Imagination Joins the AI Party, Announces PowerVR Series 2NX Neural Network Accelerator
by Nate Oh on September 21, 2017 3:00 AM EST
In conjunction with today’s PowerVR Series 9XE and Series 9XM announcement, Imagination is revealing a new series of PowerVR-branded hardware IP blocks: the Series 2NX neural network accelerator (NNA). Filling in under the ‘PowerVR Vision and AI’ category as opposed to graphics, the 2NX NNA offers SoC designers dedicated low power hardware for neural network computation and inferencing. While there are many practical applications of such neural networks, Imagination identified mobile devices and smart cameras/surveillance as key markets for the 2NX, as well as automotive and set-top boxes.

Imagination’s latest IP announcement comes at a time when the market for AI/neural network processing is booming. As what’s arguably the first new processor technology field in several years to take root and reach a rapid growth phase, the industry has been racing to develop neural network processors, establish standards, and otherwise push the boundaries of hardware and software to see just what neural network processing truly can and can’t do. Neural network processing is still in its early, wild west days, but this is the point where companies can attempt to stake their claim in a growing market and, as time goes by, try to be a market leader once the technology matures.
With the announcement of Series 2NX, Imagination is joining Intel, NVIDIA, Apple, Huawei, and other vendors in scoping out the early days of the field. For Imagination this is a natural extension of their existing PowerVR GPU technologies, as current neural network processing is at a very high level a far more restricted form of GPU compute. So this is a field that Imagination can relatively easily get into, and leverage much of their current