6 TB NAS Drives: WD Red, Seagate Enterprise Capacity and HGST Ultrastar He6 Face-Off
by Ganesh T S on July 21, 2014 11:00 AM ESTPerformance - Raw Drives
Prior to evaluating the performance of the drives in a NAS environment, we wanted to check up on the best-case performance of the drives by connecting them directly to a SATA 6 Gbps port. Using HD Tune Pro 5.50, we ran a number of tests on the raw drives. The following screenshots present the results for the various drives in an easy-to-compare manner.
Sequential Reads
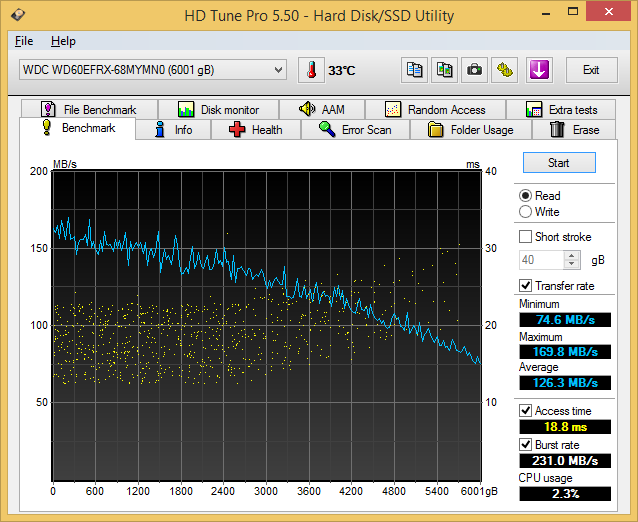
The Seagate Enterprise Capacity drive, as expected, leads the benchmark numbers with an average transfer rate of around 171 MBps. The HGST unit (142 MBps) performs better than the WD Red (126 MBps) in terms of raw data transfer rates, thanks to the higher rotational speed. The burst rate of the Seagate drive is also higher. In effect, the higher amount of cache memory on the Seagate drive helps it to perform well in this test.
Sequential Writes
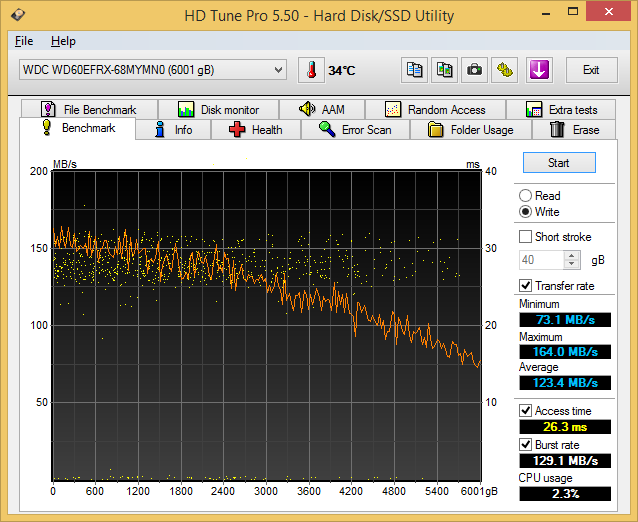
A similar scenario plays out in the sequential write benchmarks. The Seagate drive leads the pack with an average transfer rate of 168 MBps followed by the HGST one at 139 MBps. The WD Red's 123 MBps is the slowest of the lot, but these results are foregone conclusions due to the lower rotational speeds in the Red.
Random Reads
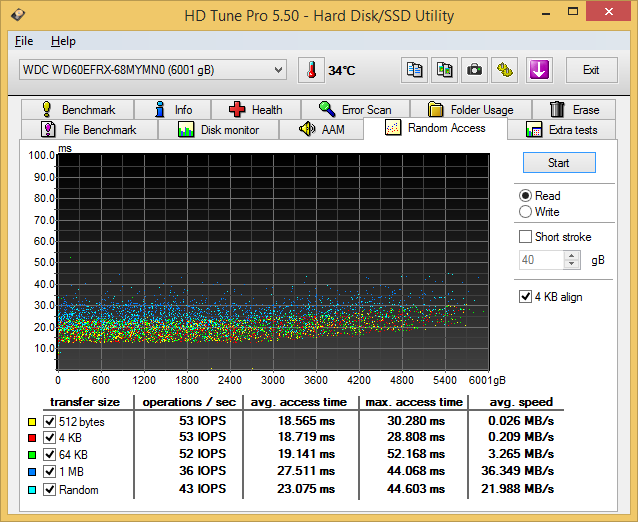
In the random read benchmarks, the HGST and Seagate drives perform fairly similar to each other in terms of IOPS as well as average access time.
