The Snapdragon 8 Gen 1 Performance Preview: Sizing Up Cortex-X2
by Dr. Ian Cutress on December 14, 2021 8:00 AM ESTTesting the Cortex-X2: A New Android Flagship Core
Improving on the Cortex-X1 by switching to the Arm v9 architecture and increasing the core resources, both Arm and Qualcomm are keen to promote that the Cortex-X2 offers better performance and responsiveness than previous CPU cores. The small frequency bump from 2.85 GHz to 3.00 GHz will add some of that performance, however the question is always if the new manufacturing process coupled with the frequency increase allows for better power efficiency when running these workloads. Our standard analysis tool here is SPEC2017.
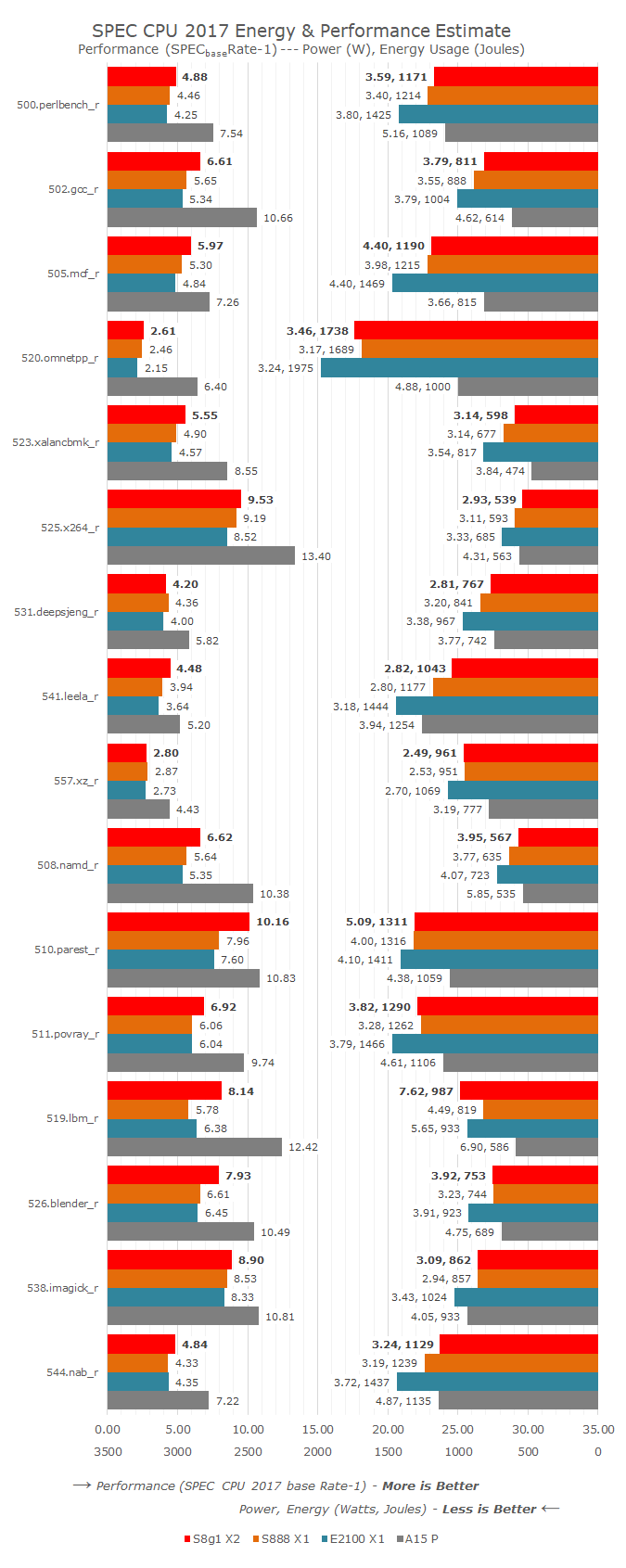
Running through some of these numbers, there are healthy gains to the core, and almost everything has a performance lift.
On the integer side (from 500.perlbench to 557.xr), there are good gains for gcc (+17%), mcf (+13%), xalancbmk (+13%), and leela (+14%), leading to an overall +8% improvement. Most of these integer tests involve cache movement and throughput, and usually gains in sub-tests like gcc can help a wide range of regular user workloads.
Looking at power and energy for the integer benchmarks, we’re seeing the X2 consume more instantaneous power on almost all the tests, but the efficiency is kicking in. That overall 8% performance gain is taking 5% less total energy, but on average requires 2% more peak power.