strengths. At the same time however, for the struggling company this is a badly needed growth market, one that could help the company turn its fortunes. To some degree there’s also a need to keep up with their peers – Imagination would likely be short-sighted not to pursue this – but success here would certainly be a game-changer for the company. The risk, of course, is that the market is still young, and while everyone is eager to get into it, hardware and software vendors alike haven't fully nailed down what tasks can and can't be efficiently handled by a neural network. Being the "hot" thing in tech, right now it's tempting to solve every problem with neural networking, an overzealousness that will abate as the market matures.
Moving on to the technology itself, with the 2NX, Imagination claims the industry’s highest inferencing performance, as well as performance in terms of power consumption (inferences/mW) and area (inferences/mm2). Size-wise, Imagination sees their 2NX solution as going well with a 9XE/9XM GPU, saying that the combined area of a 9XE GPU and 2NX NNA is similar to the total size of a competing mobile GPU. For that mobile market, Imagination plans Android support for the 2NX, and cites the importance of the 2NX’s optional memory management unit (MMU) for Android and other more complex OS’s. In the context of those features, Imagination did explain that they designed the 2NX with mobile designs in mind.
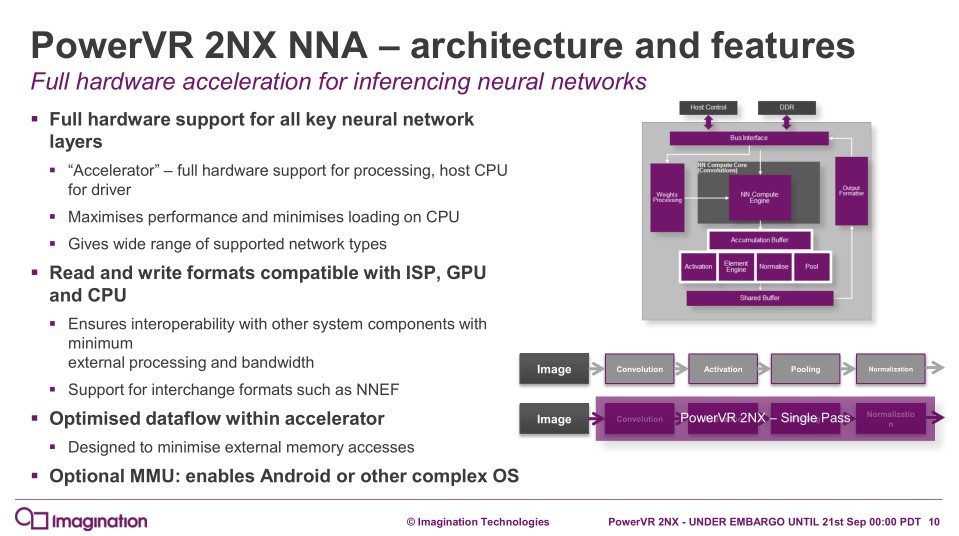
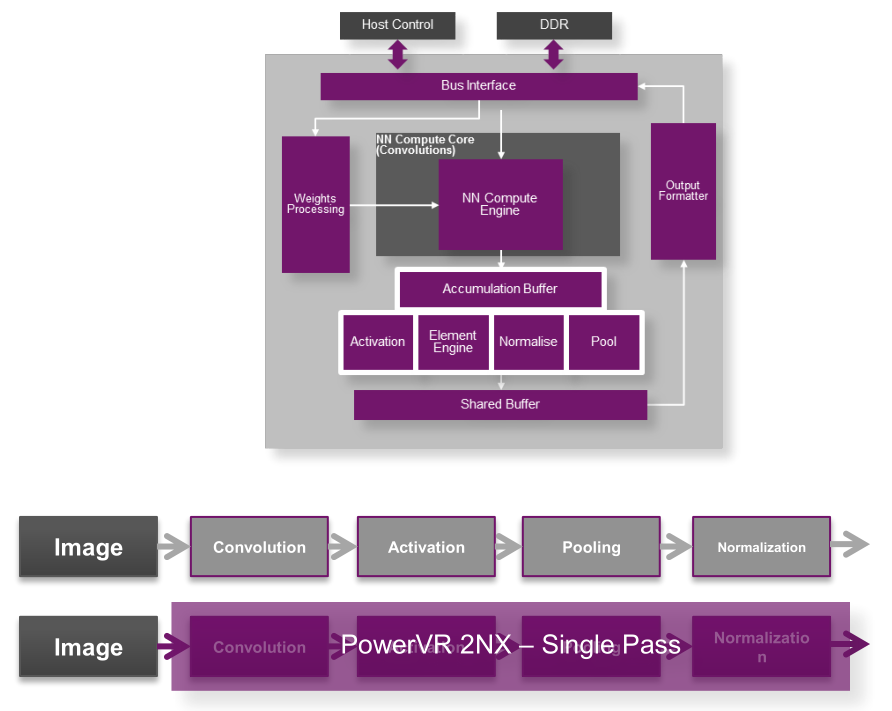
Architecture-wise, like the PowerVR graphics, the 2NX offers a variety of options as it is meant to be licensed out and used in a range of customer-specific use cases. To that end, Imagination describes a single 2NX core as capable of handling 128 to 1024 16-bit and 256 to 2048 8-bit multiply-and-accumulate operations (MACs) per clock, with multiple cores permitting scaling beyond 2048 8-bit MACs/clock.

