Intel Unveils Rialto Bridge: Second-Gen Xe-HPC Accelerator to Succeed Ponte Vecchio
by Ryan Smith on May 31, 2022 12:30 PM EST
With ISC High Performance 2022 taking place this week in Hamburg, Germany, Intel is using the first in-person version of the event in 3 years to offer an update to the state of their high performance/supercomputer silicon plans. The big news out of the show this year is that Intel is naming the successor to the Ponte Vecchio accelerator, which the company is now disclosing as Rialto Bridge.
Previously appearing on Intel’s roadmaps as “Ponte Vecchio Next”, Intel’s GPU teams have been pipelining the development of Ponte’s successor even as the first large installation of Ponte itself (the Aurora Supercomputer) is still being stood up. As part of the company’s 3 year (ish) roadmap that leads to CPUs and accelerators converging with the Falcon Shores XPU, Rialto Bridge is the part that will, if you’ll pardon the pun, bridge the gap between Ponte and Falcon, offering an evolution of Ponte’s design that’s making use of newer technologies and manufacturing processes.

While Intel isn’t offering a fully detailed technical breakdown this early in the process, at a high level the company is talking a bit about specifications, as well as providing a render of the future chip that removes all doubt that it’s a Ponte successor, showcasing that it’s comprised of dozens of tiles/chiplets in the same layout as Ponte. The biggest change that Intel is talking about today is that they’ll be expanding the total number of Xe compute cores from 128 on Ponte to a maximum of 160 on Rialto Bridge – presumably by increasing the number of Xe cores in each compute tile.

Absent any concrete details on the manufacturing side of matters, Intel is at least confirming that Rialto will use newer manufacturing nodes for its construction, replacing its current mix of TSMC N7 (Link Tile), TSMC N5 (Compute), and Intel 7 (Cache & Base) parts. The Intel 4 process is expected to come online this year, so using that to upgrade the Base and Cache would make sense. Ideally, Intel would also like to jump forward on process nodes for the compute tiles as well, possibly by using this opportunity to move production of those tiles to Intel 4 – though we wouldn’t count out TSMC N4, either.
With that said, at the risk of reading too much into a single renderer, Rialto has one noticeable difference from Ponte when it comes to the compute cores: whereas Ponte used pairs of compute cores with a cache tile in between, Rialto at first glance would seem to be using monolithic slabs. This implies that Intel has opted to integrate the Rambo cache on-die with the compute tiles, and that they’re willing to fab fewer, larger compute tiles. This does lend some credence to the idea that Intel is taking over compute tile manufacturing (since they already make the cache tiles), but we’ll have to see just what Intel announces later on.
Interestingly, Intel is also promising more I/O bandwidth for Rialto – though again, this is a very high-level (and unspecific) detail. Ponte is already one of the first products shipping with PCIe 5.0 connectivity, and with PCIe 6.0 hardware still a bit off, this may be more about on-chip bandwidth than off-chip bandwidth, or about the amount of bandwidth available between accelerators using Intel’s Xe Link interconnect.
HBM3 is also a shoe-in for Intel’s next-generation accelerator, given that it’s already going into accelerators shipping this year. HPC accelerators just about live and die based on memory bandwidth, so we expect that it would be the first thing Intel looked at for Rialto. And it would be consistent with Intel’s awkwardly phrased “More GT/s” since memory bandwidth is often measured in gigatransfers.
Finally, Intel is stating that Rialto will be based around a newer version of the Open Accelerator Module (OAM) socket specification, which is particularly notable since the next version of OAM has yet to be announced. Absent more details, the biggest differentiating factor seems to be supported power – whereas OAM 1.x allows for modules to draw up to 700 Watts, Intel is talking about doing up to 800 Watts on a Rialto module. Which, for better or worse, is consistent with the increase in power consumption for the highest performing versions of the next generation of HPC accelerators, and is a big factor in the shift to liquid and immersion cooling for high-end hardware.
