Imagination Announces First PowerVR Series2NX Neural Network Accelerator Cores: AX2185 and AX2145
by Nate Oh on June 8, 2018 3:00 AM EST
Since Imagination’s original announcement of the PowerVR Series2NX Neural Network Accelerator (NNA) last fall, the machine learning and AI “hype train” has not paused in the slightest. For the embedded and mobile space where the 2NX NNA competes in, there have been plenty of AI hardware developments in that time: CEVA’s NeuPro, Cambricon’s neural processing unit (NPU) in the Kirin 970, and yet more details of Arm’s “Project Trillium” machine learning processor, which has yet to be finalized. Today is Imagination’s turn, and the company is announcing the first products in the 2NX NNA family: the higher-performance AX2185 and lower-cost AX2145.

Given the traditional spectrum of embedded and mobile markets, Imagination is positioning the AX2185 for higher-end smartphones, smart surveillance systems, and automotive, while pushing the low-bandwidth-tuned AX2145 for lower-end applications, including DTV and set-top boxes (STB). For all these use-cases, particularly mobile and smart surveillance, Imagination sees these two new IP blocks as providing superior inferencing performance within a given power profile and silicon footprint. But as with their previous briefing, specific numbers were sparse.
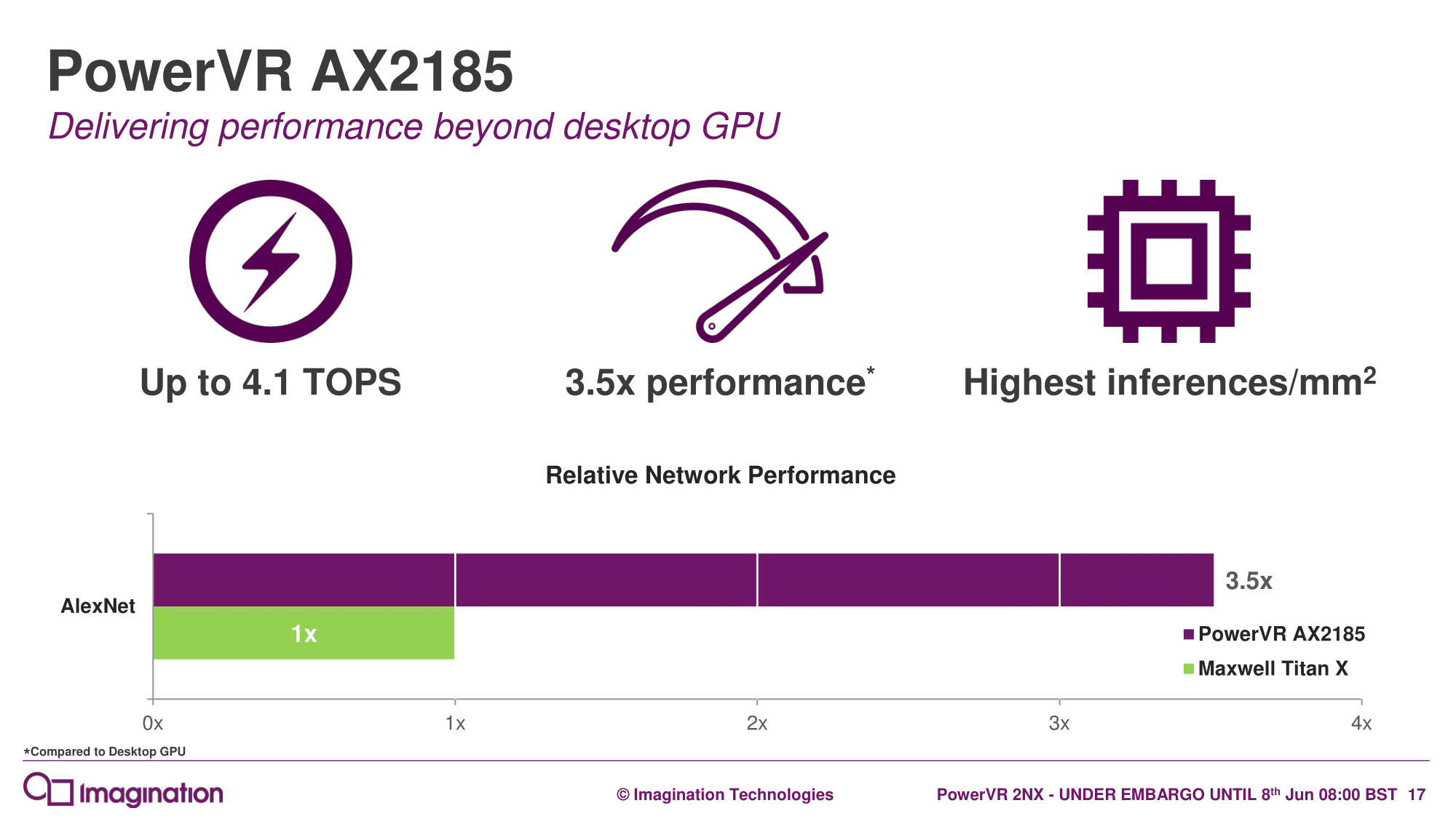
In any case, Imagination is claiming up to 4.1 TOPS on the AX2185 and 1 TOPS for the AX2145; these metrics seem based off of the maximum 2048 8-bit multiply-and-accumulate operations (MACs) per clock capability. It was noted that AX2185 comes equipped with eight full-width compute engines, but it is not clear if this is the same for the AX2145, which was optimized for ultra-low-bandwidth.
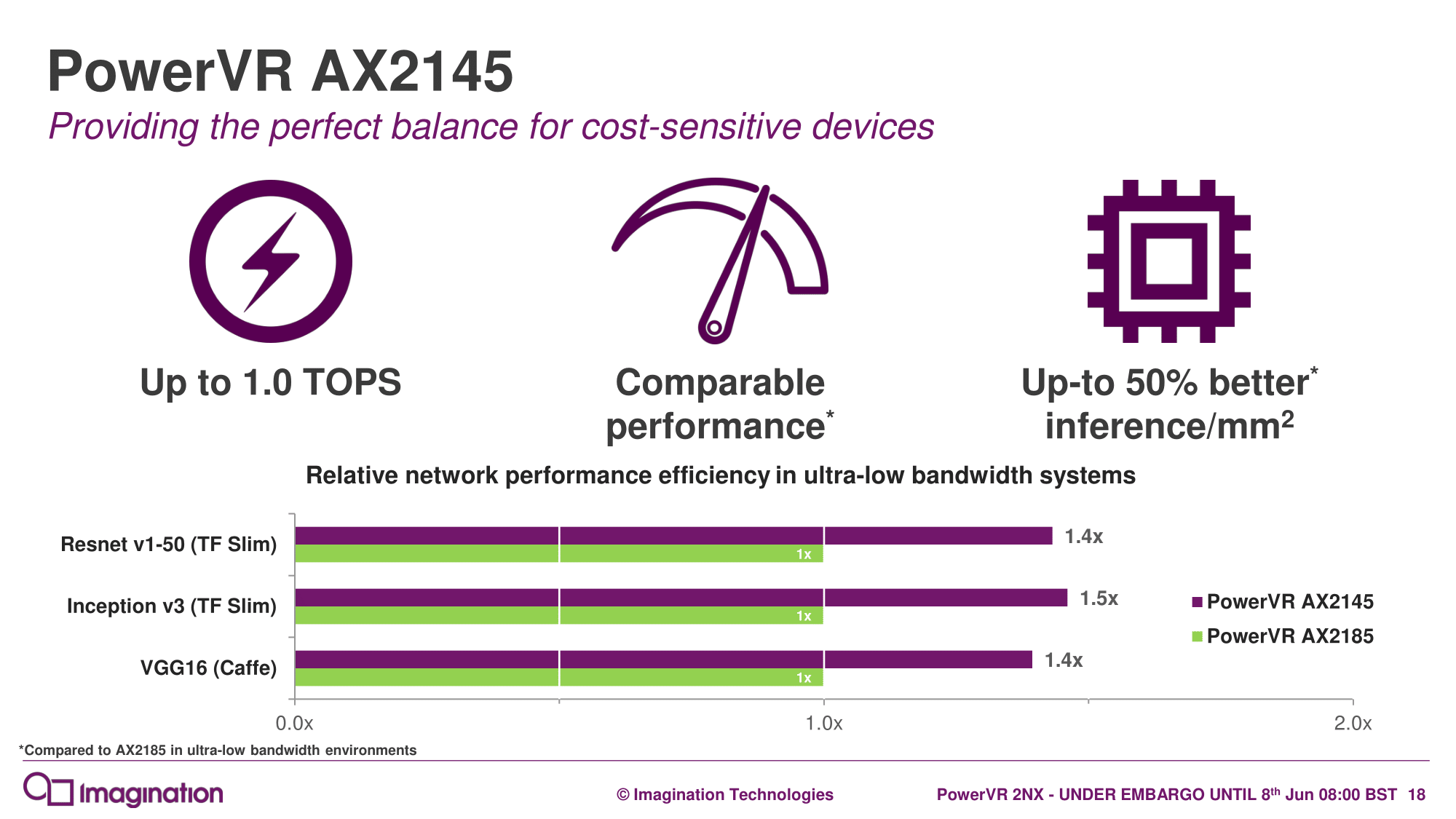
While Imagination stated that the AX2185 had already been delivered to select partners, Imagination considered the AX2185 and AX2145 more akin to 2nd generation NNA cores, noting an unannounced predecessor that was developed alongside lead customers. Details of the resulting optimizations, however, were not disclosed.
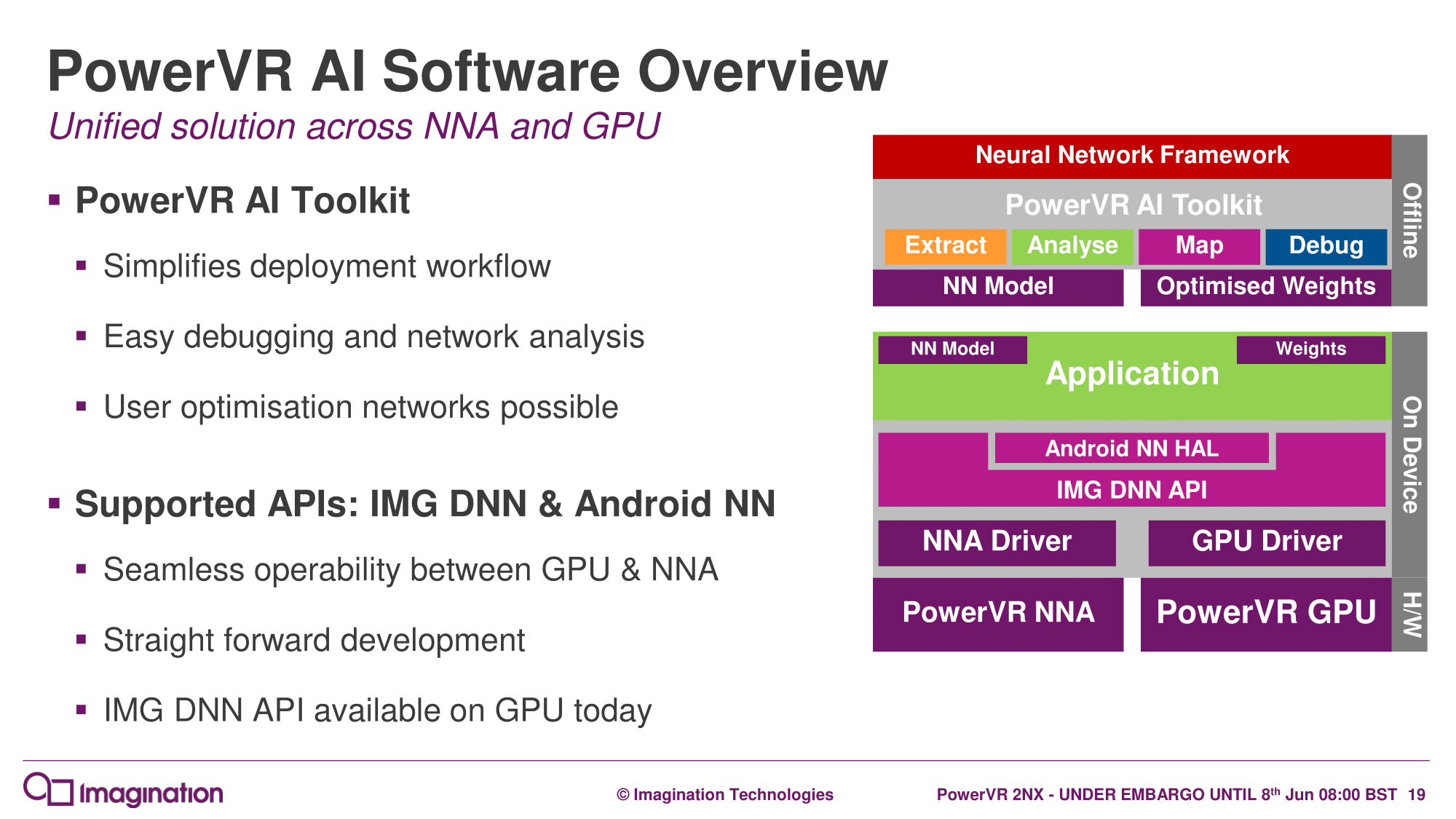
Architecturally, then, nothing has changed since the initial announcement last September, and the same highlights apply: flexible bit-depths for data and weights, variable internal precision, data format interoperability with other system components (ISP, GPU, CPU), and the software ecosystem. For the latter, Imagination reiterates its NNA oriented development tools such as the PowerVR AI Toolkit and Imagination DNN API, with both new IP cores supporting the Android NN API. Ultimately, Caffe and TensorFlow are largely the primary intended frameworks for the NNA.
