Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM EST
This week Intel held its annual Architecture Day event for select press and partners. As with previous iterations, the company disclosed details about its next generation architectures set to come to the market over the next twelve months. Intel has promised the release of its next-generation consumer and mobile processor family, Alder Lake, to come by the end of the year and today the company is sharing a good number of details about the holistic design of the chips as well as some good detail about the microarchitectures that form this hybrid design: Golden Cove and Gracemont. Here is our analysis of Intel’s disclosure.
Alder Lake: Intel 12th Gen Core
As mentioned in previous announcements, Intel will launch its Alder Lake family of processors into both desktop and mobile platforms under the name of Intel’s 12th Gen Core Processors with Hybrid Technology later this year. This is Intel’s second generation hybrid architecture built on Intel 7 process node technology. The hybrid design follows Intel Lakefield designs for small notebooks launched last year. The nature of a hybrid design in Intel nomenclature involves having a series of high ‘Performance’ cores paired with a number of high ‘Efficiency’ cores. Intel has simplified this into P-core and E-core terminology.
For Alder Lake, the processor designs feature Performance cores based on a new Golden Cove microarchitecture, and Efficiency cores based on a new Gracemont architecture. We will cover both over the course of this article, however the idea is that the P-core is preferential for single threaded tasks that require low latency, and the E-core is better in power limited or multi-threaded scenarios. Each Alder Lake SoC will physically contain both, however Intel has not yet disclosed the end-user product configurations.

Each of the P-cores has the potential to offer multithreading, whereas the E-cores are one thread per core. This means there will be three physical designs based on Alder Lake:
- 8 P-core + 8 E-core (8C8c/24T) for desktop on a new LGA1700 socket
- 6 P-core + 8 E-core (6C8c/20T) for mobile UP3 designs
- 2 P-core + 8 E-core (2C8c/12T) for mobile UP4 designs
