Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
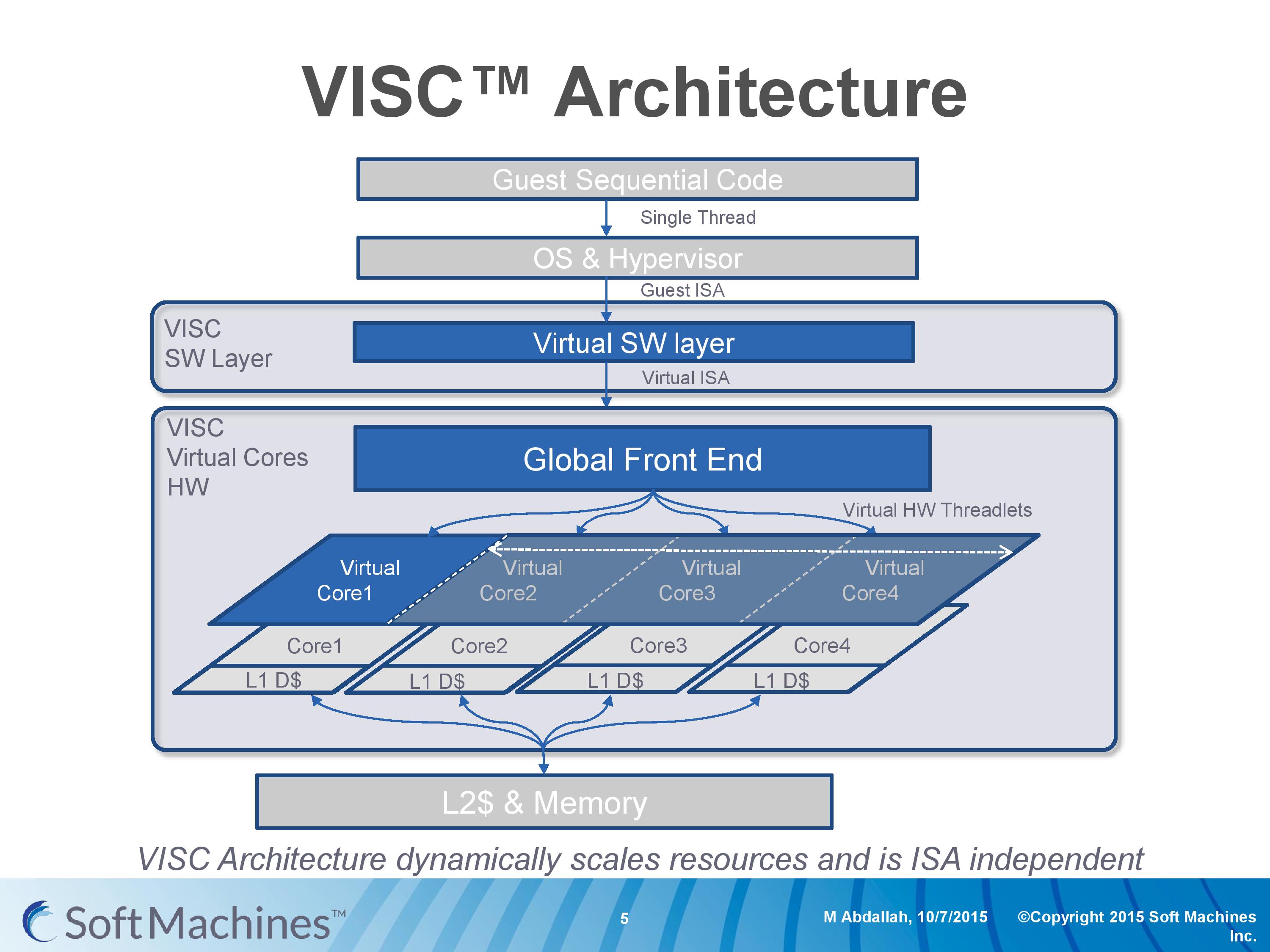
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
tipoo - Friday, February 12, 2016 - link
Pretty interesting stuff. As they open up a bit more and provide more data, I'm cautiously letting myself believe there's a possibility of this taking off, but I'm not budging my optimism meter past 1 until this ships and is positively reviewed.I wonder if it's more likely they'll be bought out first. If Intel sees a credible competitor, that's certainly possible.