| Compute GPU Accelerator Comparison | |||
| AnandTech | Intel | Intel | NVIDIA |
| Product | Rialto Bridge | Ponte Vecchio | H100 80GB |
| Architecture | Xe-HPC | Xe-HPC | Ampere |
| Transistors | ? | 100 B | 80 B |
| Tiles (inc HBM) | 31? | 47 | 6 + 1 spare |
| Compute Units | 160 | 128 | 132 |
| Matrix Cores | 1280? | 1024 | 528 |
| L2 / L3 | ? | 2 x 204MB | 50MB |
| VRAM Capacity | ? | 128 GB | 80 GB |
| VRAM Type | HBM3? | 8 x HBM2e | 5 x HBM3 |
| VRAM Width | ? | 8192-bit | 5120-bit |
| VRAM Bandwidth | ? | ? | 3.0 TB/s |
| Chip-to-Chip Total BW | ? | 64 x 11.25 GB/s (4x16 90G SERDES) |
18 x 50 GB/s |
| CPU Coherency | Yes | Yes | With NVLink 4 |
| Manufacturing | ? | Intel 7 TSMC N7 TSMC N5 |
TSMC N4 |
| Form Factors | OAM 2.0 (800W) | OAM (600W) | SXM4 (400W*) |
| Release Date | Mid-2023 (Sampling) | 2022 | 2022 |
| *Some Custom deployments go up to 600W | |||
Overall, Intel is targeting a 30% increase in “application level” performance with Rialto bridge. Which at first blush is not a massive gain, but it’s also for a part that’s coming out around a year after the original Ponte Vecchio. The 25% increase in the number of Xe cores means that most of this performance uplift should be delivered by the additional hardware as opposed to clockspeed changes, but since Intel is quoting real-world performance expectations as opposed to just theoretical throughput, we wouldn’t be too surprised if Rialto’s on-paper specs were a bit richer still. Intel is also promising that Rialto should be more efficient than Ponte, which at face value is a reasonable claim since performance should be going up faster than power consumption.
Per Intel’s roadmap, the plan is to have Rialto Bridge start sampling in mid-2023. Given Intel’s troubles getting Ponte Vecchio out on time – you still can’t get it unless you’re Aurora – this would be a surprisingly quick turnaround time for Intel. But at the same time, since these are pipelined designs with a very strong architectural similarity, ideally Intel will not experience nearly as many teething problems with Rialto as they have Ponte. But as always, we’ll see what actually happens next year when Intel is closer to delivering their next accelerator.
All Roads Lead to Falcon Shores
With the addition of Rialto Bridge to Intel’s HPC plans, the company’s current silicon roadmap looks like the following:
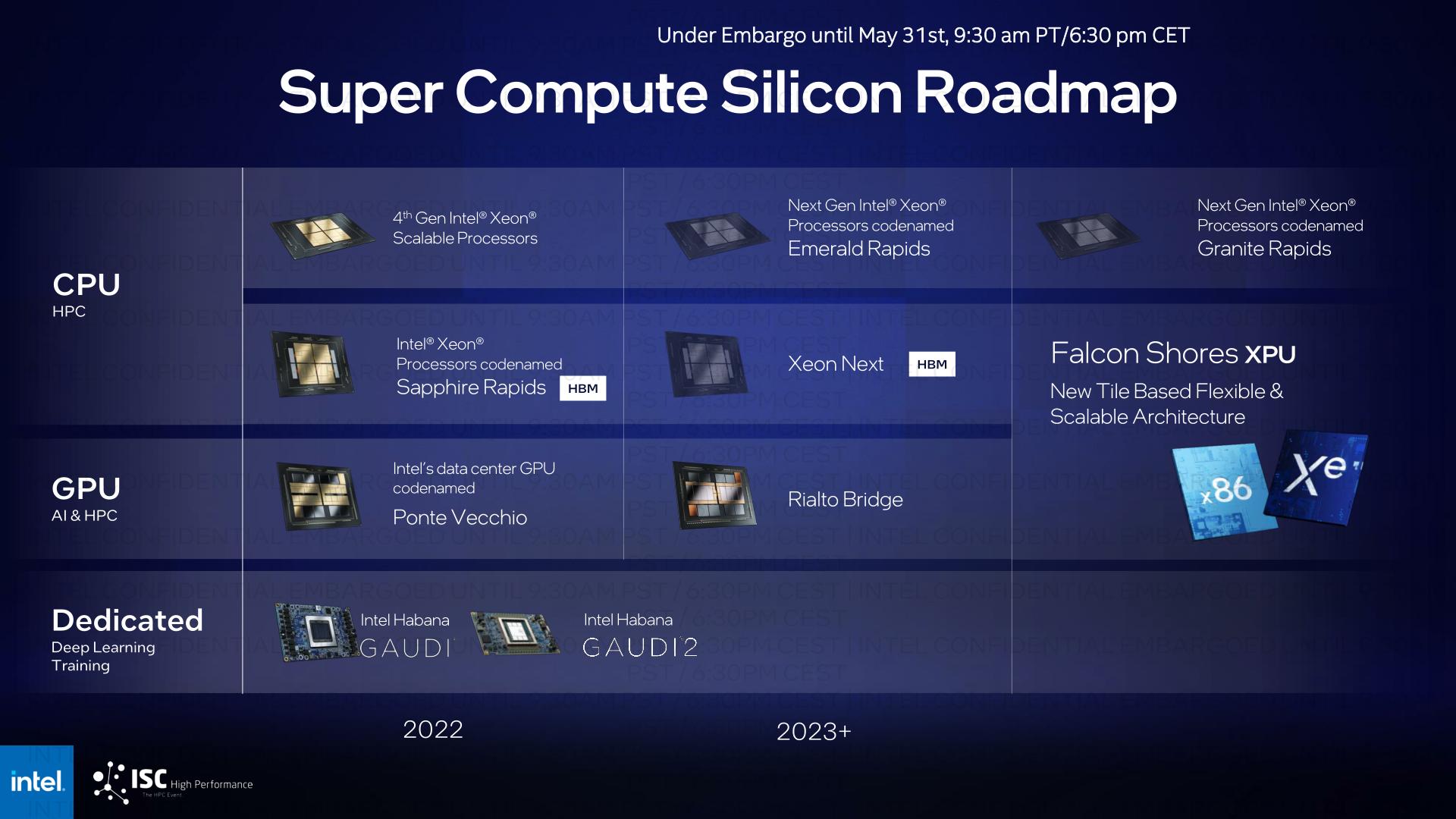
Both the HBM-equipped Xeon and HPC accelerator lines are set to merge in 2024 with Intel’s first flexible XPU, Falcon Shores. Falcon Shores was first announced at Intel’s winter investor meeting earlier this year, and will be Intel’s first product that takes high-performance CPU and GPU tiles to their logical conclusion by allowing for a configurable number of each tile type. As a result, Falcon Shores encompasses not only mixed CPU/GPU designs, but also (relatively) pure CPU and GPU designs, which is why it’s the successor to both Intel’s HPC CPUs and HPC GPUs.

