Cadence Cerebrus to Enable Chip Design with ML: PPA Optimization in Hours, not Months
by Dr. Ian Cutress on July 22, 2021 10:45 AM EST
The design of most leading edge processors and ASICs rely on steps of optimization, with the three key optimization points being Performance, Power, and Area (and sometimes Cost). Once the architecture of a chip is planned, it comes down to designing the silicon of that chip for a given process node technology, however there are many different ways to lay the design out. Normally this can take a team of engineers several months, even with algorithmic tools and simulation to get a good result, however that role is gradually being taken over with Machine Learning methods. Cadence today is announcing its new Cerebrus integrated ML design tool to assist with PPA optimization – production level silicon is already being made with key partners as the tool directly integrates into Cadence workflows.
Place and Route: The Next Stage of Automation
The act of finding the best layout for a chip, or even for a part of a chip such as a macro or a library, has already been optimized for many years – engineers plug in details about the parts of the design with a variety of parameters and run overnight simulations to find the best layout. These algorithmic implementations of ‘Place and Route’ have been built over time to be very complex, but rely on equations and if/then statements to try and predict the best design. Very often this is a slow process, with the engineering team having to go back, tweak the design, and attempt again. The designs are then simulated for expected performance and power to find which is the best. There is no level of the software ‘learning’, as the algorithm is defined by hard and fast rules.
The advancement of machine learning this decade has put a new twist on traditional Place and Route algorithms. Companies that build EDA (Electronic Design Automation) tools to design chips have been researching into the best way to integrate machine learning into their algorithms with the hope that the software alone can understand what it is doing, make iterative improvements, and essentially be left to its own devices to get the best result. Beyond this, it allows for parallel analysis across many systems – one of the main limitations of traditional EDA test and simulation is that it is single thread limited and doesn’t scale, whereas ML would allow for more parallel testing and simulation.
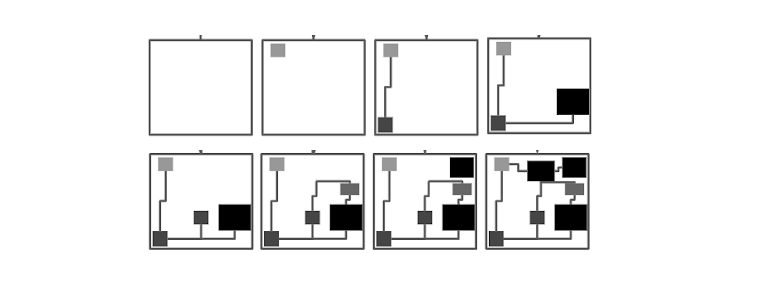
An example of ML-assisted design from Google
In speaking to EDA companies that are discussing ML tools, the main benefit of this technology is that it creates a simpler workflow but also produces better processors almost equivalent to a benefit of a whole process node. What would take a team of a dozen engineers half a year to find a good design can be superseded by one or two engineers over a couple of weeks, and it would end up with a better PPA than the human plus non-ML methods ever could.