Intel typically highlights UP4 mobile designs for very low power installs, down to 9 W, whereas UP3 can cover anything from 12 W to 35 W (or perhaps higher), but when asked about the power budgets for these processors, Intel stated that more detail will follow when product announcements are made. Intel did confirm that the highest client power, presumably on the desktop processor, will be 125 W.
Highlighted in our discussions is how modular Intel has made Alder Lake. From a range of base component options, the company mixed and matched what it felt were the best combination of parts for each market.
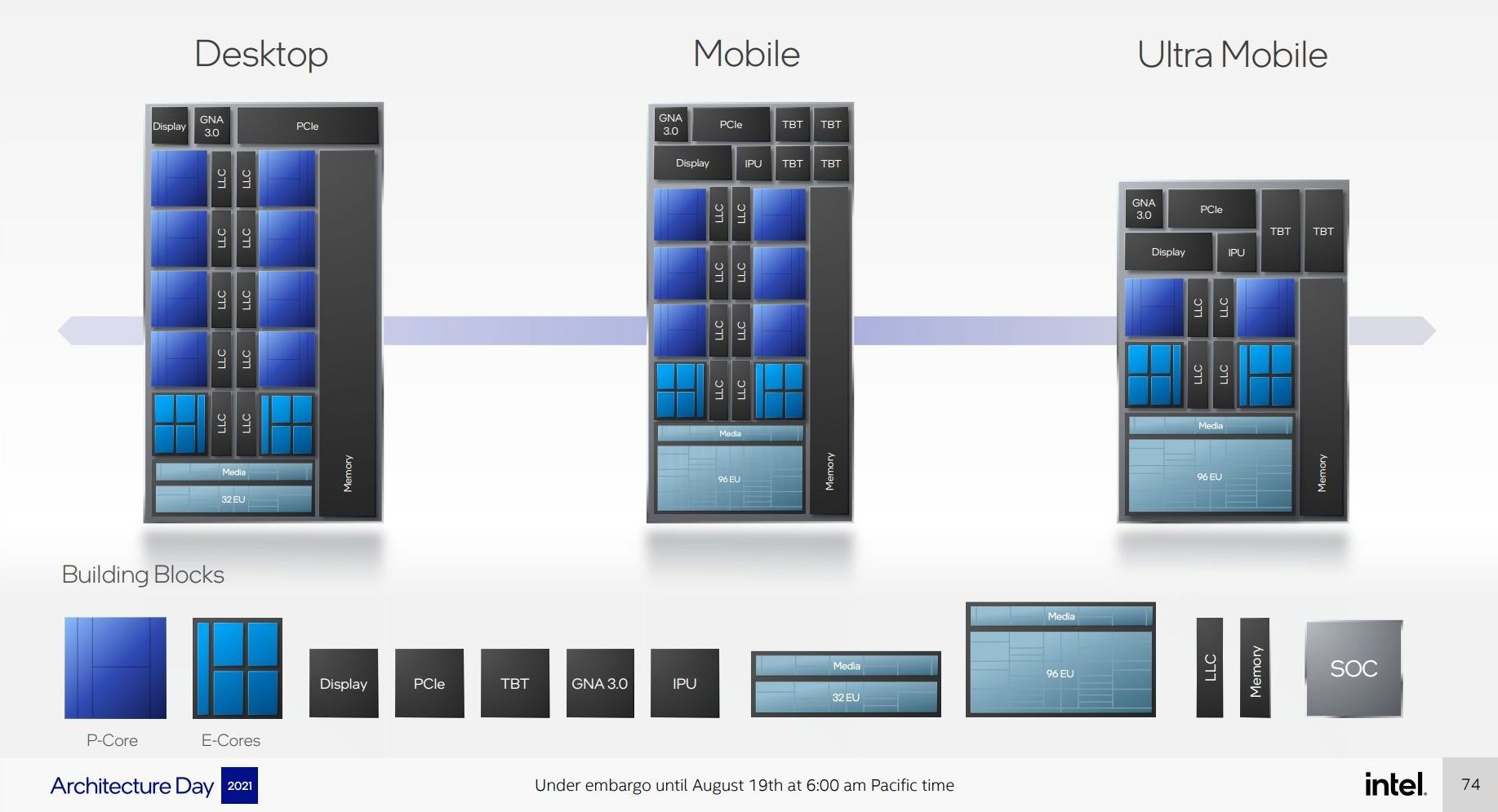
Here it shows that four E-cores takes up the same physical space as one P-core, but also that the desktop hardware will at most have 32 EUs (Execution Units) for Xe-LP graphics (same as the previous generation), while both of the mobile processors will offer 96 physical EUs that may be disabled down based on the specific line item in the product stack.
All three processors will feature Intel’s next generation Gaussian Neural Accelerator (GNA 3.0) for minor low power AI tasks, a display engine, and some level of PCIe, however the desktop processor will have more. Only the mobile processors will get an Image Processing Unit (IPU), and Thunderbolt 4 (TBT), and here the big UP3 mobile processor gets four ports of Thunderbolt whereas the smaller UP4 will only get two. The desktop processor will not have any native Thunderbolt connectivity.
A bit more info on the Desktop Processor IO and Interconnect
We’ll cover a bit more detail about the core designs later in this article, but Intel did showcase some of the information on the desktop processor. It confirmed explicitly that there would be 16 total cores and 24 threads, with up to 30 MB of non-inclusive last level/L3 cache.

In contrast to previous iterations of Intel’s processors, the desktop processor will support all modern standards: DDR5 at 4800 MT/s, DDR4-3200, LPDDR5-5200, and LPDDR4X-4266. Alongside this the processor will enable dynamic voltage-frequency scaling (aka turbo) and offer enhanced overclocking support. What exactly that last element means we’re unclear of at this point.
