Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse V1 Microarchitecture: Platform Enhancements
Aside from the core-side microarchitectural aspects of the V1, the new design also features some new system-facing novelties that promise to help vendors integrate the CPU IP better in larger scale implementations.
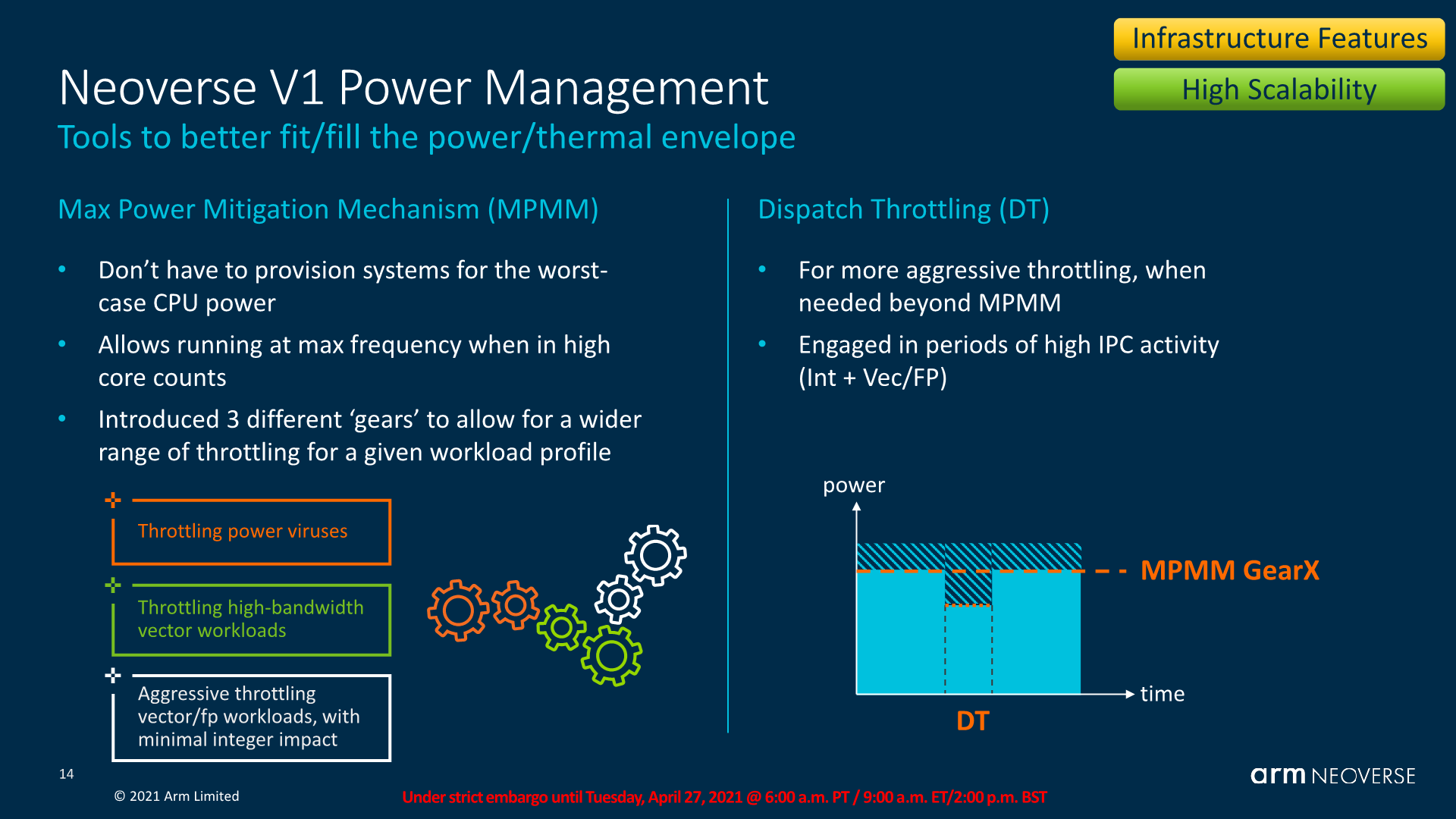
MPAM, or Max Power Mitigation Mechanism is a new fine-grained (to around 100 clock cycles) power management mechanism that promises to help smooth out the power behaviour of the core, and allow vendors’ implementations of the chip’s power delivery mechanisms to be so to say, be built to lesser requirements.
