The Intel SSD 670p (2TB) Review: Improving QLC, But Crazy Pricing?!?
by Billy Tallis on March 1, 2021 12:00 PM ESTBurst IO Performance
Our burst IO tests operate at queue depth 1 and perform several short data transfers interspersed with idle time. The random read and write tests consist of 32 bursts of up to 64MB each. The sequential read and write tests use eight bursts of up to 128MB each. For more details, please see the overview of our 2021 Consumer SSD Benchmark Suite.
 |
|||||||||
| Random Read | Random Write | ||||||||
| Sequential Read | Sequential Write | ||||||||
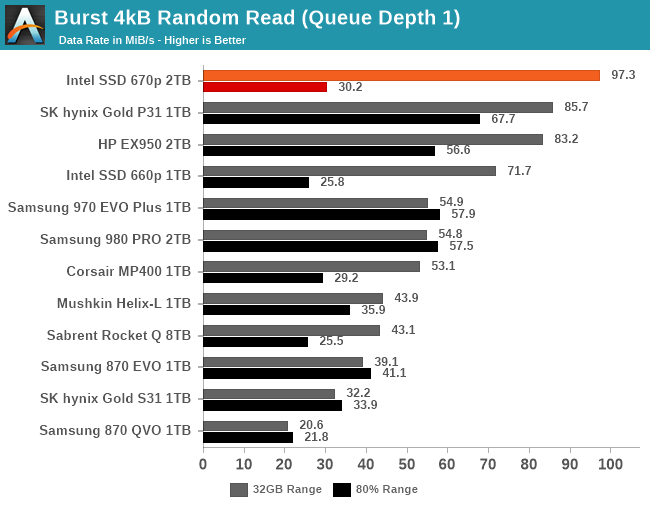
For quite a while, NVMe SSDs with Silicon Motion controllers have been delivering some of the best QD1 burst random read performance scores. The Intel SSD 670p pushes this even further, when the test is only hitting the SLC cache. When testing against an 80% full drive, the burst random read performance is faster than most other QLC drives but slower than any good TLC drive.
For QD1 random writes, the 670p is actually slightly slower than the 660p when testing a mostly-full drive, though it is again competitive with more high-end TLC drives when writing to the SLC cache. For both sequential reads and sequential writes, the 670p offers very good QD1 throughput for a PCIe 3.0 drive, and is much improved over the 660p that is seriously bottlenecked by its low-end controller.
Sustained IO Performance
Our sustained IO tests exercise a range of queue depths and transfer more data than the burst IO tests, but still have limits to keep the duration somewhat realistic. The primary scores we report are focused on the low queue depths that make up the bulk of consumer storage workloads. For more details, please see the overview of our 2021 Consumer SSD Benchmark Suite.
 |
|||||||||
| Random Read | Throughput | Power | Efficiency | ||||||
| Random Write | Throughput | Power | Efficiency | ||||||
| Sequential Read | Throughput | Power | Efficiency | ||||||
| Sequential Write | Throughput | Power | Efficiency | ||||||
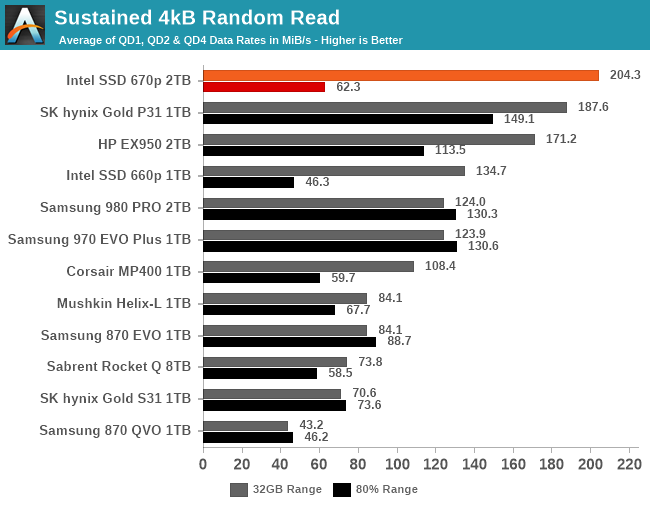
As with the burst IO scores, the longer sustained IO tests show the Intel 670p doing very well with sequential reads or writes: the performance doesn't betray the fact that it's using QLC NAND, and the power efficiency is typical of a last-generation controller. For random reads or writes, the performance at low queue depths is similarly great when testing the SLC cache, but testing across an 80% full drive knocks performance down to typical entry-level NVMe and mainstream SATA territory. Random writes in particular are disappointing on the mostly-full drive: it's slower than the 660p and the Phison E12-based Corsair MP400, though still several times faster than the DRAMless Mushkin Helix-L.