Random Writes
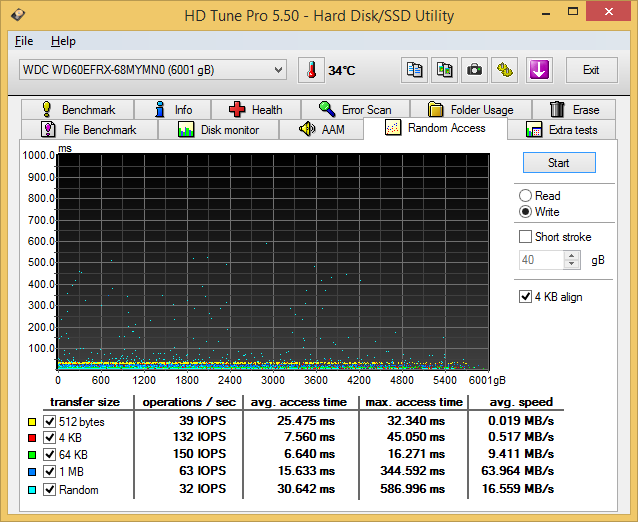
The differences between the enterprise-class drives and the consumer / SOHO NAS drives is even more pronounced in the random write benchmark numbers. However, the most interesting aspect here is that the HGST Ultrastar He6 wins out on the IOPS for 512B transfers due to its sector size. Otherwise, the familiar scenario that we observed in the previous subsections play out here too.
Miscellaneous Reads
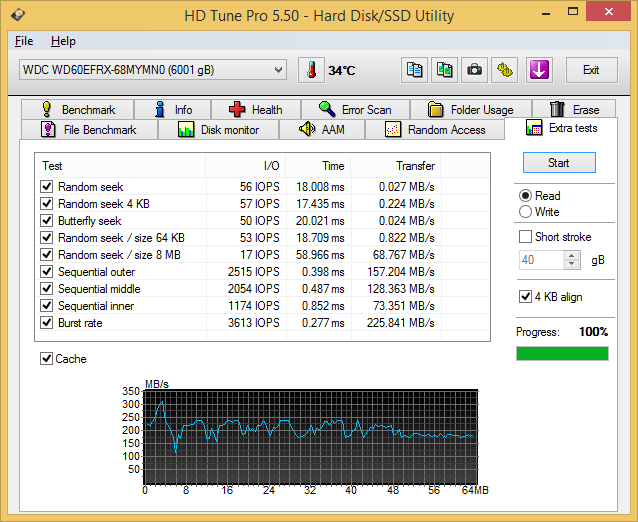
HD Tune Pro also includes a suite of miscellaneous tests such as random seeks and sequential accesses in different segments of the hard disk platters. The numbers above show the HGST and Seagate drives matched much more evenly. The cache effects are also visible in the final graph.
Miscellaneous Writes
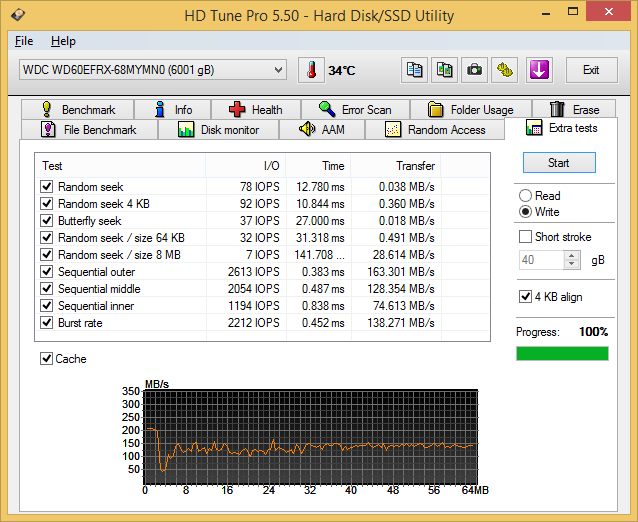
Similar to the previous sub-section, we find that the Seagate and HGST drives quite evenly matched in most of the tests. The HGST drive does exhibit some weird behaviour with the burst rate test and the Seagate one with the 8 MB random seek tests, while the Red is consistent across all of them without being exceptional.
We now have an idea of the standalone performance of the three drives being considered today. In the next section, we will take a look at the performance of these drives when subject to access from a single client - as a DAS as well as a NAS drive.