As we’ve seen in our review of the Ampere Altra, instead of fluctuating frequency at maximum TDP like how most x86 CPUs behave right now, the chip rather prefers to stay most of the time at maximum frequency, with the actual power consumption many times landing in at quite below the TDP (maximum allowed power consumption). A mechanism such as MPAM would allow, if possible, for the system’s average frequency to be higher by throttling the power limited cores to a finer degree. The mechanism to which this can be achieved can also include microarchitectural features such as dispatch throttling where the core slows down the dispatched instructions, smoothing out high power requirements in workloads having high execution periods, particularly important now with the new wider 2x256b SVE pipelines for example.

MPAM is a different mechanism helping interactions in larger system implementations. The Memory partitioning and monitoring feature is supposed to help with quality of service and reducing side-effects of noisy neighbours in deployments where multiple workloads, such as multiple VMs or processes, operate on the same system. This naturally requires software-hardware cooperation and implementation, but should be something that is particularly helpful in cloud environments.
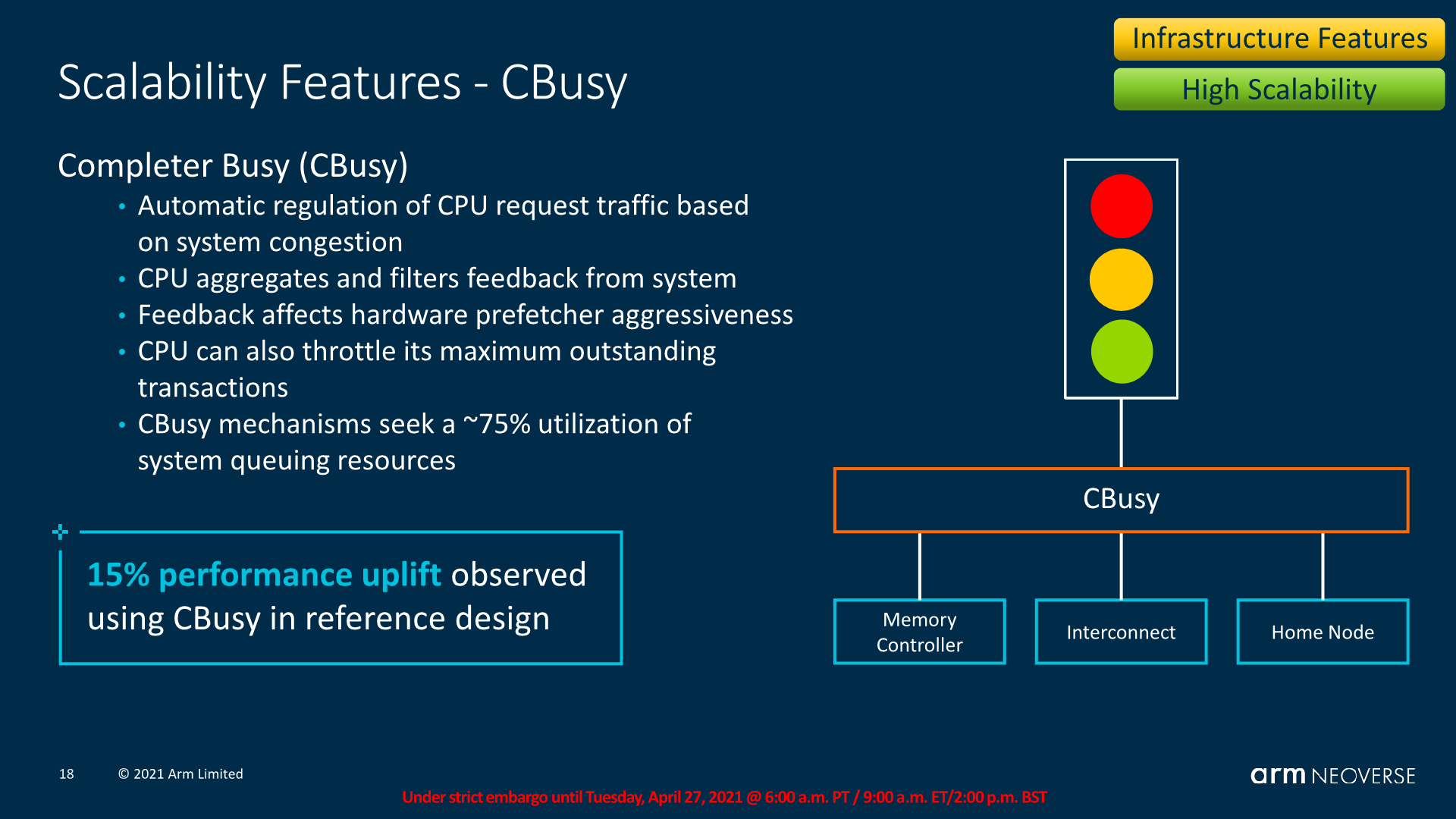
CBusy or Completer Busy is also a new system-side mechanism where the CPU cores interact with the mesh interconnect on a feedback-based basis, where the CPUs can vary their memory prefetcher aggressiveness depending on the overall mesh and system memory load. This ties in with the previously mentioned dynamic prefetcher behaviour where one can have the best of both worlds – better prefetching for more performance per core when the bandwidth is available, and very conservative prefetching when the system is under high load and there’s no room for wasted speculative bandwidth and data transfers.








95 Comments
View All Comments
michael2k - Tuesday, April 27, 2021 - link
