Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
by Andrei Frumusanu on May 27, 2019 12:01 AM ESTThe Cortex-A77 µarch: Going For A 6-Wide* Front-End
The Cortex-A76 represented a clean-sheet design in terms of its microarchitecture, with Arm implementing from scratch the knowledge and lessons of years of CPU design. This allowed the company to design a new core that was forward-thinking in terms of its microarchitecture. The A76 was meant to serve as the baseline for the next two designs from the Austin family, today’s new Cortex-A77 as well next year’s “Hercules” design.

The A77 pushes new features with the primary goals of increasing the IPC of the microarchitecture. Arm’s goals this generation is a continuation of focusing on delivering the best PPA in the industry, meaning the designers were aiming to increase the performance of the core while maintaining the excellent energy efficiency and area size characteristics of the A76 core.
In terms of frequency capability, the new core remains in the same frequency range as the A76, with Arm targeting 3GHz peak frequencies in optimal implementations.

As an overview of the microarchitectural changes, Arm has touched almost every part of the core. Starting from the front-end we’re seeing a higher fetch bandwidth with a doubling of the branch predictor capability, a new macro-OP cache structure acting as an L0 instruction cache, a wider middle core with a 50% increase in decoder width, a new integer ALU pipeline and revamped load/store queues and issue capability.
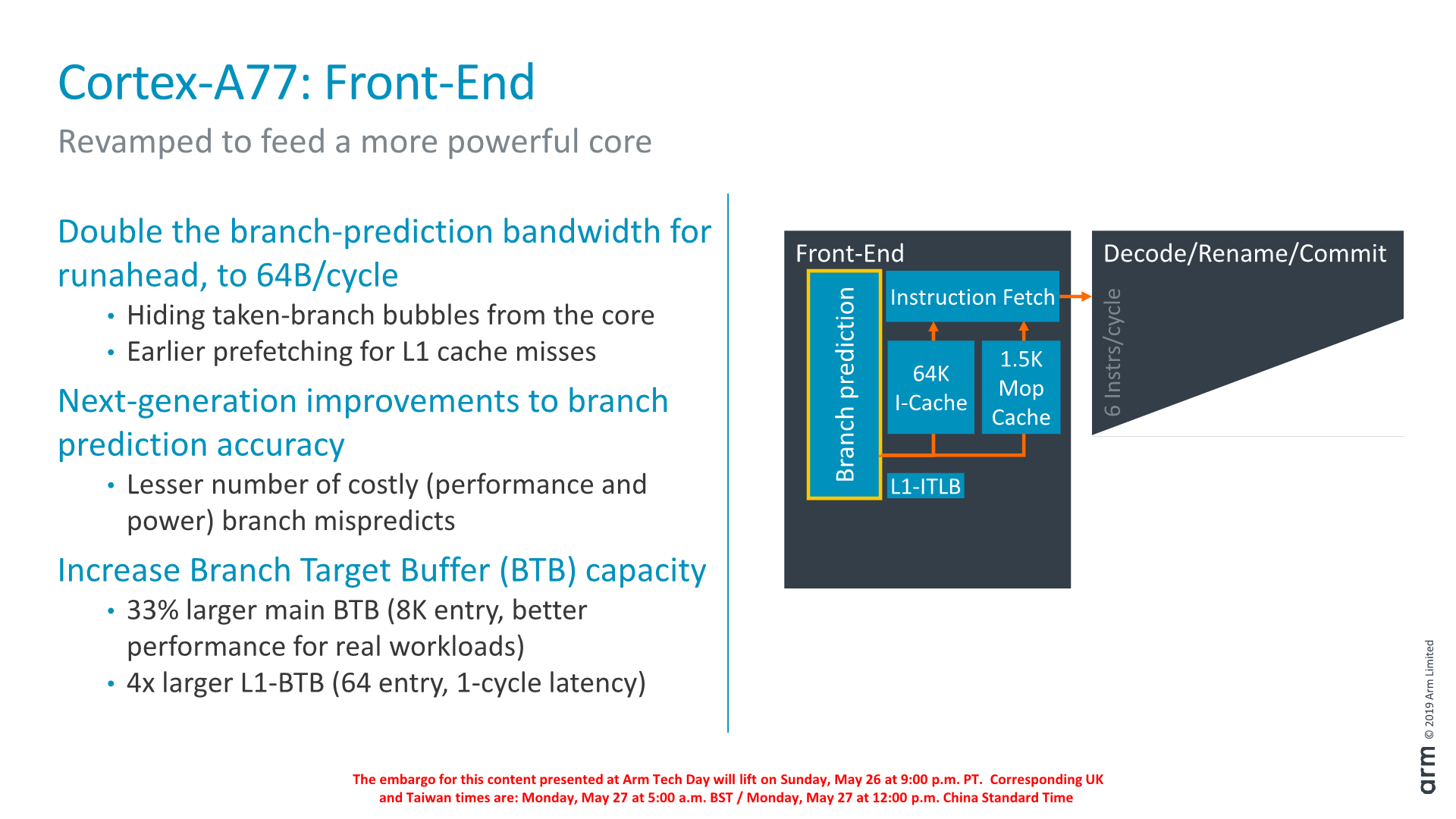
Dwelling deeper into the front-end, a major change in the branch predictor was that its runahead bandwidth has doubled from 32B/cycle to 64B/cycle. Reason for this increase was in general the wider and more capable front-end, and the branch predictor’s speed needed to be improved in order to keep up with feeding the middle-core sufficiently. Arm instructions are 32bits wide (16b for Thumb), so it means the branch predictor can fetch up to 16 instructions per cycle. This is a higher bandwidth (2.6x) than the decoder width in the middle core, and the reason for this imbalance is to allow the front-end to as quickly as possible catch up whenever there are branch bubbles in the core.
