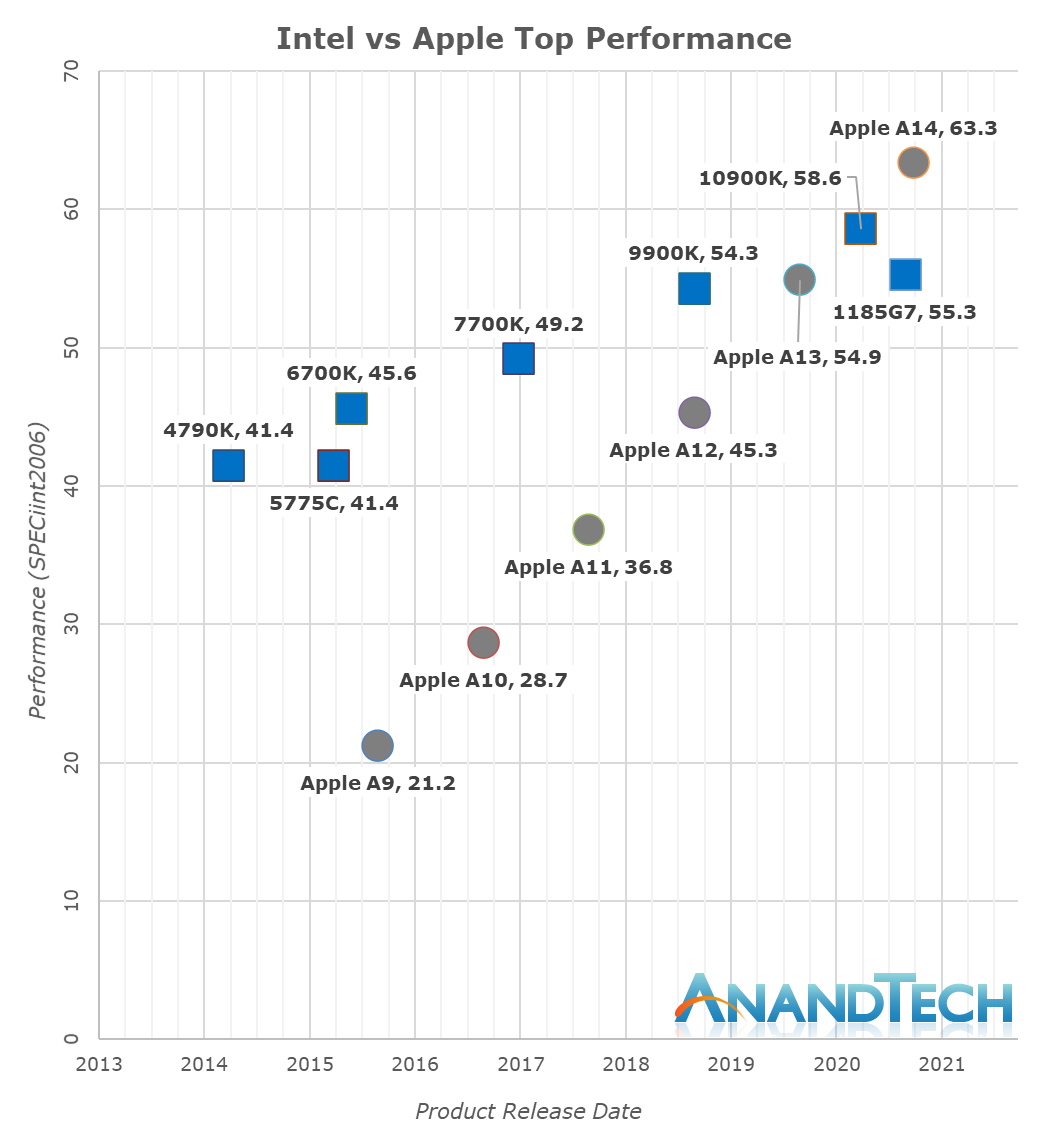
Whilst in the past 5 years Intel has managed to increase their best single-thread performance by about 28%, Apple has managed to improve their designs by 198%, or 2.98x (let’s call it 3x) the performance of the Apple A9 of late 2015.
Apple’s performance trajectory and unquestioned execution over these years is what has made Apple Silicon a reality today. Anybody looking at the absurdness of that graph will realise that there simply was no other choice but for Apple to ditch Intel and x86 in favour of their own in-house microarchitecture – staying par for the course would have meant stagnation and worse consumer products.
Today’s announcements only covered Apple’s laptop-class Apple Silicon, whilst we don’t know the details at time of writing as to what Apple will be presenting, Apple’s enormous power efficiency advantage means that the new chip will be able to offer either vastly increased battery life, and/or, vastly increased performance, compared to the current Intel MacBook line-up.
Apple has claimed that they will completely transition their whole consumer line-up to Apple Silicon within two years, which is an indicator that we’ll be seeing a high-TDP many-core design to power a future Mac Pro. If the company is able to continue on their current performance trajectory, it will look extremely impressive.








644 Comments
View All Comments
mdriftmeyer - Thursday, November 12, 2020 - link
Logic Pro Xvais - Thursday, November 12, 2020 - link
Great article until it reached the benchmark against x86 part.I am amazed how something can claim to be a benchmark and yet leave out what is being measured, what are the criteria, are the results adjusted for power, etc.
Here are some quotes from the article and why they seem to be a biased towards Apple, bordering on fanboyism:
"x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4) that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions"
And who ever said wider is always better, especially in two different instruction sets? Comparing apples to melons here...