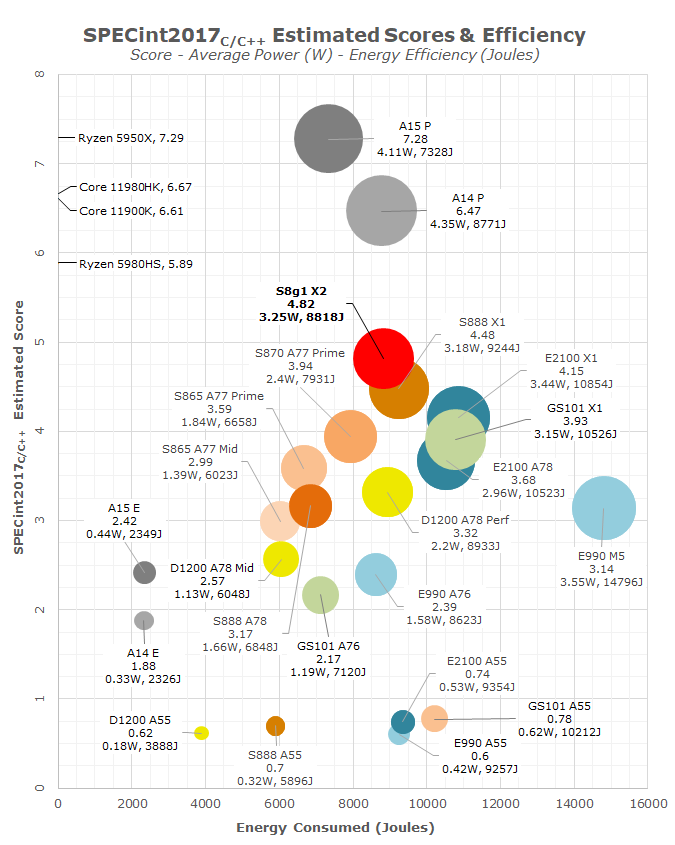
If we put this core up against all the other performance cores we test, we see that 8% jump in performance for 5% less energy used, and the X2 stands well above the X1 cores of the previous generation, especially those in non-Snapdragon processors. There is still a fundamental step needed to reach the Apple cores, even the previous-generation A14 performance core, which scores 34% higher for the same energy consumed (albeit on average another 34% peak power).
Just on these numbers, Qualcomm’s +20% performance or +30% efficiency doesn’t bare fruit, but the floating point numbers are significantly different.
Several benchmarks in 2017fp are substantially higher on the X2 this generation. +17% on namd for example would point to execution performance increases, but +28% in parest, +41% in lbm and +20% in blender showcases a mix of execution performance and memory performance. Overall we’re seeing +19% performance, which is nearer Qualcomm’s 20% mark. Note that this comes with an almost identical amount of energy consumed relative to the X1 core in the S888, with a difference of just 0.2%.
The major difference however is the average power consumed. For example, our biggest single test gain in 519.lbm is +41%, but where the S888 averages 4.49 watts, the new X2 core averages 7.62 watts. That’s a 70% increase in instantaneous power consumer, and realistically no single core in a modern smartphone should draw that much power. The reason why the power goes this high is because lbm leverages the memory subsystem, especially that 6 MiB L3 cache and relies on the 4 MiB system level cache, all of which consumes power. Overall in the lbm test, the +41% performance costs +20% energy, so efficiency is still +16% in this test. Some of the other tests, such as parest and blender, also follow this pattern.

Comparing against the competition, the X2 core does make a better generation jump when it comes to floating point performance. It will be interesting to see how other processors enable the X2 core, especially MTK’s flagship at slightly higher frequency, on TSMC N4, but also if it has access to a full 14 MiB combination of caches as we suspect, that could bring the power draw during single core use a lot higher. It will be difficult to tease out exactly who wins what where based on implementation vs. process node, but it will be a fun comparison to make when we look purely at the X2 vs. X2 cores.
Unfortunately due to how long SPEC takes to run (1h30 on the X2), we were unable to test on the A710/A510. We’ll have to wait to see when we get a retail unit.








169 Comments
View All Comments
eastcoast_pete - Tuesday, December 14, 2021 - link
I guess that's one "impressive" benchmark score, just not the one any user would hope for. Less than 10% complete after half an hour is pretty abysmal. Doesn't bode well for ARM's supposedly much improved LITTLE core designs. Just for comparison, how did the last A55 cores perform in that test?dudedud - Wednesday, December 15, 2021 - link
Andrei said something along the lines of 14hrs for both int and fp SPEC 06.Wilco1 - Thursday, December 16, 2021 - link
Remember the little cores are much slower than the big cores since they have very little cache and run at a low frequency. In SD888 the little cores are 6.4 times slower than the big core. That should be reduced to about 5 times in 8gen1.I think having 4 little cores is too much, they don't contribute to benchmark scores, so you could have just 1 or 2 for background tasks and use the area to quadruple the tiny L2.
iphonebestgamephone - Thursday, December 16, 2021 - link
They do contribute to benchmark scores, 4 of them can be helpful when you need to load up all 4 big cores for the foreground and theres still some background tasks going on.Wilco1 - Saturday, December 18, 2021 - link
That does not make sense. The little cores have almost no L2 cache so will be competing with (and slowing down) the big cores due to the small L3. Having fewer little cores with a much larger L2 means more L3 is available per core, improving performance when all cores are loaded.A little core is most useful for background tasks when the screen is off and mid/big cores are powered down. If you have more background tasks than a single little core could handle, then it's not really "background", and it would be better to run them on a mid core since that will be several times more efficient than 4 little cores (see the efficiency graph, the mid core in eg. SD888 has about the same efficiency as a maxed out little core).
iphonebestgamephone - Sunday, December 19, 2021 - link
When all 3 mid cores and the prime core are fully loaded in apps that use 4 threads, the little cores are doing all the background tasks. How much l3 do background tasks need anyway?syxbit - Tuesday, December 14, 2021 - link
>>There is no AV1 decode engine in this chip, with Qualcomm’s VPs stating that the timing for their IP block did not synchronize with this chip.This is very disappointing. The Radeon 6800, which launched over a year ago has hardware AV1 decode. I imagine the 2021 Exynos and Tensor chips will all do AV1
TheinsanegamerN - Tuesday, December 14, 2021 - link
AV1 wont be necessary for a decade at least. AV1 only hit stable 1.0 spec in 2019, this chip was likely already in the design phase beforehand.movax2 - Wednesday, December 15, 2021 - link
YouTube and Netflix already uses AV1 for a good portion of their videos. Your statement is wrong.GC2:CS - Tuesday, December 14, 2021 - link
The GPU upgrade seems absolutelly massive.I have not seen 50% gain in years if i remember corectly.