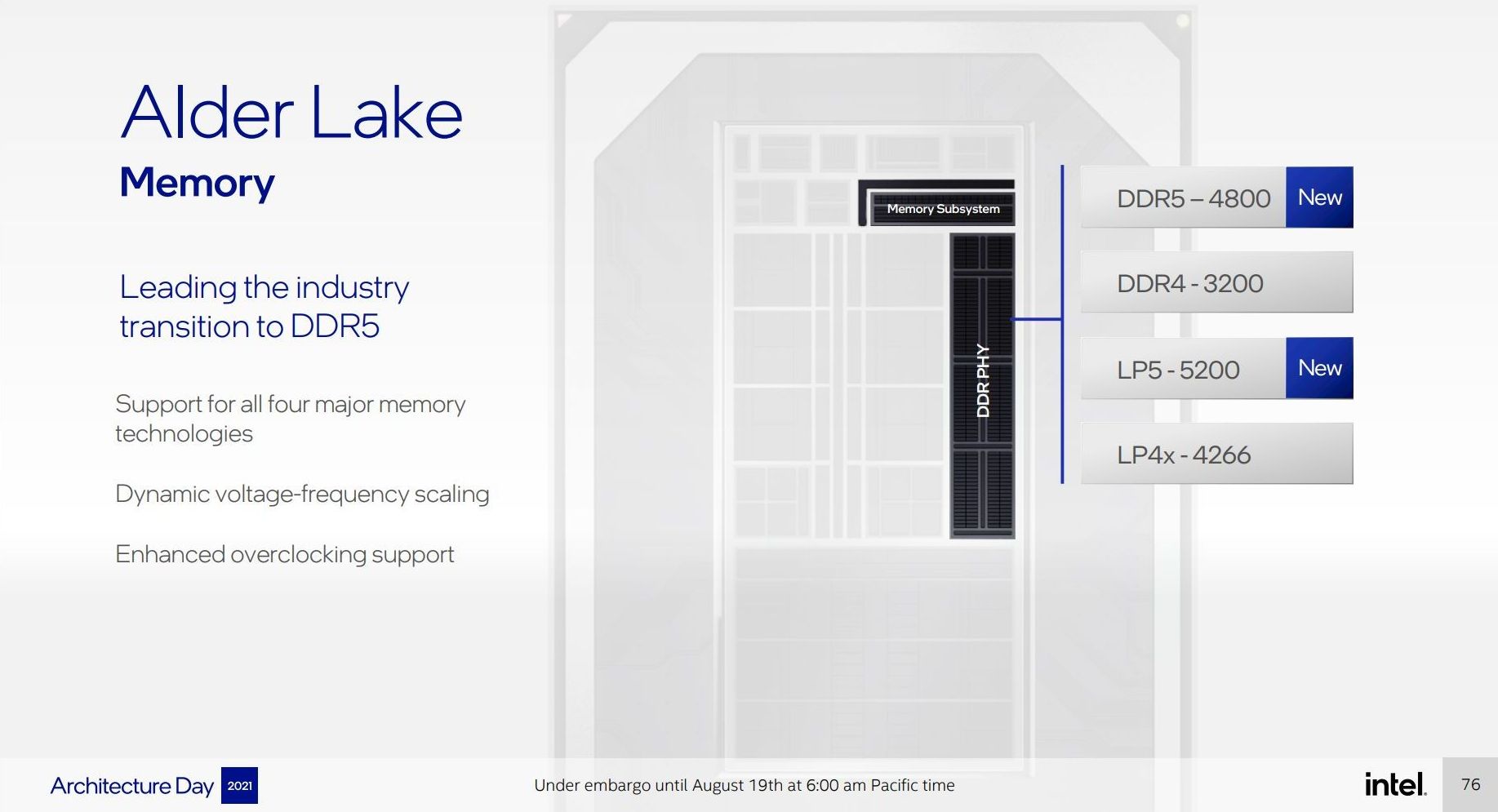
Intel confirmed that there will not be separate core designs with different memory support – all desktop processors will have a memory controller that can do all four standards. What this means is that we may see motherboards with built-in LPDDR5 or LPDDR4X rather than memory slots if a vendor wants to use LP memory, mostly likely in integrated small form factor designs but I wouldn’t put it past someone like ASRock to offer a mini-ITX board with built in LPDDR5. It was not disclosed what memory architectures the mobile processors will support, although we do expect almost identical support.