"On the ARM side of things, Samsung’s designs had been 6-wide from the M3 onwards, whilst Arm’s own Cortex cores had been steadily going wider with each generation, currently 4-wide in currently available silicon"
Based on that alone would you conclude Exynos is some miracle of CPU design and it somehow comes anywhere close to the performance of a full blown desktop enthusiast grade CPU? Sure hope not.
"outstanding lode/store:
To not surprise, this is also again deeper than any other microarchitecture on the market. Interesting comparisons are AMD’s Zen3 at 44/64 loads & stores, and Intel’s Sunny Cove at 128/72. "
Again comparing different things and drawing conclusions like it's a linear scale. AMD's load/stores are significantly less than Intel's and yes AMD Zen3 CPUs outperform Intel counterparts across the board. I'd say biased as hell...
"AMD also wouldn’t be looking good if not for the recently released Zen3 design."
So comparing yet unreleased core to the latest already available from the competition and somehow the competition is in a bad place as "only" it's latest product is better? Come on...
"The fact that Apple is able to achieve this in a total device power consumption of 5W including the SoC, DRAM, and regulators, versus +21W (1185G7) and 49W (5950X) package power figures, without DRAM or regulation, is absolutely mind-blowing."
I am really interested where those power package figures come from, specifically for the 5950X. AMD's site lists it as 105W TDP. How were the 49W measured?
I've read other articles from Andrei which have been technical, detailed and specific marvels, but this one misses the mark by a long shot in the benchmarks and conclusion parts.
Bluetooth - Thursday, November 12, 2020 - link
They don’t have an actual M1 to test as they say in the artcle. The M1 will be available on the 24th.GeoffreyA - Thursday, November 12, 2020 - link
I think it would be instructive to remember the Pentium 4, which had a lot of "fast" terms for its time: hyper-pipelined this, double pumped ALUs, quad pumped that; but we all know the result. The proof of the pudding is in the eating, or in the field of CPUs, performance, power, and silicon area.AMD and Intel have settled down to 4- and 5-wide decode as the best trade-offs for their designs. They could make it 8-wide tomorrow, but it's likely no use, and would cause disaster from a power point of view.* If Apple wishes to go for wide, good for them, but the CPU will be judged not on "I've got this and that," but on what its final merits.
Personally, I think it's better engineering to produce a good result with fewer ingredients. Compare Z3's somewhat conservative out-of-order structures to Sunny Cove's, but beating it.
When the M1 is on an equal benchmark field with 5 nm x86, then we'll see whether it's got the goods or not.
* Decoding takes up a lot of power in x86, that's why the micro-op cache is so effective (removing fetch and pre/decode). In x86, decoding can't be done in parallel, owing to the varying instruction lengths: one has to determine first how long one instruction is before knowing where the next one starts, whereas in fixed-length ISAs, like ARM, it can be done in parallel: length being fixed, we know where each instruction starts.
Joe Guide - Thursday, November 12, 2020 - link
The benchmarks are coming out, and it looks like the pudding is quite tasty. But you have a good point. When in 2025 or 2026 Intel or AMD releases their newest 5 nm x86, you will be proven to be prophetic that the new Intel chip resoundingly beats the base M1 chip from 5 years ago.GeoffreyA - Thursday, November 12, 2020 - link
That line about the M1 and 5 nm is silly on my part, I'll admit. Sometimes we write things and regret it later. Also, if you look at my comment from the other day, you'll see the first thing I did was acknowledge Apple's impressive work on this CPU. The part about the Pentium 4 and the pudding wasn't in response to the A14's performance, but this whole debate running through the comments about wide vs. narrow, and so I meant, "Wide, narrow, doesn't mean anything. What matters is the final performance."I think what I've been trying to say, quite feebly, through the comments is: "Yes, the A14 has excellent performance/watt, and am shocked how 5W can go up against 105W Ryzen. But, fanboy comment it may be, I'm confident AMD and Intel (or AMD at any rate) can improve their stuff and beat Apple."
Joe Guide - Thursday, November 12, 2020 - link
I see this as glass half full. There was been far too much complacency in the CPU development over the last decade. If it take Apple to kick the industry in the butt, well then, how is that bad.Moore's Law has awoke after a deep slumber and it is hungry and angry. Run Intel. Run for your life.
GeoffreyA - Friday, November 13, 2020 - link
Agreed, when AMD was struggling, Intel's improvements were quite meagre (Sandy Bridge excepted). Much credit must be given to AMD though. Their execution of the past few years has been brilliant.chlamchowder - Friday, November 13, 2020 - link
In x86, decoding is very much done in parallel. That's how you get 3/4/5-wide decoders. The brute force method is to tentatively start decoding at every byte. Alternatively, you mark instruction boundaries in the instruction cache (Goldmont/Tremont do this, as well as older AMD CPUs like Phenom).GeoffreyA - Saturday, November 14, 2020 - link
Thanks for that. I'm only a layman in all this, so I don't know the exact details. I did suspect there was some sort of trick going on to decode more than one at a time. Marking instructions boundaries in the cache is quite interesting because it ought to tone down, or even eliminate, x86's variable length troubles. Didn't know about Tremont and Goldmont, but I was reading that the Pentium MMX, as well as K8 to Bulldozer, perhaps K7 too, used this trick.My question is, do you think AMD and Intel could re-introduce it (while keeping the micro-op cache as well)? Is it effective or does it take too much effort itself? I ask because if it's worth it, it could help x86's length problem quite a bit, and that's something which excites me, under this current climate of ARM. However, judging from the results, it didn't aid the Athlon, Phenom, and Bulldozer that drastically, and AMD abandoned it in Zen, going for a micro-op cache instead, so that knocks down my hopes a bit.