 |
|||||||||
| Random Read | |||||||||
| Random Write | |||||||||
| Sequential Read | |||||||||
| Sequential Write | |||||||||
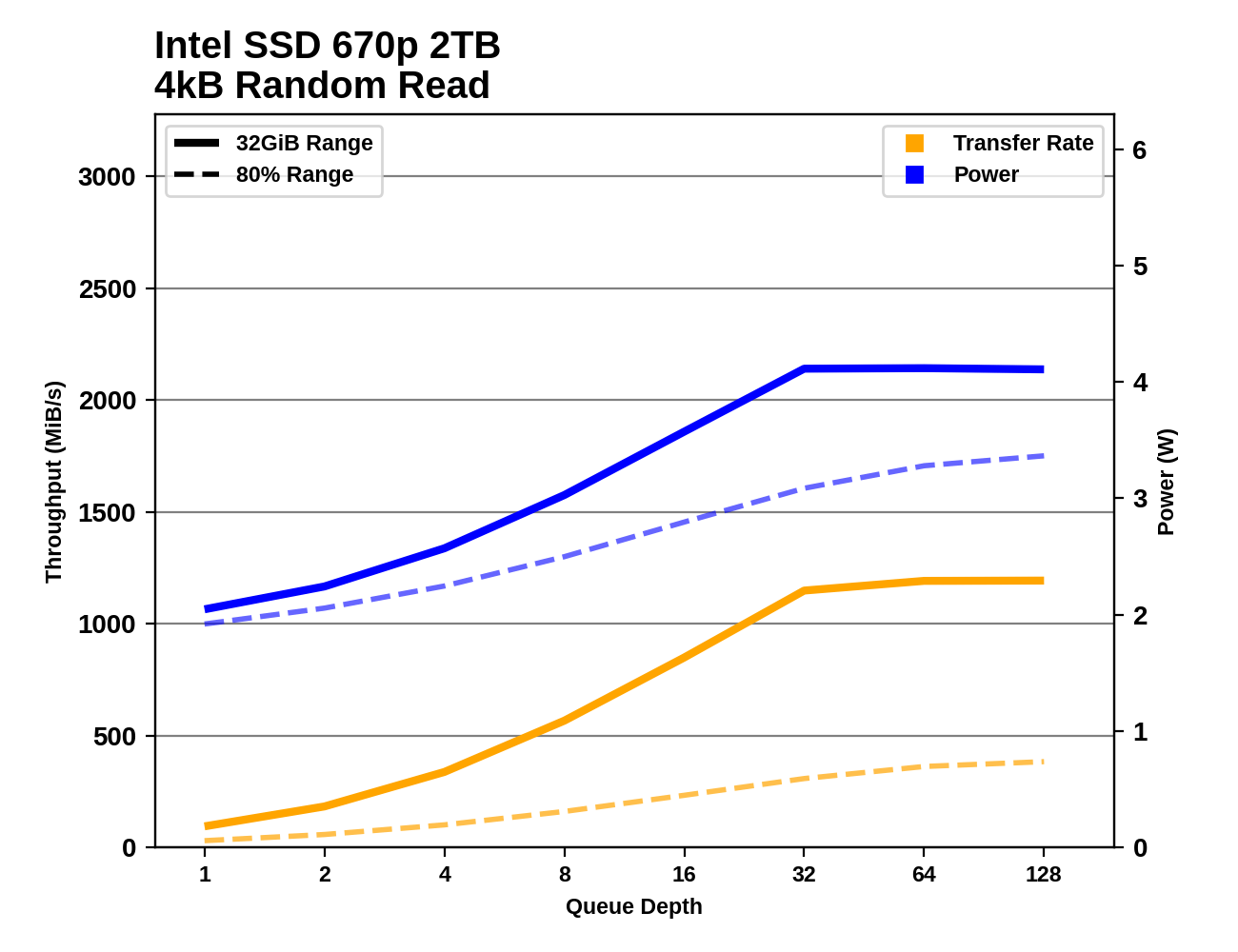
The Intel 670p is fairly well-behaved through the sustained IO tests as the queue depth ramps up. Random reads saturate around QD32, random writes around QD8, and sequential transfers at QD2. Performance is very consistent after the drive reaches its full speed; the only big drop comes at the very end of the sequential write test on a mostly-full drive, when the SLC cache finally runs out while testing at QD128. This is pretty much never going to happen during ordinary consumer workloads.