For today’s event, Intel isn’t offering any further details on Falcon Shores – so the company is still talking about targeting 5x increases in everything from energy efficiency to compute density and memory bandwidth. How they intend to accomplish that, besides relying on their planned packaging and shared memory technologies, remains to be seen. But this update does offer a better picture of where Falcon Shores will fit into Intel’s product roadmaps, by providing a look at how the current HBM-Xeon and Xe-HPC products will merge into it.
Ultimately, Falcon Shores remains as Intel’s power play for the HPC industry. The company is betting that being able to deliver a tightly integrated (but still tiled and flexible) experience with a singular API for all will be what gives them an edge in the HPC market, putting them ahead of traditional GPU-based accelerators. And, if they can deliver on those plans, then 2024 is shaping up to be a very interesting year in the high-performance computing industry.














37 Comments
View All Comments
monkeboi - Wednesday, June 1, 2022 - link
Wrong, Intel won the main contract on 3nm at TSMC, do they'll be first out.lemurbutton - Wednesday, June 1, 2022 - link
Wrong again. Apple always eats first.jospoortvliet - Thursday, June 9, 2022 - link
Yet the M2 is (sadly) on N5.Khanan - Tuesday, May 31, 2022 - link
What a ridiculous product, the manufacturing cost will be gigantic and not worth the price.lemurbutton - Wednesday, June 1, 2022 - link
It's not used to run your puny games. It's used exclusively in the enterprise or government contracts.Khanan - Wednesday, June 1, 2022 - link
Maybe your puny brain didn’t comprehend it, so I’m spelling it out for you: I’m not talking about my PC, I’m talking about server usage.lemurbutton - Wednesday, June 1, 2022 - link
Ok then what’s your source? Tell us more. Show us your math and benchmarks that led to your conclusion.Khanan - Thursday, June 2, 2022 - link
I don’t have to tell a toxic troll anything, stay dumb.Qasar - Thursday, June 2, 2022 - link
lemurbutton, the same can be said to you. post your sources, show us your math. show us that your high praise of apple is justified and mot just blind fanboy posts.zepi - Wednesday, June 1, 2022 - link
800W per socket - either you need a category 5 strength hurricane blowing through your cooler or you watercool this baby.We just saved 60W / server by adjusting fans from "full" to "optimized" setting. I don't want to think how much power you need to feed into the fans on a 1U or 2U box that runs couple of these things...