On the PCIe side of things, Alder Lake’s desktop processor will be supporting 20 lanes of PCIe, and this is split between PCIe 4.0 and PCIe 5.0.
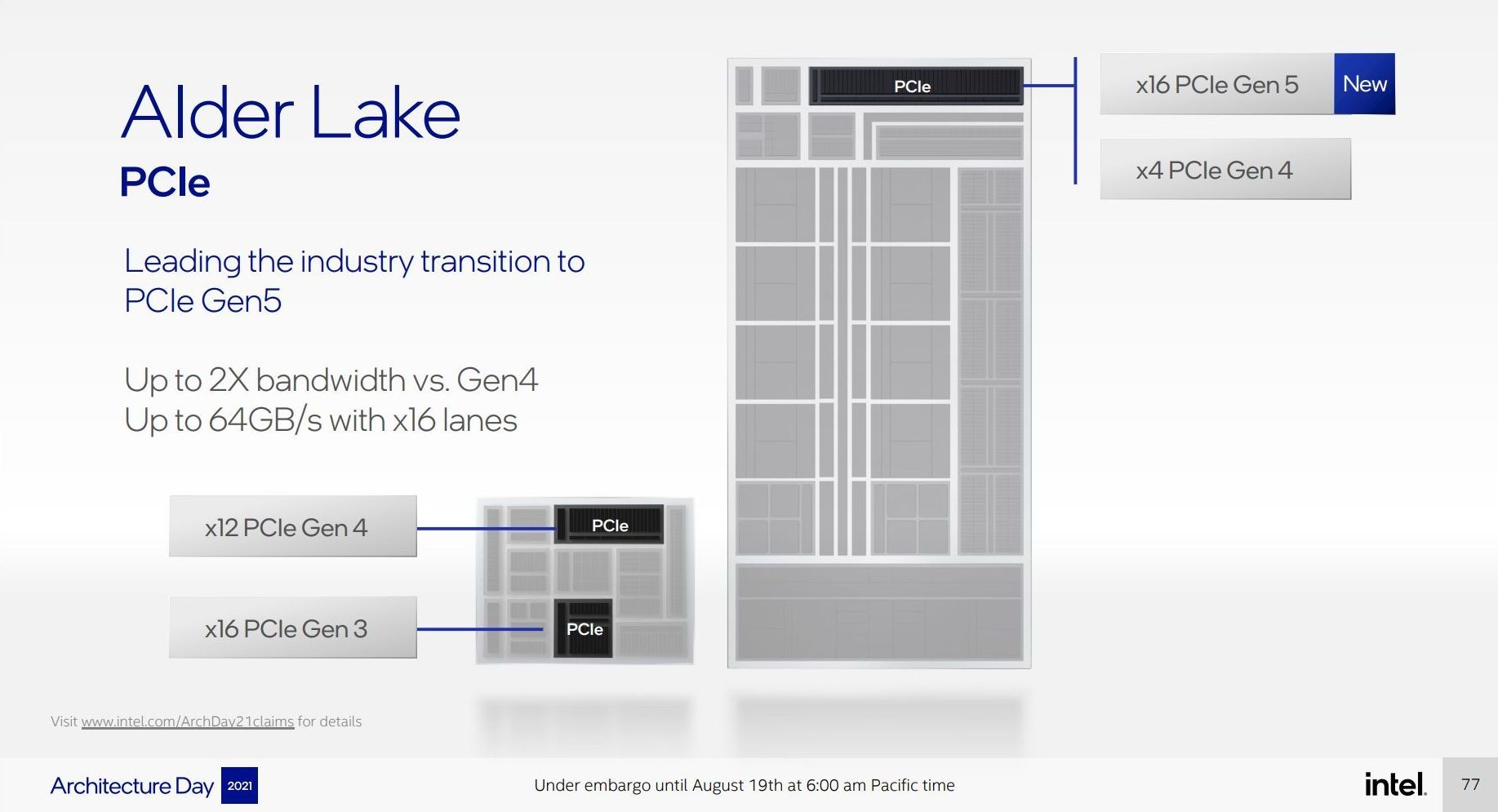
The desktop processor will have sixteen lanes of PCIe 5.0, which we expect to be split as x16 for graphics or as x8 for graphics and x4/x4 for storage. This will enable a full 64 GB/s bandwidth. Above and beyond this are another four PCIe 4.0 lanes for more storage. As PCIe 5.0 NVMe drives come to market, users may have to decide if they want the full PCIe 5.0 to the discrete graphics card or not
Intel also let it be known that the top chipset for Alder Lake on desktop now supports 12 lanes of PCIe 4.0 and 16 lanes of PCIe 3.0. This will allow for additional PCIe 4.0 devices to use the chipset, reducing the number of lanes needed for items like 10 gigabit Ethernet controllers or anything a bit spicier. If you ever thought your RGB controller could use more bandwidth, Intel is only happy to provide.
Intel did not disclose the bandwidth connectivity between the CPU and the chipset, though we believe this to be at least PCIe 4.0 x4 equivalent, if not higher.
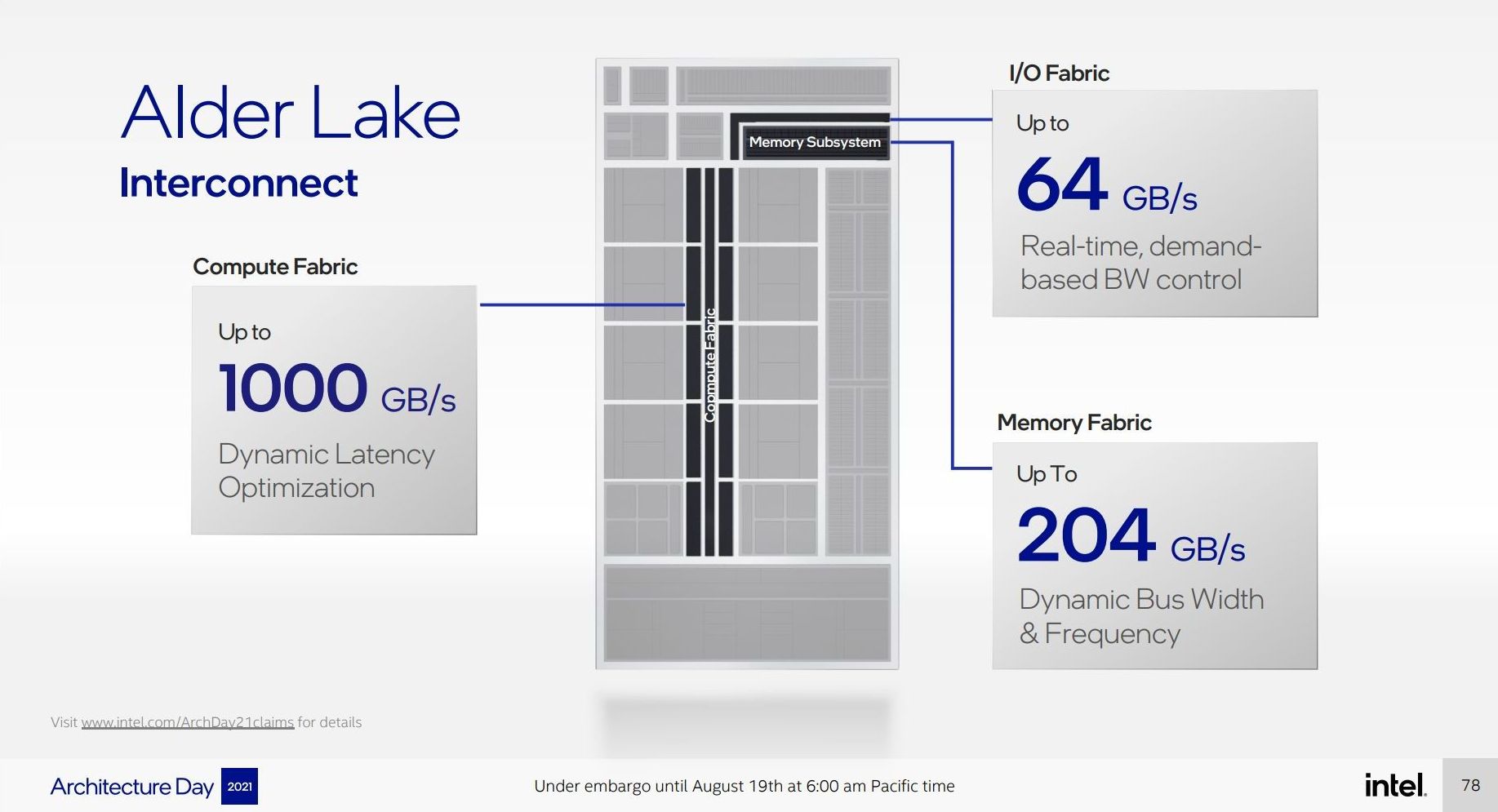