How To Enable Machine Learning on EDA
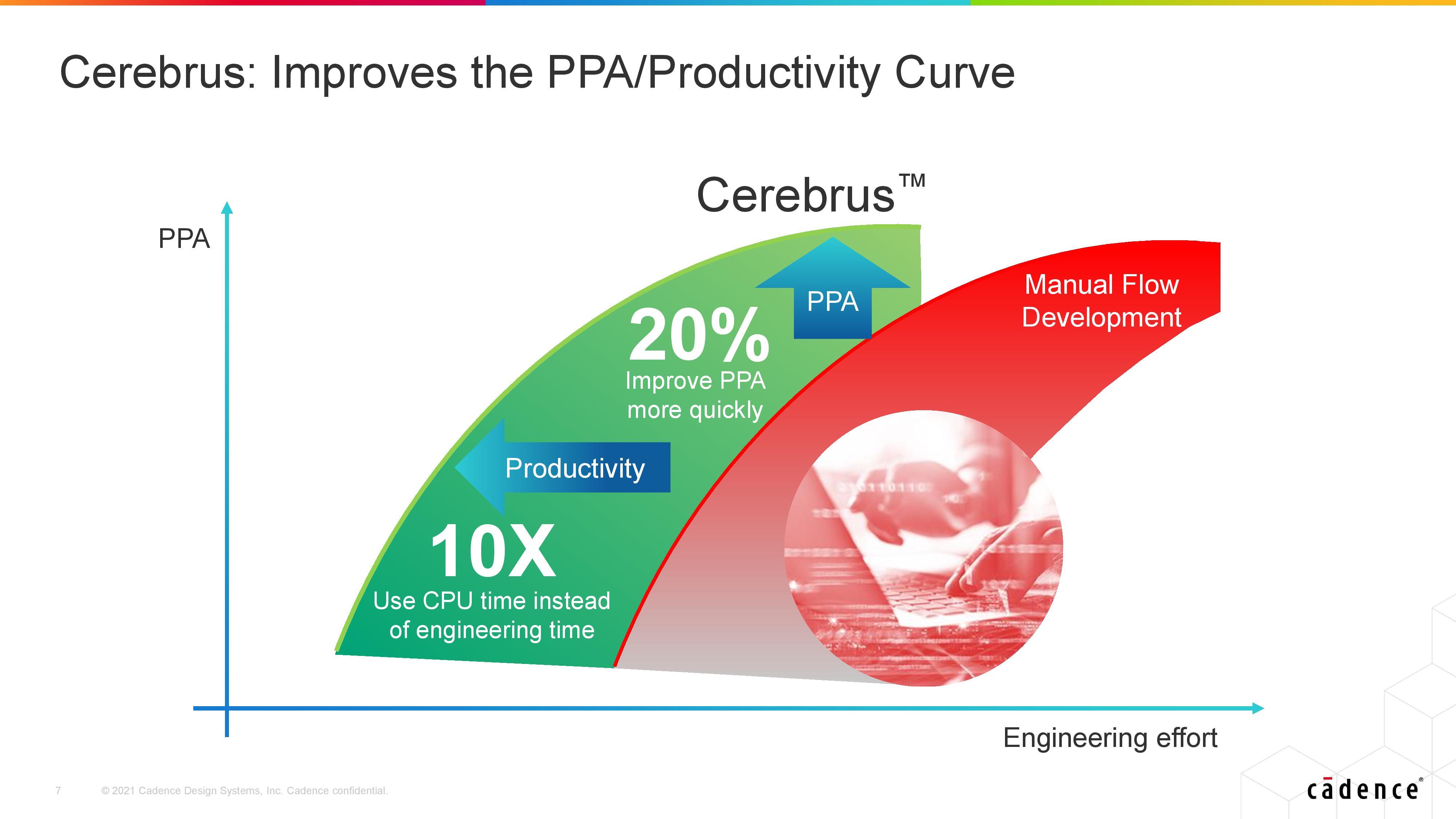
Today’s announcement is from Cadence, one of the top EDA tool vendors, with the launch of their new Cerebrus technology. Integrated directly into the Cadence toolchain, Cerebrus can work at any level of the stack design, from high level definitions in System C down to standard cells, macros, RTL and signoff, and it allows an engineer to give it objects with defined specifications at any level and optimize for each. The automated floorplanning allows for the engineer to specify optimization points beyond regular PPA, such as wire length, wire delay, power grid distribution, IR drop, IO placement with respect to physical chip boundaries, and other parameters.

Cadence’s Cerebrus tool uses reinforcement machine learning for its optimization process – the technology is already in hands with key customers and in use with chip design, although today’s announcement makes it available to the wider customer base. Cadence states that the machine learning workflow is designed such that it can start from an untrained model and find an optimized point in 50-200 iterations, and within an organization models can be reused if a number of constraints are followed (process node PDK, similar structure) reducing that time even further. Theoretically an organization can build a library of pre-trained models, and enable Cerebrus to attempt the best one for the task, and if that fails, start anew and still get a great result.