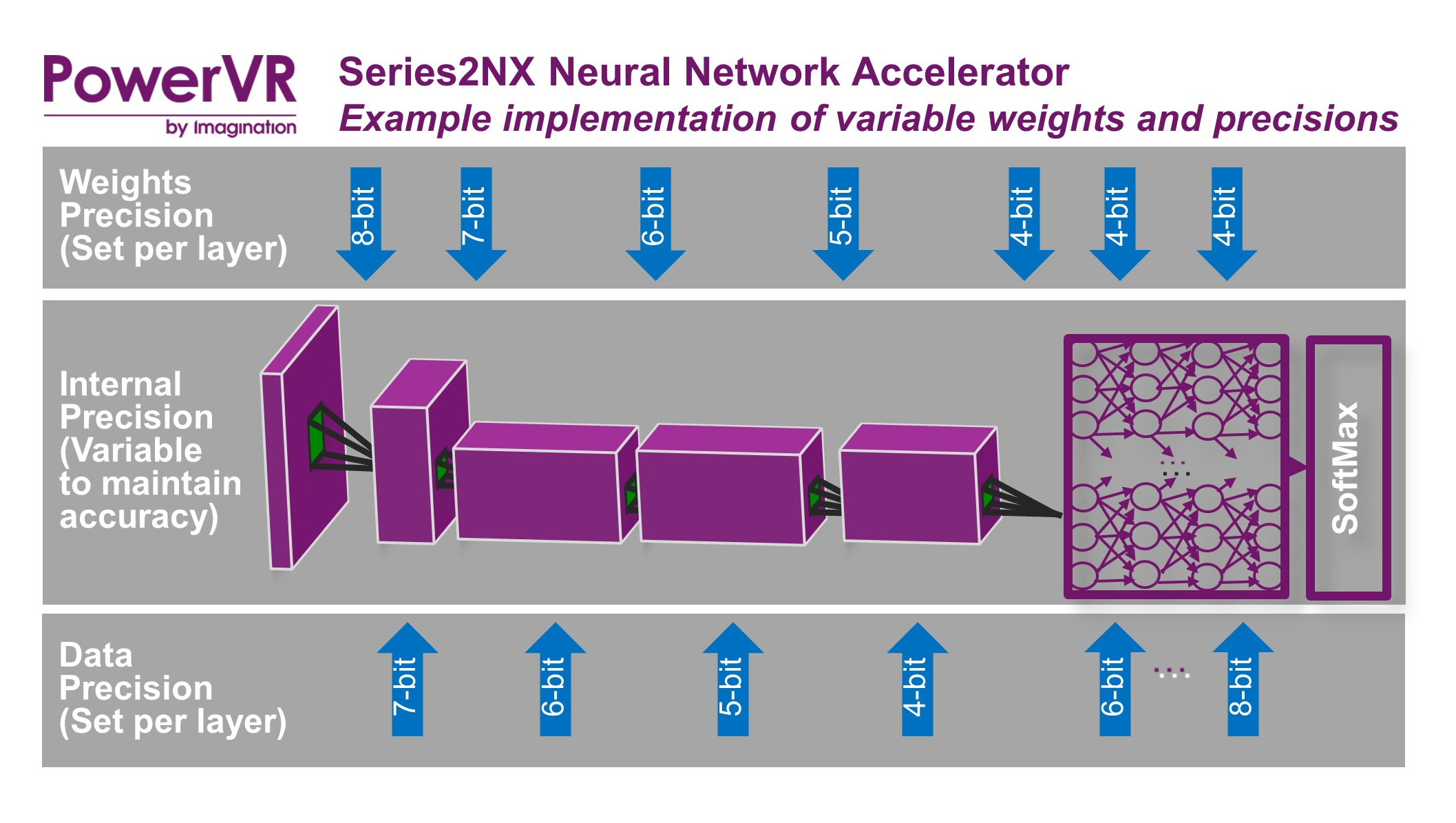
The 2NX accelerator also possesses flexible bit-depth for data and weights, with 16, 12, 10, 8, 7, 6, 5, and 4-bit support, and can be mixed on different layers. In terms of the higher precision 16-bit support, Imagination cites areas like automotive applications, where 16-bit support is mandated. The 2NX also has full variable precision on the internal data formats, with “FP32 precision where required, inside the accumulator with variable output precision.” In turn, the variable weights and precisions can be used to save power and bandwidth as the situation warrants.
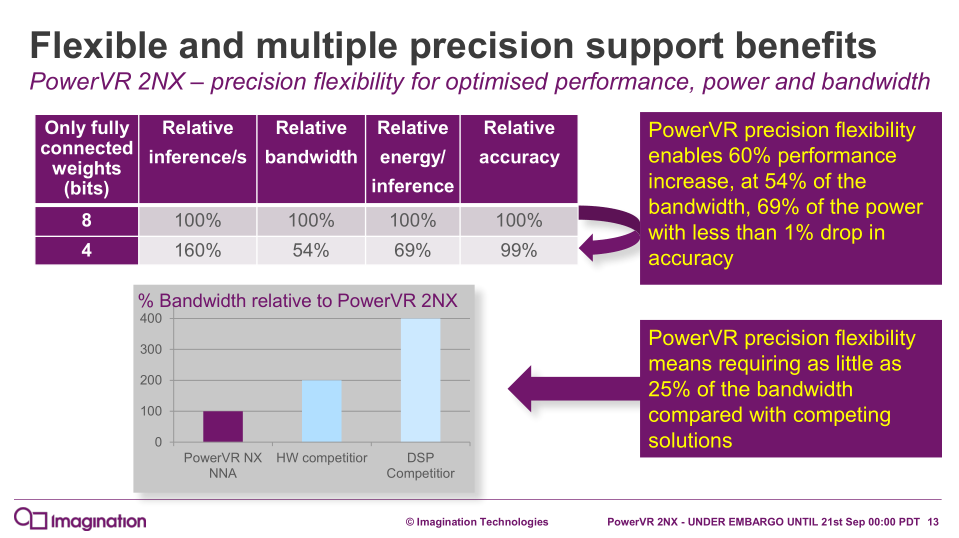
With a specialized driver for the host CPU, the 2NX does all the neural network processing in dedicated hardware blocks, and supports read/write formats compatible with other system blocks like ISPs, GPUs, and CPUs. The 2NX also supports neural network interchange formats, such as Khronos’ NNEF. Imagination has also taken steps to reduce usage of external memory, and offers the aforementioned MMU for the 2NX, especially in light of Android support.
In terms of use cases, like other low-power inferencing processors that have been pitched in the last couple of years, Imagination’s focus is inferencing at the edge. This means automotive, security cameras, smartphones, and other devices that either are their own sensors or close to said sensors, and where there either isn’t the time or connectivity to send all data back to a central host. It’s also at the edge where some of the greatest potential gains from neural network inferencing can be found, as when it’s used correctly, neural network processing can achieve similar results with a fraction of the power consumption of a GPU or DSP (never mind a CPU).
