Investigating Performance of Multi-Threading on Zen 3 and AMD Ryzen 5000
by Dr. Ian Cutress on December 3, 2020 10:00 AM EST- Posted in
- CPUs
- AMD
- Zen 3
- X570
- Ryzen 5000
- Ryzen 9 5950X
- SMT
- Multi-Threading
Power Consumption, Temperature
Two other arguments for having SMT enabled or disabled comes down to power consumption and temperature.
With SMT enabled, the core utilization is expected to be higher, with more instructions flowing through and being processed per cycle. This naturally increases the power requirements on the core, but might also reduce the frequency of the core. The trade-off is meant to be that the work going through the core should be more than enough to make up for extra power used, or any lower frequency. The lower frequency should enable a more efficient throughput, assuming the voltage is adjusted accordingly.
This is perhaps where AMD and Intel differ slightly. Intel’s turbo frequency range is hard-bound to specific frequency values based on core loading, regardless of how many threads are active or how many threads per core are active. The activity is a little more opportunistic when we reach steady state power, although exactly how far down the line that is will depend on what the motherboard has set the power length to. AMD’s frequency is continually opportunistic from the moment load is applied: it obviously scales down as more cores are loaded, but it will balance up and down based on core load at all times. On the side of thermals, this will depend on the heat density being generated in each core, but this also acts as a feedback loop into the turbo algorithm if the power limit has not been reached.
For our analysis here, we’ve picked two benchmarks. Agisoft, which is a variable threaded test performs practically the same with SMT On/Off, and 3DPMavx, a pure MT test which gets the biggest gain from SMT.
Agisoft
Photoscan from Agisoft is a 2D image to 3D model creator, using dozens of high-quality 2D images to generate related point maps to form a 3D model, before finally texturing the model using the images provided. It is used in archiving artefacts, as well as converting 2D sculpture into 3D scenes. Our test analyses a standardized set of 85 x 18 megapixel photos, with a result measured in time to complete.

Simply looking at CPU temperatures while running our real-world Agisoft test, our current setup (MSI X570 Godlike with Noctua NH12S) shows that both CPUs will flutter around 74ºC sustained. Perhaps the interesting element is at the beginning of the test, where the CPU temperatures are higher in SMT Off mode. Looking into the data, and during SMT Off, the processor is at 4300 MHz, compared to 4150 MHz when SMT is enabled. This would account for the difference.