83 Comments
View All Comments
sleewok - Monday, July 21, 2014 - link
Based on my experience with the WD Red drives I'm not surprised you had one fail that quickly. I have a 5 disk (2TB Red) RAID6 setup with my Synology Diskstation. I had 2 drives fail within a week and another 1 within a month. WD replaced them all under warranty. I had a 4th drive seemingly fail, but seemed to fix itself (I may have run a disk check). I simply can't recommend WD Red if you want a reliable setup.Zan Lynx - Monday, July 21, 2014 - link
If we're sharing anecdotal evidence, I have two 2TB Reds in a small home server and they've been great. I run a full btrfs scrub every week and never find any errors.Child mortality is a common issue with electronics. In the past I had two Seagate 15K SCSI drives that both failed in the first week. Does that mean Seagate sucks?
icrf - Monday, July 21, 2014 - link
I had a lot of trouble with 3 TB Green drives, had 2 or 3 early failures in an array of 5 or 6, and one that didn't fail, but silently corrupted data (ZFS was good for letting me know about that). Once all the failures were replaced under warranty, they all did fine.So I guess test a lot, keep on top of it for the first few months or year, and make use of their pretty painless RMA process. WD isn't flawless, but I'd still use them.
Anonymous Blowhard - Monday, July 21, 2014 - link
>early failure>Green drives
Completely unsurprised here, I've had nothing but bad luck with any of those "intelligent power saving" drives that like to park their heads if you aren't constantly hammering them with I/O.
Big ZFS fan here as well, make sure you're on ECC RAM though as I've seen way too many people without it.
icrf - Monday, July 21, 2014 - link
I'm building a new array and will use Red drives, but I'm thinking of going btrfs instead of zfs. I'll still use ECC RAM. Did on the old file server.spazoid - Monday, July 21, 2014 - link
Please stop this "ZFS needs ECC RAM" nonsense. ZFS does not have any particular need of ECC RAM that every other filer doesn't.Anonymous Blowhard - Monday, July 21, 2014 - link
I have no intention of arguing with yet another person who's totally wrong about this.extide - Monday, July 21, 2014 - link
You both are partially right, but the fact is that non ECC RAM on ANY file server can cause corruption. ZFS does a little bit more "processing" on the data (checksums, optional compression, etc) which MIGHT expose you to more issues due to bit flips in memory, but stiff if you are getting frequent memory errors, you should be replacing the bad stick, good memory does not really have frequent bit errors (unless you live in a nuclear power station or something!)FWIW, I have a ZFS machine with a 7TB array, and run scrubs at least once a month, preferably twice. I have had it up and running in it's current state for over 2 years and have NEVER seen even a SINGLE checksum error according to zpool status. I am NOT using ECC RAM.
In a home environment, I would suggest ECC RAM, but in a lot of cases people are re-using old equipment, and many times it is a desktop class CPU which won't support ECC, which means moving to ECC ram might require replacing a lot of other stuff as well, and thus cost quite a bit of money. Now, if you are buying new stuff, you might as well go with an ECC capable setup as the costs aren't really much more, but that only applies if you are buying all new hardware. Now for a business/enterprise setup yes, I would say you should always run ECC, and not only on your ZFS servers, but all of them. However, most of the people on here are not going to be talking about using ZFS in an enterprise environment, at least the people who aren't using ECC!
tl/dr -- Non ECC is FINE for home use. You should always have a backup anyways, though. ZFS by itself is not a backup, unless you have your data duplicated across two volumes.
alpha754293 - Monday, July 21, 2014 - link
The biggest problem I had with ZFS is its total lack of data recovery tools. If your array bites the dust (two non-rotating drives) on a stripped zpool, you're pretty much hosed. (The array won't start up). So you can't just do a bit read in order to recover/salvage whatever data's still on the magnetic disks/platters of the remaining drives and the're nothing that has told me that you can clone the drive (including its UUID) in its entirety in order to "fool" the system thinking that it's the EXACTLY same drive (when it's actually been replaced) so that you can spin up the array/zpool again in order to begin the data extraction process.For that reason, ZFS was dumped back in favor of NTFS (because if an NTFS array goes down, I can still bit-read the drives, and salvage the data that's left on the platters). And I HAD a Premium Support Subscription from Sun (back when it was still Sun), and even they TOLD me that they don't have ANY data recovery tools like that. And they couldn't tell me the procedure for cloning the dead drives either (including its UUID).
Btrfs was also ruled out for the same technical reasons. (Zero data recovery tools available should things go REALLY farrr south.)
name99 - Tuesday, July 22, 2014 - link
"because if an NTFS array goes down, I can still bit-read the drives, and salvage the data that's left on the platters"Are you serious? Extracting info from a bag of random sectors was a reasonable thing to do from a 1.44MB floppy disk, it is insane to imagine you can do this from 6TB or 18 TB or whatever of data.
That's like me giving you a house full of extremely finely shredded then mixed up paper, and you imaging you can construct a million useful documents from it.