What Went Wrong with NV3x: A Moratorium
by Derek Wilson on April 19, 2004 4:12 PM EST- Posted in
- GPUs
Shedding Light On Shader Performance
Explaining where shaders fit in requires a brief explanation of what happens on the whole when rendering 3D graphics on modern hardware. When moving from software to the screen through the graphics pipeline, there are quite a few things that happen, generally moving from the large scale to the small scale. On the top end, objects and geometry are handled. The position and direction of the viewer of the 3D scene, along with 3D positional data are translated, rotated, and otherwise manipulated as necessary very early on. If we were going for a two color wireframe scene, we would be just about finished. As we continue looking down the graphics pipeline, the operations being performed on the scene get more and more finely grained. We start looking not at an entire scene's geometry, but at a surface's normals to help determine how it will be lit. Moving on we texture surfaces, and further still down the line we start looking at the individual pixels being drawn on the screen and what color a particular pixel will be based on all the processing that has happened previously. This is a simplified overview, but generally the further down the pipeline the smaller the scale of the unit being operated on.A side effect of how scenes are processes is that moving down the pipeline, the set of data being worked on grows as the size of the unit being worked on shrinks. For instance, a normal scene will have a bunch of objects in it which are all made up of a bunch of polygons that have 3 or more vertices each. When a scene is finally rendered, we have gone from one scene with some objects to many more polygons, even more vertices, and millions of pixels to worry about. As a side note, all of this means that it is generally more efficient for developers to get as much work done as early in the pipeline as possible.
Shader hardware is a kind of like a fractal of the graphics pipeline as a whole. First, we operate over vertex data, then this data is manipulated and sent down to the pixel pipes where pixel shaders operate per pixel.
Inside the shaders, we are able to perform a vast array of operations on vertices and pixels, and the longer the shader program, the more impact the shader program will have on performance. Another way to look at this is that longer shader programs require more efficient shader hardware to run well.
Just saying "more efficient shaders" doesn't really paint a clear picture of the issue. shader specifications are requiring that parts of the GPU become more and more like a CPU. With this evolution come all the problems and difficulties associated with architecting a powerful CPU. The most interesting aspects of CPU design to look at when trying to understand the reason NV3x fell short of what it could have been: instruction scheduling.
Scheduling is generally viewed as a compiler design issue, but there are plenty of considerations that need to be made from the hardware side. The main issues we will look at that affect scheduling from an NV3x hardware standpoint are: functional unit availability and register pressure.
First, each shader pipeline has a handful of units inside it that can be doing work at any given time. The pixel pipeline of NV3x can handle a texture and a math operation, and in order to keep the pipeline running at full speed, developers need to keep all of these units working at the same time. If instructions in a shader program aren't ordered such that math and texture operations are interleaved, the NVIDIA architecture suffers as half the work that could be getting done won't be getting done. The compiler will do its best to take a program and reorder it so that it interleaves texture and math operations while maintaining the same output in the end. This is a very difficult problem to overcome, but it is also key to NV3x performance. Enabling the compiler back when the 50 series drivers were released was the reason we saw, in some cases, up to a 25% increase in performance essentially "for free".
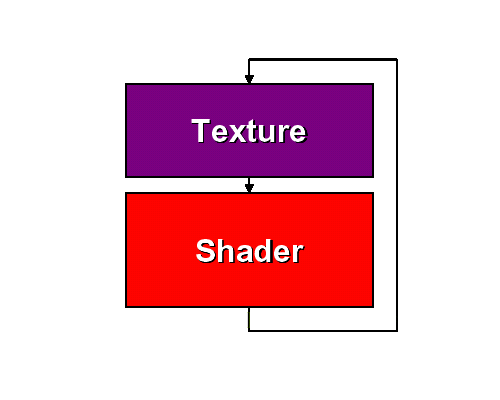
This is the front end of an NV3x pixel shader pipe.
The next scheduling hurdle is register pressure. Not having enough space to store temporary data in local registers forces a lot of time to be wasted on simply juggling data around. The traditional analogy in computer engineering when dealing with managing registers is Tetris. It's not exactly the same, but it can get just as difficult to optimally fill register space as it can be to optimally drop a block in Tetris without knowing what's coming next. It gets even more difficult when there is less space to do everything in (imagine if the Tetris playing field were even less wide than it already is). This is definitely undesirable as we would like to focus on getting some actual work done rather than just playing hot potato with data. The compiler comes in very handy here as well, and takes care of managing register usage in order to optimize program runtime. Unfortunately, if the hardware isn't well suited to the type of programs being run on it, no compiler will be able to solve all the problems.
The way NVIDIA overcame these issues in NV40 was to revamp the internals of their shader pipelines by adding an extra math unit to all the pixel pipes (pixel shaders can now execute two math instructions at the same time, or a math and texture instruction), and expanding the number of registers available for shader programs to use.