willis936 - Friday, February 12, 2016 - link
The prospect of actual single threaded performance increases is exactly what the future of computing needs. I'm not as concerned with the existence of the technology as I am the adoption. Competing with intel is more than just making a good processor. This company will have to convince other companies to integrate a Lot of the controllers and interfaces that intel does for them.easp - Friday, February 12, 2016 - link
If they can actually deliver real single-threaded performance increases, the world will beat a path to their door. On-chip peripherals and off-chip interfaces are cookie-cutter in comparison.Xenonite - Wednesday, February 17, 2016 - link
"If they can actually deliver real single-threaded performance increases, the world will beat a path to their door."Sadly, this is not how the semiconductor industry works. AMD could, for instance, DOUBLE their single threaded integer performance by simply tweaking their ZEN design to utilize 4x~5x the current planned TDP of 95W, using a larger die to spread the increased current load over multiple transistors, double their L1 and L2 cache sizes and to add a low-latency Last Level Cache.
If done before tape-out, AMD can work with the foundry to optimize the transistors' characteristics and operating points, which would easily allow for a doubling in single-threaded throughput.
Even if the raw clock-rate couldn't simply be doubled, they could use the additional power budget to run MUCH more aggressive speculative execution, and to widen their superscalar pipeline to be at least as wide the average instruction pipeline length is long.
Since IPC does not need to be tied to instruction latency, each core could easily complete around 5~6 instructions per clock by having, say, 10~12 fully functional superscalar pipelines (each pipeline can complete any instruction indapendently, without having to rely on shared logic blocks) .
Xenonite - Wednesday, February 17, 2016 - link
Sorry, I submitted the post before I was finished. Basically, it boils down to the fact that no one (other than myself XD) would be willing to pay for such a processor. Even if AMD managed to totally thrash Intel in absolute performance, no one will care. And with no mass consumer support, their shareholders would never approve such a project in the first place.The main reason why VISC is doomed to fail, is quite similar: you simply can not attract investors with raw performance in 2016.
Even if they actually had a ~5x single-threaded performance lead over Intel's fastest consumer desktop chips, they STILL wouldn't get the billions of dollars that they need to do a mass market rollout of their arch.
The whole situation is making me really morbid and depressed; what I wouldn't give to go back to the Pentium 3 days.
Demiurge - Friday, February 12, 2016 - link
16-wide ILP isn't going to be a mass-market solution... most designs are barely using 1.5 instructions per cycle, let alone 4. Given the stellar shift to CPU and then GPU based vector processing... I might be missing something here, but I would say that there are already 16-wide ILP on certain specialized operation that actually benefit, such as video processing for example.Incidentally, does anyone remember Transmeta Code-Morphing Software? If not, look it up...
sonicmerlin - Saturday, February 13, 2016 - link
You didn't even read the fracking article.name99 - Saturday, February 13, 2016 - link
What he's saying (perfectly legitimately) is that- there is a LONG history of companies praising to the skies superficially good ideas which actually turned out not to matter much
- VISC's unwillingness to provide SPECInt numbers, even after being so strongly excoriated about this by the entire tech press and academic world, STRONGLY suggests that what they're peddling does not work the way they claim. It likely provides a great speedup for much FP code (speedup which you can also get by using a GPU, the preferred path of traditional companies), and very little speedup for standard integer code.
The speed at which they claim they can execute also makes one wonder. Even Apple (likely right now the best funded CPU design-house out there, with the simplest target in their sights, working on more or less traditional designs) aims for a major core every two years, with a minor upgrade in between. These guys, with vastly fewer engineers and money, and trying to do something more innovative, believe they can spin a major upgrade every year...
That seems extremely unlikely, so the only real question is: they bullsh*tting only the press/their investors, or are they also bullsh&tting themselves?
Samus - Monday, February 15, 2016 - link
The parallels with Transmetta ring a bell with me, too, and yes, I did read the article. I'm inclined to have a immature capitalist response to things like this, specifically: if a company as big as Intel, with some of the best engineers in the world who are often open to radical ideas, haven't bothered trying an instruction decoder, it is likely because the pros did not outweigh the cons. After all, Jackson technology (hyper threading) is some form of what's going on here, just not targeting specific requests.Azethoth - Wednesday, February 17, 2016 - link
Agreed, and reading the list of unanswered questions it sounds a lot like they are trying to look good in very specific circumstances, rather than being naturally best in class. The competition is GPU + CPU cores. Unless you prove superiority despite all the tricks the competition has available you cannot succeed. What they propose sounds like it needs to break down the normal inter core separation that lets them operate independently so that they can realize single threaded speedup. I am not an EE, so I assume it is at least possible. I am not sure it can be done practically though.