The branch predictor’s design has also changed, lowering branch mispredicts and increasing its accuracy. Although the A76 already had the a very large Branch Target Buffer capacity with 6K entries, Arm has increased this again by 33% to 8K entries with the new generation design. Seemingly Arm has dropped a BTB hierarchy: The A76 had a 16-entry nanoBTB and a 64-entry microBTB – on the A77 this looks to have been replaced by a 64-entry L1 BTB that is 1 cycle in latency.

Another major feature of the new front-end is the introduction of a Macro-Op cache structure. For readers familiar with AMD and Intel’s x86 processor cores, this might sound familiar and akin to the µOP/MOP cache structures in those cores, and indeed one would be correct in assuming they have the similar functions.
In effect, the new Macro-OP cache serves as a L0 instruction cache, containing already decoded and fused instructions (macro-ops). In the A77’s case the structure is 1.5K entries big, which if one would assume macro-ops having a similar 32-bit density as Arm instructions, would equate to about 6KB.
The peculiarity of Arm’s implementation of the cache is that it’s deeply integrated with the middle-core. The cache is filled after the decode stage (in a decoupled manner) after instruction fusion and optimisations. In case of a cache-hit, then the front-end directly feeds from the macro-op cache into the rename stage of the middle-core, shaving off a cycle of the effective pipeline depth of the core. What this means is that the core’s branch mispredicts latency has been reduced from 11 cycles down to 10 cycles, even though it has the frequency capability of a 13 cycle design (+1 decode, +1 branch/fetch overlap, +1 dispatch/issue overlap). While we don’t have current direct new figures of newer cores, Arm’s figure here is outstandingly good as other cores have significantly worse mispredicts penalties (Samsung M3, Zen1, Skylake: ~16 cycles).
Arm’s rationale for going with a 1.5K entry cache size is that they were aiming for an 85% hit-rate across their test suite workloads. Having less capacity would take reduce the hit-rate more significantly, while going for a larger cache would have diminishing returns. Against a 64KB L1 cache the 1.5K MOP cache is about half the area in size.
