Intel's Hyper-Threading Technology: Free Performance?
by Anand Lal Shimpi on January 14, 2002 2:04 PM EST- Posted in
- CPUs
Face it, we're inefficient
The term efficiency is always thrown around, not only in the corporate environment but also in our daily lives. It's been said that human beings only use a fraction of the power of their brains; it turns out that the same can be said about CPUs.
Take the Pentium 4 for example, the CPU has a total of 7 execution units, two of which can operate on two operations (micro-ops) per clock (these are the double pumped ALUs). And if it were even possible, you wouldn't be able to find software that saturated all of these execution units. The most commonly used desktop software will perform a handful of integer calculations as well as loads and stores but leave the FP units untouched. Whereas a program such as Maya would concentrate almost exclusively on the FP units and leave the ALUs unused. Even applications that primarily use integer operations won't saturate all of the ALUs, especially the "slow" or normal speed integer unit which is primarily used for performing shifts and rotates.
To help better illustrate this let's create a hypothetical CPU with three execution units: an ALU, FPU, and a Load/Store unit for reading from/writing to memory. Let's also assume that our CPU can execute any operation in one clock cycle and it can dispatch operations to all three execution units simultaneously. Now let's feed it a thread that consists of the following instructions:
1+1
10+1
Store Previous Result
The diagram below should help illustrate the saturation level of the execution units (gray denotes an unused execution unit; blue indicates an active execution unit):
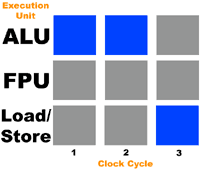
As you can see, during every clock only 33% of the execution units are being used. During this time the FPU goes completely unused. According to Intel, most IA-32 x86 code uses only 35% of the Pentium 4's execution units.
Let's take another thread and send it through our CPU's execution units; this time it will consist of a load, an ADD and a store in that order:
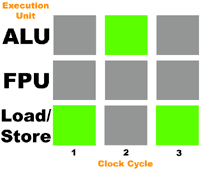
Again we notice the same 33% utilization of execution units.
The type of parallelism we're trying to attain here is known as instruction level parallelism (ILP) where multiple instructions are executed simultaneously because of a CPU's ability to fill their multiple parallel execution units. Unfortunately the reality of most x86 code is that there is not as much ILP as we would like there to be so we must find other ways to improve performance. For example, if we had two of these CPUs in our system then both threads could execute simultaneously. This exploits what is known as thread-level parallelism (TLP) but is also a very costly approach to improving performance.
But what other options are there to make better use of the execution power of today's x86 CPUs?








1 Comments
View All Comments
Anonymous User - Wednesday, September 10, 2003 - link
It's available on desktops now. See:http://configure.us.dell.com/dellstore/config.aspx...