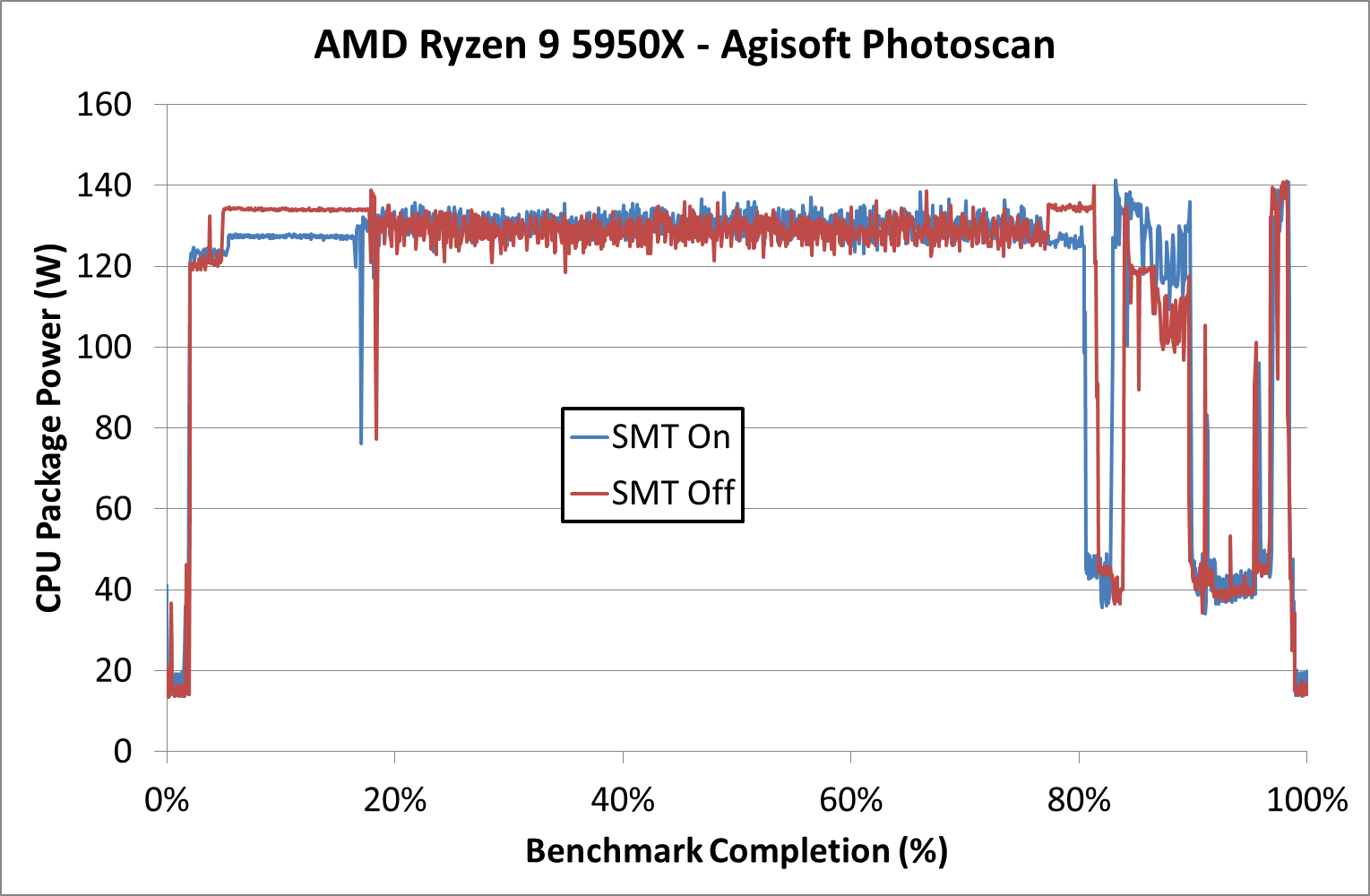
Looking at power, we can follow that for the bulk of the test, both processors have similar package power consumption, around 130 W. The SMT Off is drawing more power during the first couple of minutes of the test, due to the higher frequency. Clearly the thermal density in this part of the test by only having one thread per core is allowing for a higher turbo.
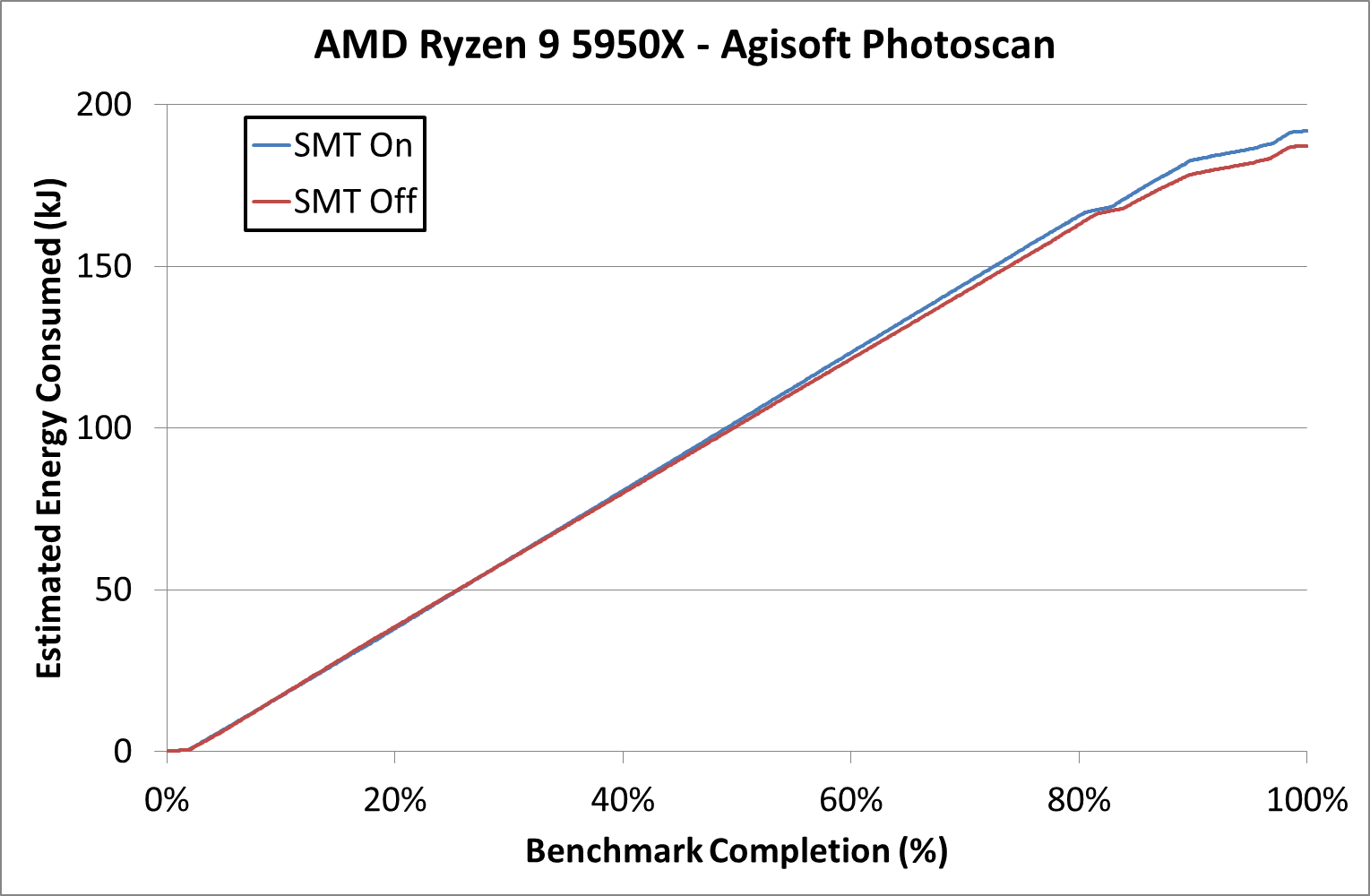
If we measure the total power of the test, it’s basically identical in any metric that matters. Nearer the end of the test, where the workload is more variably threaded, this is where the SMT Off mode seems to come under power. This benchmark completion time is essentially the same due to the nature of the test, but SMT Off comes in at 2% lower power overall.
3DPMavx (3D Particle Movement)
Our 3DPM test is an algorithmic sequence of non-interactive random three-dimensional movement, designed to simulate molecular diffusive movement inside a gas or a fluid. The simulation is made non-interactive (i.e. no two molecules will collide) due to the original average movement of each particle taking collisions into account. Our test cycles through six movement algorithms at ten seconds apiece, followed by ten seconds of idle, with the whole loop being repeated six times, taking about 20 minutes, regardless of how fast or slow the processor is. The related performance figure is millions of particle movements per second. Each algorithm has been accelerated for AVX2.