What the MOP cache also allows is for a higher bandwidth to the middle-core. The structure is able to feed the rename stage with 64B/cycle – again significantly higher than the rename/dispatch capacity of the core, and again this imbalance with a more “fat” front-end bandwidth allows the core to hide to quickly hide branch bubbles and pipeline flushes.
Arm talked a bit about “dynamic code optimisations”: Here the core will rearrange operations to better suit the back-end execution pipelines. It’s to be noted that “dynamic” here doesn’t mean it’s actually programmable in what it does (Akin to Nvidia’s Denver code translations), the logic is fixed to the design of the core.
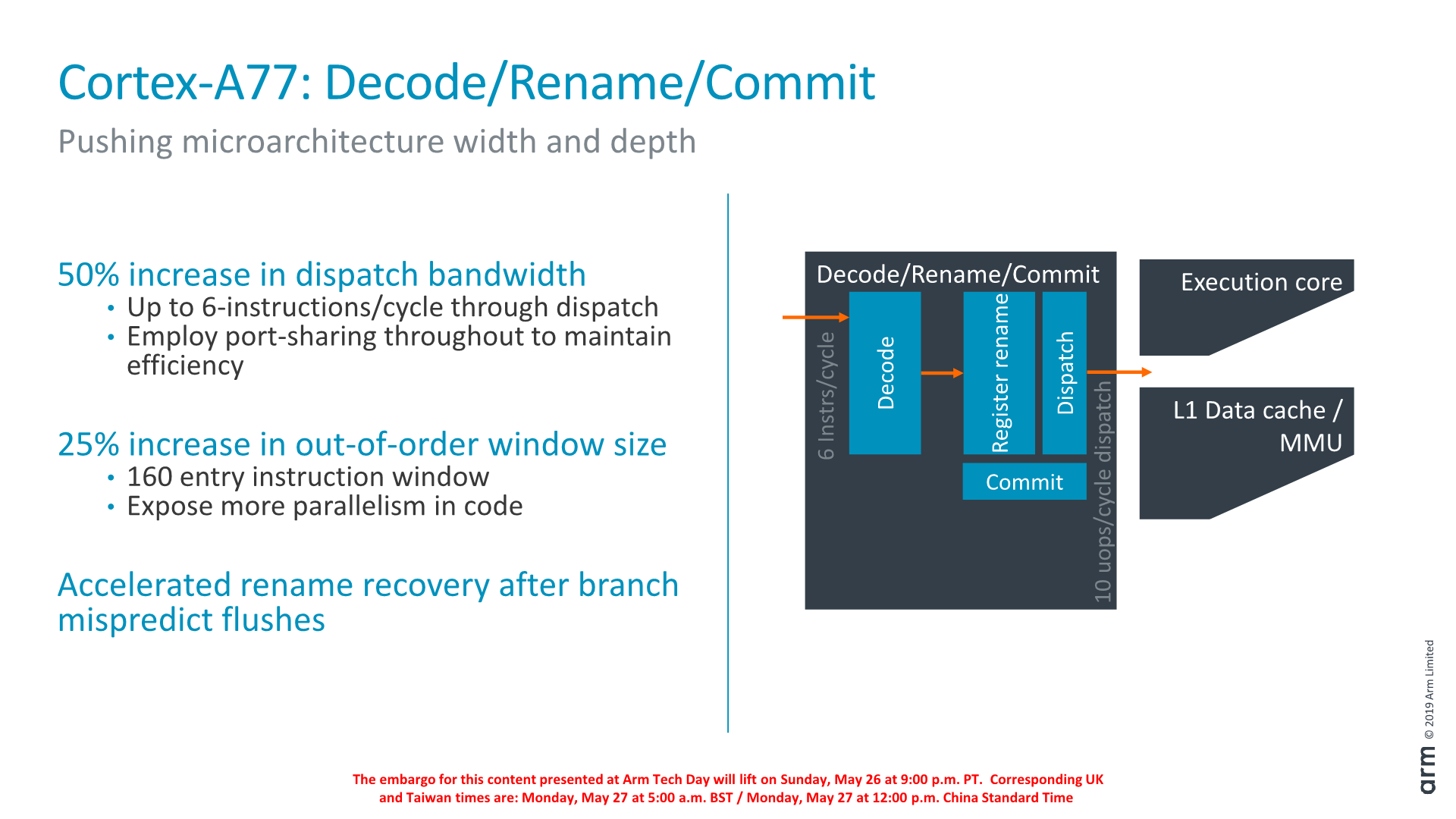
Finally getting to the middle-core, we see a big uplift in the bandwidth of the core. Arm has increased the decoder width from 4-wide to 6-wide.