One of the common questions I ask about these new advancements is how well the end design can be fed back to engineers to help with higher level design – it is all very well the ML portion of the tool working on reinforcement learning, but is there anything that can be done to assist the engineer in their understanding of their own architectural implementation. In speaking with Cadence’s Kam Kittrell, he explained that a key value of their tool is a replay feature – it records each iteration in the reinforcement learning process, allowing engineers to step through how each cycle decided to do what it did, allowing the engineer to understand why the end result the way it is. I haven’t heard of any other EDA company having this feature at this time.
Cadence Cerebrus Case Studies
As part of the announcement today, two of Cadence’s partners contributed quotes to the efficacy of the technology, however it is the case studies provided that are worth looking over.
First up is a 5nm mobile CPU, which we believe to be part of Cadence’s partnership with Samsung Foundry. According to the information, the Cerebrus tool helped a single engineer in 10 days achieve a 3.5 GHz mobile CPU while also saving leakage power, total power, and improving transistor density. Compared to a predicted timeline using almost a dozen engineers over several months, it is predicted that Cerebrus improved the best hand tuned design for a +420 MHz frequency gain, saving 26 mW of leakage power and 62 mW of total power.

62 mW of total power, as a 3% saving, suggests a 2 W chip (or core). Right now Samsung does not have a 3.5 GHz 5nm mobile processor in the market, but it does suggest that future designs will be more optimized than before.
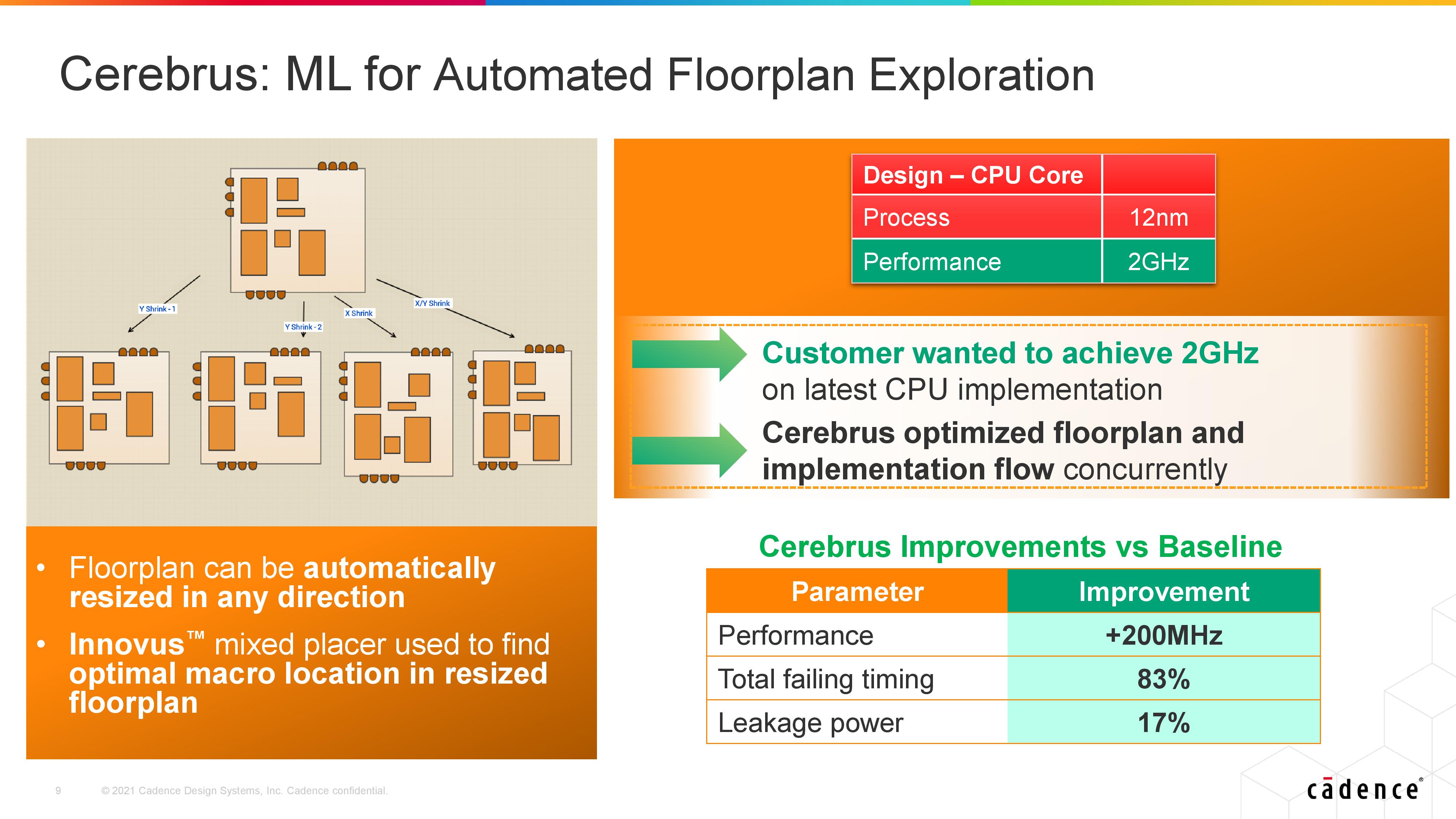
The second case study involves floorplan optimization and implementation optimization concurrently. In this instance Cadence says a customer wanted a 12nm CPU core at 2 GHz with the lowest power and lowest area, and the Cerebrus tool was able to optimize for that 2 GHz point, reducing wire delay timing by 83% as well as leakage power by 17%.
Samsung Foundry is already rolling out Cerebrus as part of its DTCO program for partners that have a Cadence based workflow.
The Future of ML-enhanced EDA Tools
We recently reported a similar story from the other heavyweight in the EDA industry, Synopsys, about its DSO.ai software. Synopsys has a keynote titled ‘‘Does Artificial Intelligence Require Artificial Architects?’ at this year’s Hot Chips conference, where we expect to hear more information about the work they’re doing with customers. In a similar light, we expect Cadence to also discuss more about wins with its Cerebrus tools.
