Intel Demos Sapphire Rapids Hardware Accelerator Blocks In Action At Innovation 2022
by Ryan Smith on September 28, 2022 7:20 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Sapphire Rapids
- AMX

With Intel’s annual Innovation event taking place this week in San Jose, the company is looking to recapture a lot of technical momentum that has slowly been lost over the past couple of years. While Intel has remained hard at work releasing new products over the time, the combination of schedule slips and an inability to show off their wares to in-person audiences has taken some of the luster off the company and its products. So for their biggest in-person technical event since prior to the pandemic, the company is showing off as much silicon as they can, to convince press, partners, and customers alike that CEO Pat Gelsinger’s efforts have put the company back on track.
Of all of Intel’s struggles over the past couple of years, there is no better poster child than their Sapphire Rapids server/workstation CPU. A true next-generation product from Intel that brings everything from PCIe 5 and DDR5 to CXL and a slew of hardware accelerators, there’s really nothing to write about Sapphire Rapids’ delays that hasn’t already been said – it’s going to end up over a year late.
But Sapphire Rapids is coming. And Intel is finally able to see the light at the end of the tunnel on those development efforts. With general availability slated for Q1 of 2023, just over a quarter from now, Intel is finally in a position to show off Sapphire Rapids to a wider audience – or at least, members of the press. Or to take a more pragmatic read on matters, Intel now needs to start seriously promoting Sapphire Rapids ahead of its launch, and that of its competition.
For this year’s show, Intel invited members of the press to see a live demo of pre-production Sapphire Rapids silicon in action. The purpose of the demos, besides to give the press the ability to say “we saw it; it exists!” is to start showing off one of the more unique features of Sapphire Rapids: its collection of dedicated accelerator blocks.
Along with delivering a much-needed update to the CPU’s processor cores, Sapphire Rapids is also adding/integrating dedicated accelerator blocks for several common CPU-critical server/workstation workloads. The idea, simply put, is that fixed function silicon can do the task as quickly or better than CPU cores for a fraction of the power, and for only a fractional increase in die size. And with hyperscalers and other server operators looking for big improvements in compute density and energy efficiency, domain specific accelerators such as these are a good way for Intel to deliver that kind of edge to their customers. And it doesn’t hurt either that rival AMD isn’t expected to have similar accelerator blocks.
A Quick Look At Sapphire Rapids Silicon
Before we get any further, here’s a very quick look at the Sapphire Rapids silicon.

For their demos (and eventual reviewer use), Intel has assembled some dual socket Sapphire Rapids systems using pre-production silicon. And for photo purposes, they’ve popped open one system and popped out the CPU.