Random Read Latency
This test illustrates how drives with higher throughput don't always offer better IO latency and Quality of Service (QoS), and that latency often gets much worse when a drive is pushed to its limits. This test is more intense than real-world consumer workloads and the results can be a bit noisy, but large differences that show up clearly on a log scale plot are meaningful. For more details, please see the overview of our 2021 Consumer SSD Benchmark Suite.
 |
|||||||||
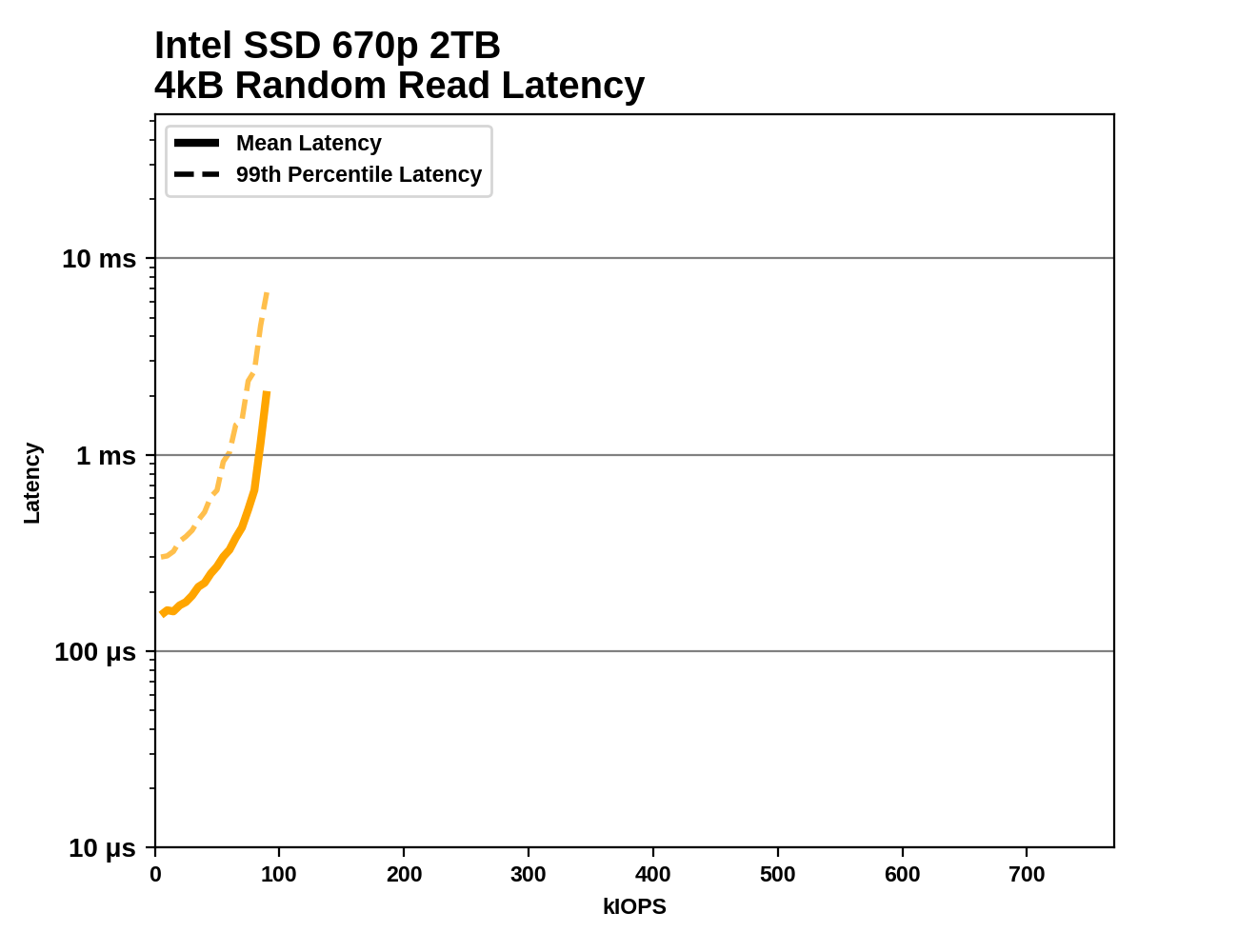
Taking a closer look at random read throughput and latency, the Intel 670p fares better than most of the other QLC drives, save for the 8TB Sabrent Rocket Q. The 670p has slightly worse performance than the DRAMless TLC Mushkin Helix-L. The throughput achieved by the 670p is similar to mainstream TLC SATA drives, but the latency is considerably higher: the SATA drives are bottlenecked by the SATA link itself, while the 670p's bottleneck is on the NAND side, which causes latency to spike as the drive is pushed to its limit.