However, a question I put both companies is about the evolution of the software. There are ultimately two roadmaps for software like DSO.ai and Cerebrus – function and performance. To a certain extent it’s easy to talk about a roadmap of function as the companies’ research and enable ML tools to work across more of the toolchain (as well as potentially violating standard abstraction layer boundaries). But the performance is a big question – while scaling out performance with more tests is ‘easy’ to build for, developing relative ML algorithms that are easier to find the best layouts is going to be a very wide field to discover. Floorplanning designs have millions of degrees of freedom to optimize for, and one of the limitations of human involvement is getting stuck going down one particular design route; with so much to explore, neither company yet is discussing what their plans are to ensure that ML-assisted design can overcome these potential obstacles. Most likely, as the technology becomes more widely adopted, exactly how that development with coalesce into actual research and product roadmaps might become something more tangible for a roadmap of sorts.
Related Reading
- New Cadence Transient EM Simulation Tools: 3D Clarity
- Cadence DDR5 Update: Launching at 4800 MT/s, Over 12 DDR5 SoCs in Development
- Samsung’s 5nm EUV Technology Gets Closer: Tools by Cadence & Synopsys Certified
- Cadence Announces Tensilica Vision Q7 DSP
- Cadence Tapes Out GDDR6 IP on Samsung 7LPP Using EUV
- Using AI to Build Better Processors: Google Was Just the Start, Says Synopsys








19 Comments
View All Comments
Duncan Macdonald - Thursday, July 22, 2021 - link
One more group of engineers will be finding themselves out of jobs. Chip layout is a very specialized area - once the computer based systems are capable of doing this job well then the existing engineers in this area are likely to find themselves without much in the way of marketable skills.Someguyperson - Thursday, July 22, 2021 - link
The most experienced engineers who do chip layout will be perfectly fine and they'll be able to do their jobs a lot better. This will push more junior engineers towards other roles, where being able to learn is more important than expertise. The sky isn't falling.easp - Thursday, July 22, 2021 - link
Job losses will be offset somewhat by a proliferation of designs due to the changing economics brought by these tools.But yeah, this will take a human toll.