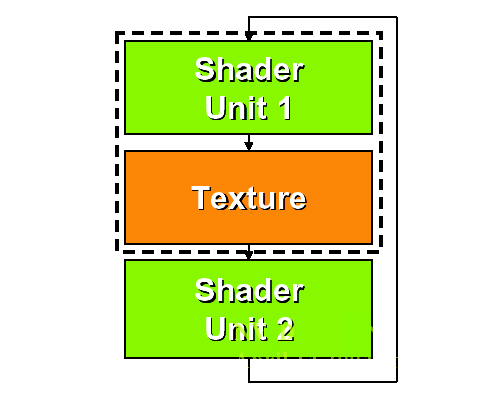
This is the front end of an NV40 pixel shader pipe.
The two math units in the NV40 pixel pipe can be used at the same time when there is no texturing going on, allowing math intensive shader programs to avoid running into scheduling problems, and the registers add more space for easier "bin packing" which alleviates the rest of the large scheduling problems seen in NV3x. In the end, from quadrupling the number of pixel pipes and adding the second math unit, NV40 can push up to 8x the shader performance of NV3x under the right conditions. This very impressive increase in performance was definitely sorely needed as NV3x shader performance was much less than optimal. Vertex shader performance was also essentially doubled in the same manner pixel shader performance was increased up to 8x.
NV40, with its well refined vertex pipes (6) and pixel pipes (16x1) brings a lot of power to the architectural style based in NV3x.








18 Comments
View All Comments
WizzBall - Tuesday, May 4, 2004 - link
Nice article... sooo, when are we going to see the follow-up to this now that ATI came forward with their cards ? May I suggest 'What went wrong with NV4.x' ? :DTrogdorJW - Tuesday, April 27, 2004 - link
Hey... anyone else having password issues, or is that something my company network admins f'ed up? I keep entering my password, but it doesn't get remembered. Ugh....TrogdorJW - Tuesday, April 27, 2004 - link
Personally, I think it's all about the alliteration: "The Pixel Pipe Performance Picture!" :)Anyway, I imagine the moratorium will end once the R420 is released and we can talk about all four chips (R3xx, R4xx, NV3x, and NV4x), right? Yeah, that's it....
On a side note, I wonder how much going from FP24 to FP32 would cost ATI in terms of transistors, not to mention the Shader Model 3.0 stuff. It's not that we really need it, but going from 24-bit to 32-bit color basically makes everthing that operates on the data 25% larger in terms of transistor usage. Add in the other missing SM3.0 features, and I think a 160-180 million transistor R420 would suddenly become a 222 million transistor NV40. Basically, I think performance from the next generation cards will be about the same given the same GPU/VPU and RAM speeds. The only difference will be that NV4x has SM3.0 support, which looks to be a marketing point more than anything.
greendonuts3 - Thursday, April 22, 2004 - link
that's "Post-Mortem", as in "Post-Mortem Analysis" as in "Autopsy," not "Moratorium," as in "banzored."Thank you very much.
And DON'T forget to hyphenate "Post-Mortem."
"Post Mortem" means "dead letter" or some such.
ianmills - Thursday, April 22, 2004 - link
this article is crap. The real reason NV30 sucked is because nvidia slept with 3Dfx and got caught pixel herpes.TauCeti - Wednesday, April 21, 2004 - link
Moratorium:> We have stopped -- we are done with NV3x analysis.
Well, if you have _stopped_ writing NV3X-content, it is _not_ a moratorium.
After a moratorium ends, you are obliged to continue with your _suspended_ activity.
Besides that: good article ;)
DerekWilson - Wednesday, April 21, 2004 - link
#11:We have stopped -- we are done with NV3x analysis. I'll admit that the title could have been phrased a bit better, but we did mean moratorium... Of all the articles I have written I think I've gotten the highest volume of emails on this one -- to tell me that I don't know what moratorium means ;-)
But on topic ... The big problem with an article like this (or any architectural or deeply technical article) is balancing depth, clarity, and length.
If you guys have any suggestions on balancing these aspects in another way, please let us know. We want to write the articles that you want to read!
GomezAddams - Wednesday, April 21, 2004 - link
"Can it not be a moratorium on NV3x articles?"It will be when you stop writing them. ;)
I thought it was a pretty decent article too. I am looking forward to one that compares ATIs next contestant on these issues.
Personally, I can handle a lot more detail but I would prefer not to spend so much time reading articles. :)
Phiro - Wednesday, April 21, 2004 - link
My earlier outburst aside, it's a very good article.DerekWilson - Wednesday, April 21, 2004 - link
Can it not be a moratorium on NV3x articles? I thought it was funny ;-)fp16 vs fp32 and image quality is a very tough nut to crack. there are a lot of things going on on the side of compiler optimizations that we really need to look into in order to understand what's going on.
also, rotated vs. ordered grid has no performance difference. or it shouldn't anyway. we wanted to focus on performance in this article.