72 Comments
View All Comments
Wereweeb - Tuesday, March 2, 2021 - link
What are you smoking? Four bits per cell is indeed 33% more bits per cell than three bits per cell.Bp_968 - Tuesday, March 2, 2021 - link
He's smoking "math". Lol. 3 bits per cell is 8 voltage states, and 4 bits per cell is 16 voltage states, which is double. If your going to comment with authority on an advanced subject you should learn the basics, and binary math is one of the basics.bug77 - Tuesday, March 2, 2021 - link
Yeah, it doesn't work like that.3 bits is 3 bits. They hold 8 possible combinations, but they're independent of each other.
4 bits is 33% more than 3.
Billy Tallis - Tuesday, March 2, 2021 - link
3 bits per cell is 8 POSSIBLE voltage states, but any given cell can only exist in one of those states at a time. The possible voltage states are not the cell's data storage capacity. The number of bits per cell is the cell's data storage capacity.FunBunny2 - Tuesday, March 2, 2021 - link
"3 bits per cell is 8 POSSIBLE voltage states, but any given cell can only exist in one of those states at a time."which incites a lower brain stem question: does NAND and/or controllers implement storage with a coding along the lines of RLL or s/pdif (eliminate long 'strings' of either 1 or 0) in order to lower the actual voltages required? if only across logically concatenated cells, so 1,000,000 would store as 1,00X where X is interpreted as 4 0? I can't think of a way off the top of my head, but there must be some really smart engineer out there who has?
code65536 - Tuesday, March 2, 2021 - link
Um, voltage states are not storage--it's instead a measure of the difficulty of storing that many bits. QLC is 4 bits per cell, and needs to be able to discern 16 voltage states to store those 4 bits. TLC needs to discern only 8 stages in order to store 3 bits. What that means is that QLC stores 33% more data at the expense of 100% more difficulty. Each bit added doubles the difficulty of working with that data. SLC->MLC was 100% more difficulty for 100% more storage. MLC->TLC was 100% more difficulty for 50% more storage. TLC->QLC was 100% more difficulty for 33% more storage. And QLC->PLC will be 100% difficulty for only 25% more storage.Spunjji - Thursday, March 4, 2021 - link
I think at this stage it's also worse than double the difficulty - the performance and endurance penalties are very, very high.HarryVoyager - Monday, March 8, 2021 - link
The 660p initially showed a significant price advantage; I was able to get a 2TB at $180, but it has since disappeared.That said, in day to day practical use, I haven't seen much difference between a 860 Pro, the 660p and an XPG Gamix X7.
All of them have been considerable faster than my harddrives, and pretty much all of them can feed data faster than my CPUs or network can process it.
I know at some point that will change, and we will see games and consumer software designed to take advantage of the sort of data rates that NVME SSDs can provide, but I'll likely get a dedicated NVME drive for that, when that day comes.
RSAUser - Tuesday, March 2, 2021 - link
No one who looked at the actual daily write warranty said that.I've never had a TLC drive file as a host OS drive, only the two times I bought a QLC one after two years.
So my Motto is TLC for host, QLC for mass storage.
yetanotherhuman - Tuesday, March 2, 2021 - link
Nope, in my mind TLC is still a cheap toy, fit for a less important machine or maybe a games drive. MLC, 2-bit per cell, is still the right way to go, and QLC is so shit that it should be given away in cereal boxes.