The Alder Lake processor retains the dual-bandwidth ring we saw implemented in Tiger Lake, enabling 1000 GB/s of bandwidth. We learned from asking Intel in our Q&A that this ring is fully enabled regardless of whether the P-cores or E-cores are being used – Intel can disable one of the two rings when less bandwidth is needed, which would save power, however based on previous testing this single ring could end up drawing substantial power compared to the E-cores in low power operation. (This may be true in the mobile processors as well, which would have knock on effects for mobile battery life.)
The 64 GB/s of IO fabric is in line with the PCIe 5.0 x16 numbers we saw above, however the 204 GB/s of memory fabric bandwidth is a confusing number. Alder Lake features a 128-bit memory bus, which allows for 4x 32-bit DDR5 channels (DDR5 has two 32-bit channels per module, so 2 modules still), however in order to reach 204 GB/s in that configuration requires DDR5-12750; Intel has rated the processor only at DDR5-4800, less than half that, so it is unclear where this 204 GB/s number comes from. For perspective, Intel’s Ice Lake does 204.8 GB/s, and that’s a high-power server platform with 8 channels of DDR4-3200.

This final slide mentions TB4 and Wi-Fi 6E, however as with previous desktop processors, these are derived from controllers attached to the chipset, and not in the silicon itself. The mobile processors will have TBT integrated, but the desktop processor does not.
This slide also mentions Intel Thread Director, which we want to address on the next page before we get to the microarchitecture analysis.








223 Comments
View All Comments
GreenReaper - Friday, August 20, 2021 - link
Intel Threat Detected!ifThenError - Friday, August 20, 2021 - link
LOL!Underrated comment
mode_13h - Saturday, August 21, 2021 - link
:Ddiediealldie - Thursday, August 19, 2021 - link
I'm quite curious how their E-cores are designed. They somehow use 6-way decoder which is same width compared to P-cores. And use twice bigger I-cache, yet using 1/4 of area.Maybe it's related to design philosophy? or Atom team's a true trump card of the Intel design team?
name99 - Thursday, August 19, 2021 - link
That "6-way decoder" is typical Intel double-talk. What is done is that you have two decoders that can each decode three instructions. This works IF there is a branch between the two sets of instructions, because the branch landing point provides a resync point for the second decoder, so the two can run in parallel.You could obviously extend this, in a decent Next Fetch Predictor system, to have the NFP store the lengths of each instruction in the run of instructions to be decoded, and get trivial parallel decode. And Andy Glew (I think it was him, either him or Jim K) submitted a patent for this around 2000. But in true Intel fashion, nothing seems to have been done with the idea...