Maybe dotjaz meant you couldn't mix 8.5 and 8.2 architectures?In any case, DynamIQ, not big.LITTLE, is more relevant now. Also, if people really want to push for an out of order big.LITTLE, why not use the A78 for the big core and the older A76 as the little core? Both A76 and A78 can be fabricated at 5nm, and the A76 would use less power by dint of being able to do less work per clock, which is fine for the kind of work a little core would do anyway.
Does DynamIQ allow for a mix of A76 and A78?
smalM - Thursday, April 29, 2021 - link
Yes.But the maximum is 4 A7x Cores. Only A78C can scale to 8 Cores in one DynamIQ cluster.
dotjaz - Thursday, April 29, 2021 - link
No, big.LITTLE is the correct term. DynamIQ is an umbrella term. The part related to mixing uarch is still b.L, nothing has changed.https://community.arm.com/developer/ip-products/pr...
dotjaz - Thursday, April 29, 2021 - link
And yes, I mean what I wrote, architectures or ISA, not uarch.dotjaz - Thursday, April 29, 2021 - link
Name one example where ARCHITECTURES were mixed. Microarchitectures are of course mixed, otherwise it won't be b.LZingam - Wednesday, April 28, 2021 - link
Do you remember the forum experts taunting that Intel is so much better and arm so weak, it will never be competitive?Matthias B V - Tuesday, April 27, 2021 - link
Thanks for asking. Can't watch it a for years small A55 didn't get any update or successor.For me it would be even more improtant to update those as lots of tasks run on those rather than high perfromance cores. But I guess it is just better for marketing talk about big gains in theoretical pefromance.
At least I expect an update now. Just hope it won't be the only one...
SarahKerrigan - Tuesday, April 27, 2021 - link
The lack of deep uarch details on the N2 is disappointing, but I guess we'll probably see what Matterhorn looks like in a few weeks so not a huge deal.eastcoast_pete - Tuesday, April 27, 2021 - link
I am waiting for the first in-silicone V1 design that Andrei and others can put through its paces. N2 is quite a while away, but yes, maybe we'll see a Matterhorn design in a mobile chip in the next 12 months. As for V1, I am curious to learn what, if anything, Microsoft has cooked up. They've been quite busy trying to keep up with AWS and it's Gravitons.mode_13h - Tuesday, April 27, 2021 - link
> in-siliconeJust picturing a jiggly, squidgy CPU core... had to LOL at that!