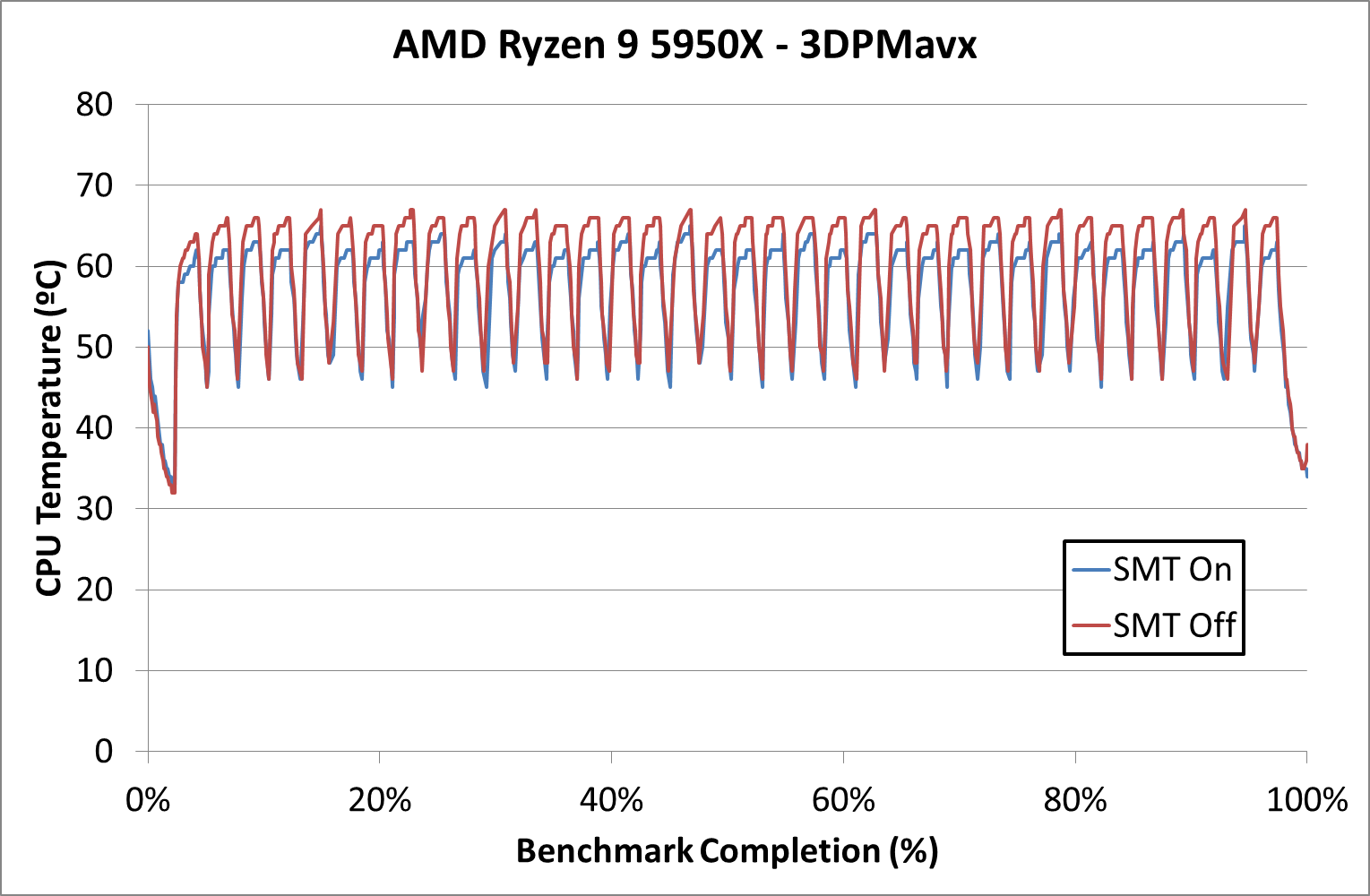
On the temperature side of things, it is clear that the SMT Off mode again puts up a higher thermal profile. Temperatures this time peak at 66ºC, but it is clear the difference between the two modes.
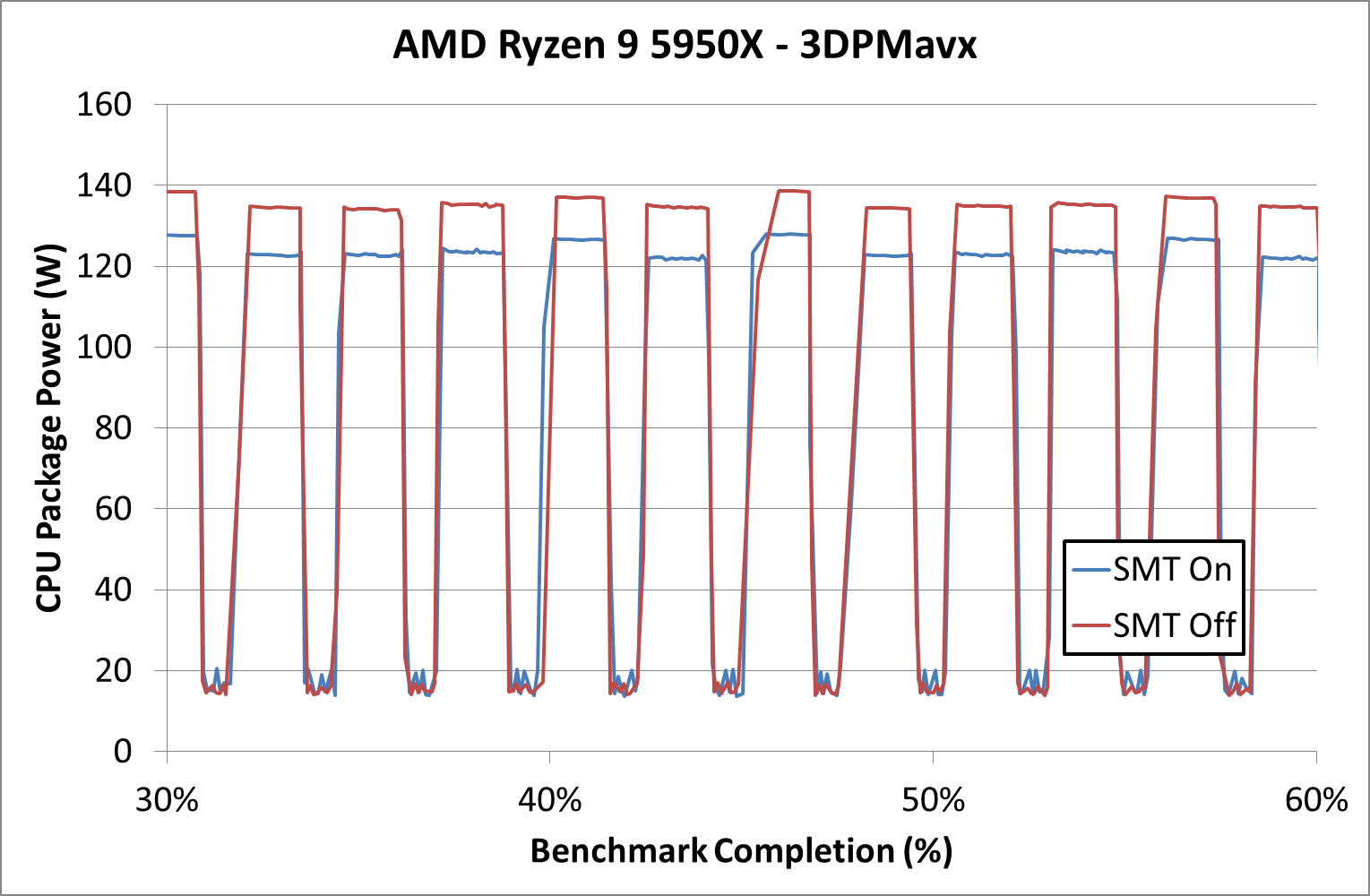
On the power side, we can see why SMT Off mode is warmer – the cores are drawing more power. Looking at the data, SMT Off mode is running ~4350 MHz, compared to SMT On which is running closer to 4000 MHz.
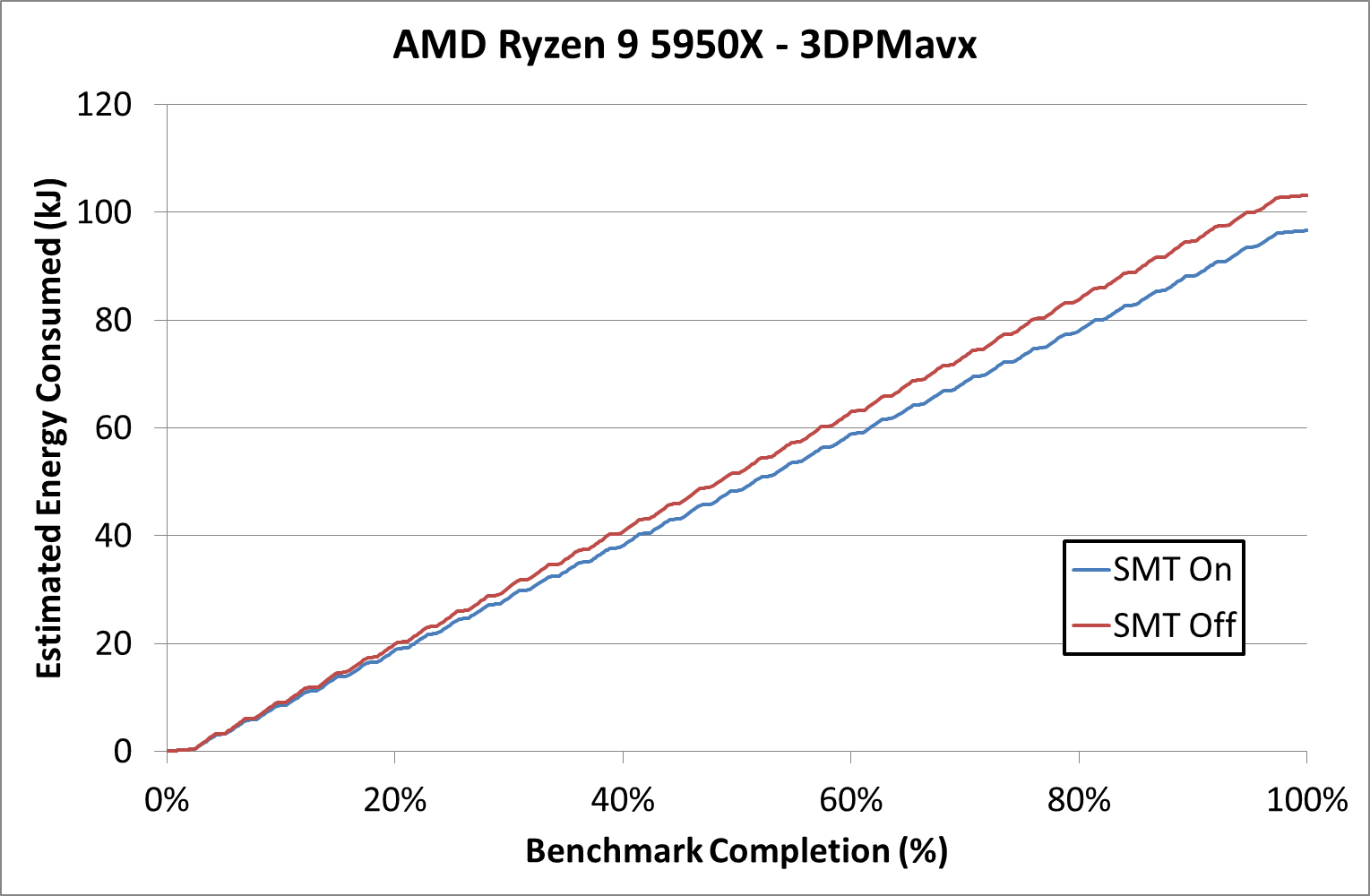
With the higher frequency with SMT Off, the estimated total power consumption is 6.8% higher. This appears to be very constant throughout the benchmark, which lasts about 20 minutes total.
But, let us add in the performance numbers. Because 3DPMavx can take advantage of SMT On, that mode scores +77.5% by having two threads per core rather than one (a score of 10245 vs 5773). Combined this makes SMT On mode +91% better in performance per watt on this benchmark.








126 Comments
View All Comments
GeoffreyA - Tuesday, December 8, 2020 - link
There's a single set of 4 decoders. In SMT mode, I believe some sharing is going in. This is from the original Zen design:https://images.anandtech.com/doci/10591/HC28.AMD.M...