GeoffreyA - Saturday, August 21, 2021 - link
If I'm not mistaken, Tremont or Goldmont, can't remember which, began marking the instruction boundaries in cache.name99 - Saturday, August 21, 2021 - link
Doing it in the cache is more difficult. Of course it makes the most sense! But it hits the problem that, *in theory*, you can have stupid code that jumps into the middle of an instruction and starts decoding the alternative version of the byte stream that results.This is, of course, absolutely insane, but it's part of the joy that is supporting x86.
Now one way to handle this is to tag the boundaries not in the I-cache (where you can jump to any byte) but in structures that are already set up to deal with instruction streams (as opposed to byte streams). Hence the Next Fetch Predictor, as I described, or in a trace cache if you are using that.
Another solution would be yet another predictor! Assume most code will be sane, but have a separate pool of decoders that are validating the byte stream as opposed to the high-speed instruction stream going through main path of the CPU. In the event of a mismatch
- treat it like a branch misprediction, flush and restart AND
- train the predictor that for this particular cache line, we have to decode slowly and surely
Now why doesn't Intel do any of these things? You and I can think of them, just as people like Andy Glew were thinking of variants of them 20 years ago.
My primary hypothesis is that Intel has become locked into the idea that GHz is everything. Sure they occasionally say they don't believe this, or even claim to have reformed after a disaster (*cough* Pentium4 *cough*) but then they head right back to the crack house.
I suspect it's something like the same mentality as the US Air Force -- when pilots form the highest levels of command, they see pilots as the essence of what the Air Force IS; drones and UAV's are a cute distraction but will never be the real thing.
Similarly, if you see GHz as the essence of what Intel is, that smarts are cute but real men work on GHz, then you will always be sacrificing smarts if they might cut into GHz. But GHz costs the problems we see in the big cores: the crazy power draws, and the ridiculously low density...
Well, this is getting into opinion, not technology, so interpret it as you wish!
GeoffreyA - Sunday, August 22, 2021 - link
Looking at the article again, I see their on-demand instruction length decoder is where this is happening. Seems to be caching lengths after they're worked out. I also wonder if this is why Atom hasn't had a uop cache as yet. It's either that or the length caching, because the uop cache will indirectly serve that purpose as well (decoded instructions don't need their lengths worked out). So it's perhaps a matter of die area here that Intel chose that instead of a uop cache.GeoffreyA - Sunday, August 22, 2021 - link
It's been said that K7 to Bulldozer also did a similar thing, marking instruction boundaries in the cache. And the Pentium MMX, but need to double check this one.mode_13h - Sunday, August 22, 2021 - link
> In the event of a mismatch - treat it like a branch misprediction, flush and restartYes, because even assembly language doesn't make it easy to jump into the middle of another instruction. IMO, any code which does that *deserves* to run slowly, so that it will get replaced with newer software that's written in an actual programming language.
> My primary hypothesis is that Intel has become locked into the idea that GHz is everything.
I think they just got lulled into thinking it was enough to deliver modest generational gains. Anything more ambitious probably jeopardized the schedule or risked their profit margins due to the cores getting to big and expensive. And when time comes for more performance, they reach into their old playbook and go with a "sure" win, like wider vectors. I wonder if the example of TSX reveals anything about their execution, on the more innovative stuff. Because that doesn't build a lot of confidence for taking on bold, new ideas.
> when pilots form the highest levels of command,
> they see pilots as the essence of what the Air Force IS
Not just pilots, but specifically fighter pilots. So, they also don't care much about bombers or Space Command (now Space Force). The only way to change that would be to make them care, by making them more accountable for the other programs, until they realize they need them to be run by someone who know about that stuff. Either that or just reorg the whole military. That would probably also help reign in defense spending.