As we have mentioned throughout our ongoing coverage of neural network hardware IP, it is still too early to gauge competitiveness, particularly. Going forward though, Imagination’s natural integration opportunities with its own PowerVR GPUs will be something to keep an eye on.
The AX2185 and AX2145 are available for licensing today, and interested parties may contact Imagination directly.





Related Reading
- Arm Details "Project Trillium" Machine Learning Processor Architecture
- HiSilicon Kirin 970 - Android SoC Power & Performance Overview
- Imagination Joins the AI Party, Announces PowerVR Series 2NX Neural Network Accelerator
- CEVA Launches Fifth-Generation Machine Learning Image and Vision DSP Solution: CEVA-XM6
- CEVA Announces NeuPro Neural Network IP
Source: Imagination Technologies








4 Comments
View All Comments
Santoval - Friday, June 8, 2018 - link
Why did Imagination compare machine learning performance to Maxwell Titan X, a graphics card released 3 years and 3 months ago, with zero machine learning acceleration in mind (no tensor cores) and basically two generations behind than the (very soon to be released) current one?I imagine it has something to do with Volta's 100+ TOPS of machine learning and whatever expected fraction of that the upcoming consumer cards will have. I fully realize that it is unfair to compare mobile with desktop parts but Imagination did precisely that, so I am just returning the comparison back to them.
Kvaern1 - Friday, June 8, 2018 - link
First marketing do the graph they want. Then they find another product which matches it.Alexvrb - Saturday, June 9, 2018 - link
I believe that's why they chose it. They're showing that using traditional GPUs (at approx. the level of sophistication as current mobile GPUs) isn't possible and that you need acceleration. They did so using a well-known high-profile example that actually was used for that sort of thing before specialized cores were integrated.It will be interesting to compare the efficiency of some of these lower-power accelerators.
CiccioB - Monday, June 11, 2018 - link
They should have compared to nvidia new Tegra chip, not a desktop card designed for 3D rendering in mind more than 3 years old (why then not a P100 solution that alone is already 3x faster than Maxwell in AI tasks? Let alone Volta)That reminds me of Intel comparing their last brand new 22nm Atoms with latest PP compared to Cortex-A9 chip just to have the graph with a smaller longer colored bar.
We know the end of that story. I think this won't be much different