GeoffreyA - Tuesday, December 8, 2020 - link
* going onnaive dev - Wednesday, December 9, 2020 - link
Right, I found that article as well and from that slide it looks like the decoder would be shared. But then that slide was from 2017, so that might have changed.It looks though as if the decoder could decode those 4 instructions from a single program counter only, right? It's not like the decoder could decode e.g. 2 instructions from program counter 1 and another 2 instructions from program counter 2?
GeoffreyA - Thursday, December 10, 2020 - link
I'm not too sure how the implementation works, but I expect they're shuffling both threads through the decoder at roughly the same time. The decoder has four units (I think 1 complex and 3 simple). As far as I'm aware, that has stayed the same in both Zen 2 and 3.mapesdhs - Thursday, December 10, 2020 - link
Ian, a question about Handbrake, though it may not apply to the type of test you used. I've read that Handbrake doing an h264 encode can only use 16 threads max. Does this mean that in theory one could run two separate h264 encodes on a 5950X and thus obtain a good overall throughput speedup? Have you tried such a thing? Or might this only work if it were possible to force one encode to only use the 16 threads of one 8c block (CCX?), and the other encode to use the rest? ie. so that the separate encodes are not fighting over the same cores or indeed the same CCX-shared L3? Is it possible to force this somehow? Also, if the claimed 16 thread limit for h264 is true, is there a performance difference for a single h264 encode between SMT on vs. off just in general? ie. with it on, is the OS smart enough to ensure that the 16 threads are spread across all the cores evenly rather than being scrunched onto fewer cores because reasons? If not, then turning SMT off might speed it up. Note that I'm using Windows for all this.I don't know if any of this applies to h265, but atm the encoding I do is still 1080p. I did an analysis of all available Ryzen CPUs based on performance, power consumption and cost (I ruled out Intel partly due to the latter two factors but also because of a poor platform upgrade path) and found that although the 5900X scored well, overall it was beaten by the 2700X, mainly because the latter is so much cheaper. However, the 5950X would look a lot better if one could run two encodes on it at the same time without clashing, but review articles naturally never try this. I wish I could test it, but the only 16c system I have is a dual-socket S2011 setup with two 2560 v2s, so the separate CPUs introduce all sorts of other issues (NUMA and suchlike).