Correction: The Cortex A77’s decoder remains at 4-wide. The increased middle-core width lies solely at the rename stage and afterwards; the core still fetches 6 instructions, however this bandwidth only happens in case of a MOP-cache hit which then bypasses the decode stage. In MOP-cache miss-cases, the limiting factor is still the decoder which remains at 4 instructions per cycle.
The increased width also warranted an increase of the reorder buffer of the core which has gone from 128 to 160 entries. It’s to be noted that such a change was already present in Qualcomm’s variant of the Cortex-A76 although we were never able to confirm the exact size employed. As Arm was still in charge of making the RTL changes, it wouldn’t surprise me if was the exact same 160 entry ROB.








108 Comments
View All Comments
Lodix - Monday, May 27, 2019 - link
Andrei, are you still expecting HiSilicon to launch a Kirin SOC using ARM IP later this year with all that is happening ? It is very sad the current situation.Andrei Frumusanu - Monday, May 27, 2019 - link
The SoC certainly is ready to go to manufacturing. What happens with devices is another question.Violet Giraffe - Tuesday, May 28, 2019 - link
You find it said that a certain company finally has to pay for its practice of stealing and selling IP they do not own? I don't.a94 - Wednesday, May 29, 2019 - link
You know that Huawei always pay the royalty for licensing ARM IP to make their Kirin right? If not, how did they announce that a version of Kirin was based on Cortex something without ARM suing them? Maybe, Huawei did steal some IP from another company, but to be banned of access to a product they always pay(ARM) is ridiculouscolinisation - Monday, May 27, 2019 - link
Hi Andrei,Can you comment at all on the possibility of an A55 refresh? I realise A55 recently replaced A53, but I wonder where ARM go from here. It seemed with the Neoverse E1/A65 out there, we would see a relatively quick replacement. In your opinion is this on the cards or does the move to out of order execution mean too high a power penalty currently with that design.
Thanks
Santoval - Monday, May 27, 2019 - link
On average a new "small" ARM core is launched with every third "big" ARM core. A55 was not launched very recently, it launched along with the A75 core in 2017. Since the A77 cores are also intended to be paired with the A55 cores, the successor of A55 should be launched along with the A78 core -assuming it is called that way- which currently has the codename Hercules.Andrei Frumusanu - Tuesday, May 28, 2019 - link
The A65 won't be seen in mobile because SMT doesn't make sense in mobile, it's not energy efficient.We should expect a new small core along with the next major refresh from the Sophia team after A78/Hercules in 2 years.
name99 - Tuesday, May 28, 2019 - link
The slow cadence for small cores is REALLY delaying the pickup of ARM extensions. How long till ARM proper is shipping PAE and the SPECTRE-instructions in 8.5?They’ve got to see that this is no longer a sensible strategy!
peevee - Tuesday, May 28, 2019 - link
Given that even A76 has about the same perf/W as A55, do A55s even make any sense now?And SMT is a much cheaper way to take advantage of large back-end than a very complex OoO we have now.
Meteor2 - Monday, June 3, 2019 - link
Maybe at the top-end, but does A76 match A55 at lower power levels? Which is what A55 is optimised for?