mode_13h - Thursday, July 22, 2021 - link
You're presuming the number of chips being designed stays constant. However, what if this lowers the cost and increases the benefits of custom silicon to the point that yet *more* chips are produced? Then, the total employment in the sector might stay roughly constant.Either way, the best move for existing layout engineers is to get trained in using this new generation of EDA tools. Electronic Design Automation has been with us for many decades, this is just the next step.
bobj3832 - Friday, July 23, 2021 - link
I have been doing semiconductor digital physical design for 25 years. In that time I have heard of lots of EDA startups and the big companies like Cadence and Synopsys talk about "Single pass timing closure!" and lots of other revolutionary ideas.I will believe it when I see it.
In 1997 I remember doing the entire physical design for a chip in 3 months with just 3 people. I just finished a chip with 84 blocks on it. It took us 10 months.
My company has a lot of customers that want customized versions of our chips. We turn most of them away because we don't have the resources to do them. It is hard to find good engineers. If this really lets us do a chip in half the time then we will just have even more work because we will start doing all those chips that we didn't have resources for before.
vol.2 - Wednesday, August 4, 2021 - link
Even if that's true, it's no reason not to do it, and it won't change anything to complain about it. These people will just have to shift, and EEs are very hire-able in many Com-Sci related fields.evancox10 - Thursday, July 22, 2021 - link
FYI when they say they reduced "Total failing timing" by 83%, they most likely don't mean that overall wire delay is reduced by 83% - that would be impossible to achieve. Instead, this is likely referring to a metric known as "Total Negative Slack", which is a measure of how close a chip is to meeting overall timing. Some definitions to break this down:"Path" - A timing path is any route from one register to another where data needs to get there within a certain amount of time, generally the length of one clock cycle minus some margin. Any given path includes a mix of combinational gates, wires, and/or buffers, not just "wire delay" between cells.
"Slack" - This is the amount by which a given path meets timing (positive slack) or fails timing (negative slack). So for a 2 GHz clock, the period is 500 picoseconds, maybe you have 50 ps of margin, so you want data to get there within 450 ps. If going from register A -> gate X -> gate Y -> gate Z -> register B takes 475 ps, the negative slack for this path is 25 ps.
Then, Total Negative Slack (TNS) means you just take all the failing timing paths and add up the amount by which they're failing. This gives you a measure of how close you are to "closing timing" for the whole chip.
Why this is important is that when a chip comes out of the first pass of automated place and route (APR), it will almost never close timing 100% and you have to go through timing optimization iterations to get it there. These iterations can take a long time, and the closer you are to the goal when you start, the more likely you are to get there in the end.
mode_13h - Thursday, July 22, 2021 - link
Thanks for the explanation. So, why such margins? Is it driven primarily by manufacturing variations or environmental variations (e.g. voltage, temperature, interference)?To the extent these factors are understood, I wonder if the tools can't eventually tighten the margins, as well.
evancox10 - Friday, July 23, 2021 - link
Lots of reasons for margin, anything from uncertainty in the way delays are estimated/modeled, random variation in clock frequency (“jitter”), or plain old CYA. The modeling of the path timing does attempt to account for the sorts of variation you mention, but no model is perfect. The problem is differentiating between where it is actually needed and where it isn’t. Lots of effort already goes into this, and the low-hanging fruit has been picked.P.S. I pulled the example margin amount out of my rear, don’t take it as necessarily representative.
FullmetalTitan - Saturday, July 24, 2021 - link
That is pretty much it. Design windows have to allow for variation in the manufacturing process, but they also need to account for circuit aging since that can have a very real impact on threshold voltage, leakage, etc. Margins for timing allow for aging gates that may run very slightly slower to not force corrective changes to whole timing domains (real world example of that would be Apple SoC clock down to extend useable life of older models).