I found something similar a long time ago when I noticed one could run six separate Maya frame renders on a 24-CPU SGI rack Onyx (essentially one render per CPU board), compared to running a single render on a quad-CPU (single board) deskside Onyx, giving a good overall throughput increase (the renderer being limited to 4 CPUs per job). See:
http://www.sgidepot.co.uk/perfcomp_RENDER4_maya1.h...
Funny actually, re what you say about an overly good speedup perhaps implying a less than optimal core design. Something odd about SGIs is how many times on a multi CPU system one can btain better results by using more threads than there are CPUs, baring in mind MIPS CPUs from that era did not have SMT, ie. the CPUs kinda behave as if they do have SMT even though they don't. I found this behaviour occured most for Blender and C-Ray.
So anyway, it would be great if it were possible to run two h264 encodes on a 5950X at the same time, but there's probably no point if the OS doesn't spread out the loads in a sensible manner, or if in that circumstance there isn't a way to force each encode to use a separate CCX.
All very specific to my use case of course, but I have hundreds of hours of material to convert, so the ability to get twice the throughput from a 5950X would make that CPU a lot more interesting; so far reviews I've read show it to be about 2x faster than the 2700X for h264 Handbrake (just one encode of course), but it costs 4.4x more, rather ruining the price/performance angle. And if it does work then I guess one could ask the same question of TR - could one run eight separate h264 encodes on a future Zen3 TR without the thread management being a total mess? :D I'm assuming it probably wouldn't be so good with the older Zen2 design given the split L3.
GeoffreyA - Sunday, December 13, 2020 - link
Interesting question. Would be nice if someone could give this a test on 16-core Ryzen or TR, and see what happens. Yesterday, I was able to take both FFmpeg and Handbrake up to 128 threads, and it does work; but, having only a 4-core, 4-thread CPU, can't comment.*As for x264's performance limit, I'm not sure at what number of threads it begins to flag; but, quality wise, using too many (say, over 16 at 1080p) is not advisable. According to the x264 developers, vertical resolution / threads shouldn't fall below 40-50 and certainly not below 30.
https://forum.doom9.org/showthread.php?p=1213185#p...
forum.doom9.org/showthread.php?p=1646307#post1646307
More posts on high core counts:
forum.doom9.org/showthread.php?t=173277
forum.doom9.org/showthread.php?t=175766
* As far as I know, Windows schedules threads all right. From 1903, on Zen 2, one CCX is supposed to be filled up, then another. I imagine 16 threads will be spread across two CCXs in the 5950X. FFmpeg's --threads switch could prove useful too.
GeoffreyA - Sunday, December 13, 2020 - link
-threads, not --threadsHere are links set out better (thought they'd link in the comment):
https://forum.doom9.org/showthread.php?p=1213185#p...
https://forum.doom9.org/showthread.php?p=1646307#p...
https://forum.doom9.org/showthread.php?t=173277
https://forum.doom9.org/showthread.php?t=175766
karthikpal - Friday, December 11, 2020 - link
Nice content bro<a href="https://www.tronicsmaster.com">Ryzen 7 5800X</a>
deil - Sunday, December 13, 2020 - link
I wonder when smt4 will hit the market a model with 3 copies of most things on the die, in a ring configuration fp/int/fp/int, cache inside a ring st would have a chance to use 2 FP modules for single int processor part (when others don't use it ofc).This kind of setup would have very interesting performance numbers at least. I am not saying it's a good idea, but interesting one for sure.
Machinus - Sunday, December 13, 2020 - link
This article omits one of the basic considerations in any manually-configured and custom-cooled desktop system: achieving uniform, preditcable thermal behavior. Unless you are building servers to perform only one or two specific types of mathematical operations, and can build, configure, and stress test on those instruction types alone, you need high confidence that the chip will never exceed the thermal flux densities of the cooling system you built. Fixed-clock systems with a static number of available cores have much more consistent thermal performance than chips whose clocks, and number of threads, are free-floating. This reduces your peak flops, but it significantly extends system lifetime. HEDT and HPC systems have double or triple-digit coure counts per sockrt in 2020; SMT is not worth paying the price of reduced hardware lifetime unless you are building extremely specialized calculation servers.