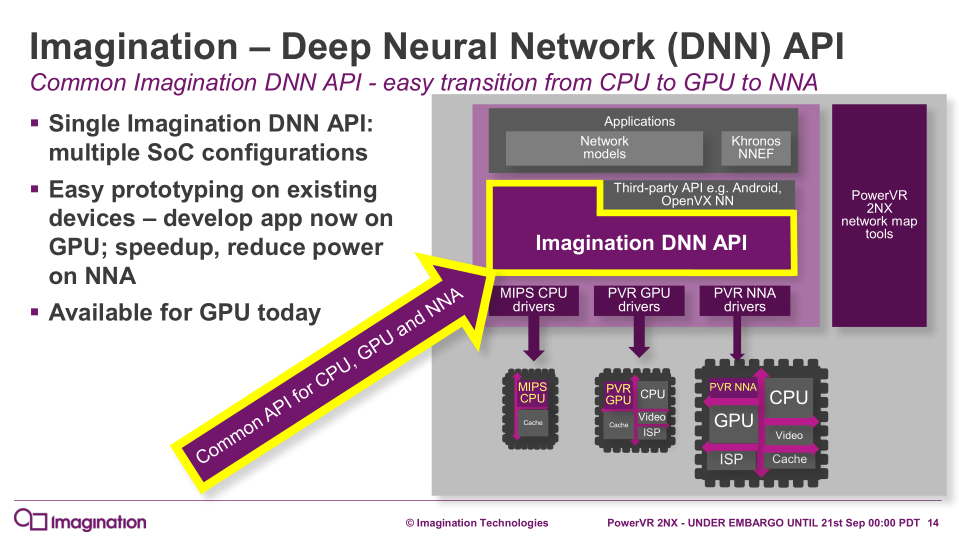
On the software-side, Imagination is releasing their Deep Neural Network (DNN) API, applicable to CPUs, GPUs, and its new NNA. This has the advantage of allowing development and prototyping for the 2NX without having the 2NX on hand, as well as when dealing with multiple SoC configurations.
In translating the neural network models to the 2NX itself, Imagination is also providing tuning and evaluation tools, including the PowerVR NX Mapping Tool. As an optional step, from the typically FP32 models trained with frameworks such as TensorFlow and Caffe, PowerVR’s own framework can retrain that model for certain precisions and weights, and thus optimize for the 2NX.

Like the rest of the PowerVR family processors, the 2NX is essentially an IP core that is licensed out to SoC designers. For the mobile sphere, this PowerVR 2NX announcement brings to mind recent announcements of implemented neural network processors inside Huawei’s Kirin 970 and Apple’s A11 Bionic. Earlier, Huawei revealed that the Kirin 970 NPU was accessible by Android Neural Network API support, and in the context of the 2NX for Android, Imagination referred to that API as well, but details are light at this time. For the time being, the 2NX cannot be directly compared to those dedicated inferencing hardware, but will be an interesting topic to revisit as 2NX-equipped products roll out.
The PowerVR 2NX NNA is available now for licensing, and interested parties may contact Imagination directly.
Source: Imagination Technologies








18 Comments
View All Comments
KristofBeets - Thursday, September 21, 2017 - link
Couple of their videos help to put performance into context:GPU inference: https://youtu.be/QGWNJM9DJzE
NNA inference: https://youtu.be/ut948L1YL0g
Yojimbo - Thursday, September 21, 2017 - link
I can't watch those videos at the moment, but the NNA doesn't really compete with GPU inference. GPU inference relies on large batch sizes for efficiency. It's geared towards data center inference. This NNA is for edge devices. A better comparison would be with Intel's Movidius Myriad X or NVIDIA's upcoming DLA.iwod - Thursday, September 21, 2017 - link
>In conjunction with today’s PowerVR Series 9XE and Series 9XM announcement,Am i suppose to Google this myself?
yannigr2 - Thursday, September 21, 2017 - link
Yes you are. If you are lazy, just hire someone to google for you.name99 - Thursday, September 21, 2017 - link
You could hire LouiseHolt! She seems to spend her life cruising AnandTech boards looking for work...Threska - Thursday, September 21, 2017 - link
Say it's booming but the only field Imagination plays in is mobile. Cloud and autonomous vehicles would be someone else's playground.p1esk - Thursday, September 21, 2017 - link
I'm surprised they didn't go all the way to 1 bit precision for both weights and data.Krysto - Thursday, September 21, 2017 - link
I don't think we've heard from too many companies that need AI that they would like to take advantage of 1-bit precision computing. I imagine it would only be useful for some very specific tasks, but not the majority of AI inference tasks.p1esk - Thursday, September 21, 2017 - link
This chip is designed for a very specific task: image recognition using convolutional neural networks. Which work with 1 bit precision with moderate accuracy drop (improving every few months).jospoortvliet - Monday, September 25, 2017 - link
This core can't do voice recognition or text prediction?