There’s not much we can say about the silicon at this point beyond the fact that it works. Since it’s still pre-production, Intel isn’t disclosing clockspeeds or model numbers – or what errata has resulted in it being non-final silicon. But what we do know is that these chips have 60 CPU cores up and running, as well as the accelerator blocks that were the subject of today’s demonstrations.
Sapphire Rapids’ Accelerators: AMX, DLB, DSA, IAA, and AMX
Not counting the AVX-512 units on the Sapphire Rapids CPU cores, the server CPUs will be shipping with 4 dedicated accelerators within each CPU tile.
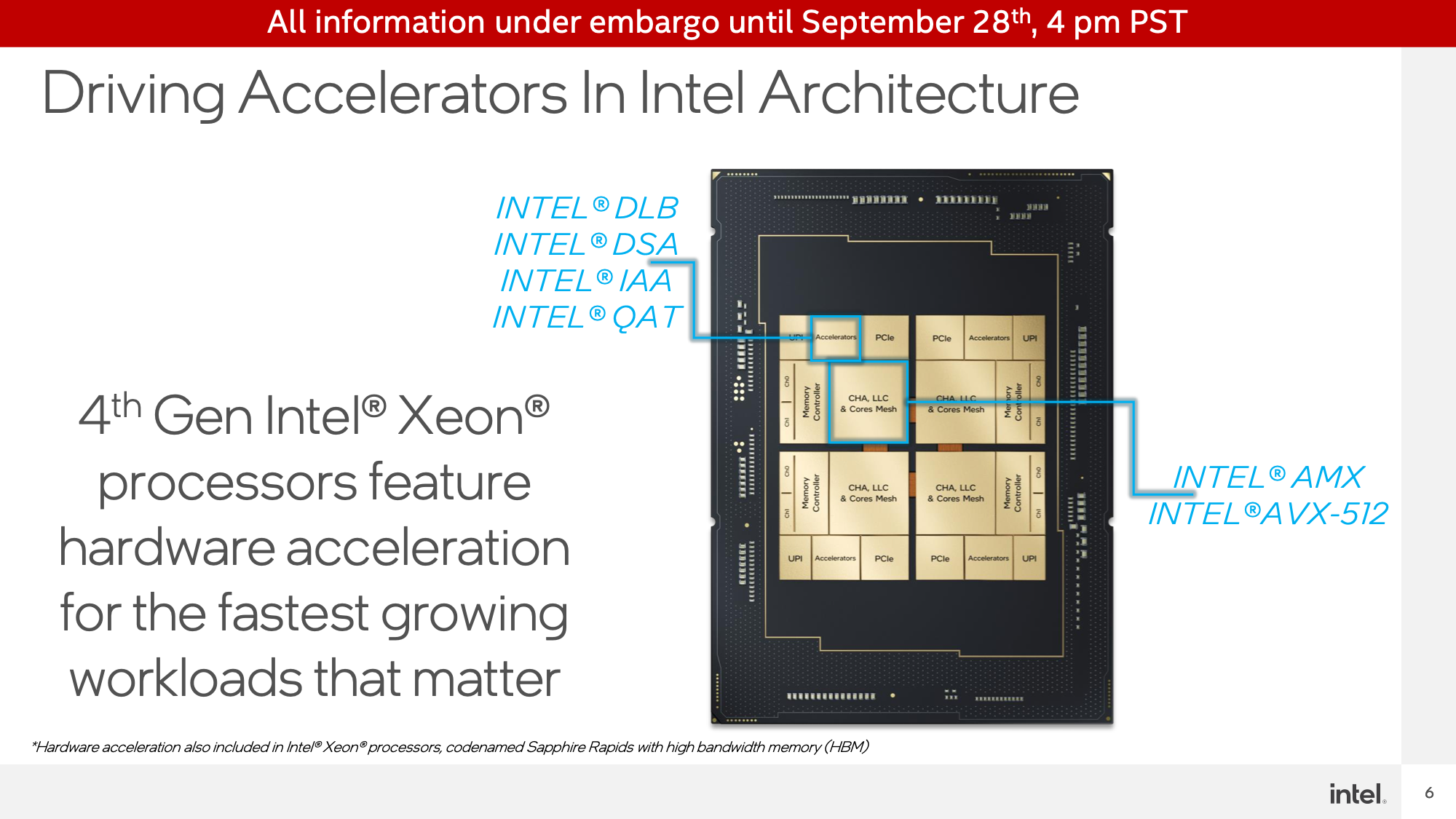
These are Intel Dynamic Load Balancer (DLB), Intel Data Streaming Accelerator (DSA), Intel In-Memory Analytics Accelerator (IAA), and Intel QuickAssist Technology (QAT). All of these hang off of the chip mesh as dedicated devices, and essentially function as PCIe accelerators that have been integrated into the CPU silicon itself. This means the accelerators don’t consume CPU core resources (memory and I/O are another matter), but it also means the number of accelerator cores available doesn’t directly scale up with the number of CPU cores.
Of these, everything but QAT is new to Intel. QAT is the exception as the previous generation of that technology was implemented in the PCH (chipset) used for 3rd generation Xeon (Ice Lake-SP) processors, and as of Sapphire Rapids is being integrated into the CPU silicon itself. Consequently, while Intel implementing domain specific accelerators is not a new phenomena, the company is going all-out on the idea for Sapphire Rapids.

All of these dedicated accelerator blocks are designed to offload a specific set of high-throughput workloads. DSA, for example, accelerates data copies and simple computations such as calculating CRC32s. Meanwhile QAT is a crypto acceleration block as well as a data compression/decompression block. And IAA is similar, offing on-the-fly data compression and decompression to allow for large databases (i.e. Big Data) to be held in memory in a compressed form. Finally, DLB, which Intel did not demo today, is a block for accelerating load balancing between servers.
Finally, there is Advanced Matrix Extension (AMX), Intel’s previously-announced matrix math execution block. Similar to tensor cores and other types of matrix accelerators, these are ultra-high-density blocks for efficiently executing matrix math. And unlike the other accelerator types, AMX isn’t a dedicated accelerator, rather it’s a part of the CPU cores, with each core getting a block.
AMX is Intel’s play for the deep learning market, going above and beyond the throughput they can achieve today with AVX-512 by using even denser data structures. While Intel will have GPUs that go beyond even this, for Sapphire Rapids Intel is looking to address the customer segment that needs AI inference taking place very close to CPU cores, rather than in a less flexible, more dedicated accelerator.
The Demos
For today’s press demo, Intel brought out their test team to setup and showcase series of real-world demos that leverage the new accelerators and can be benchmarked to showcase their performance. For this Intel was looking to demonstrate the advantages over both unaccelerated (CPU) operation on their own Sapphire Rapids hardware – i.e. why you should use their accelerators in these style of workloads – as well as to showcase the performance advantage versus executing the same workloads on arch rival AMD’s EPYC (Milan) CPUs.
Intel, of course, has already run the data internally. So the purpose of these demos was, besides revealing these performance numbers, to showcase that the numbers were real and how they were getting them. Make no mistake, this is Intel wanting to put its best foot forward. But it is doing so with real silicon and real servers, in workloads that (to me) seem like reasonable tasks for the test.

QuickAssist Technology Demo
First up was a demo for the QuickAssist Technology(QAT) accelerator. Intel started with a NGINX workload, measuring OpenSSL crypto performance.
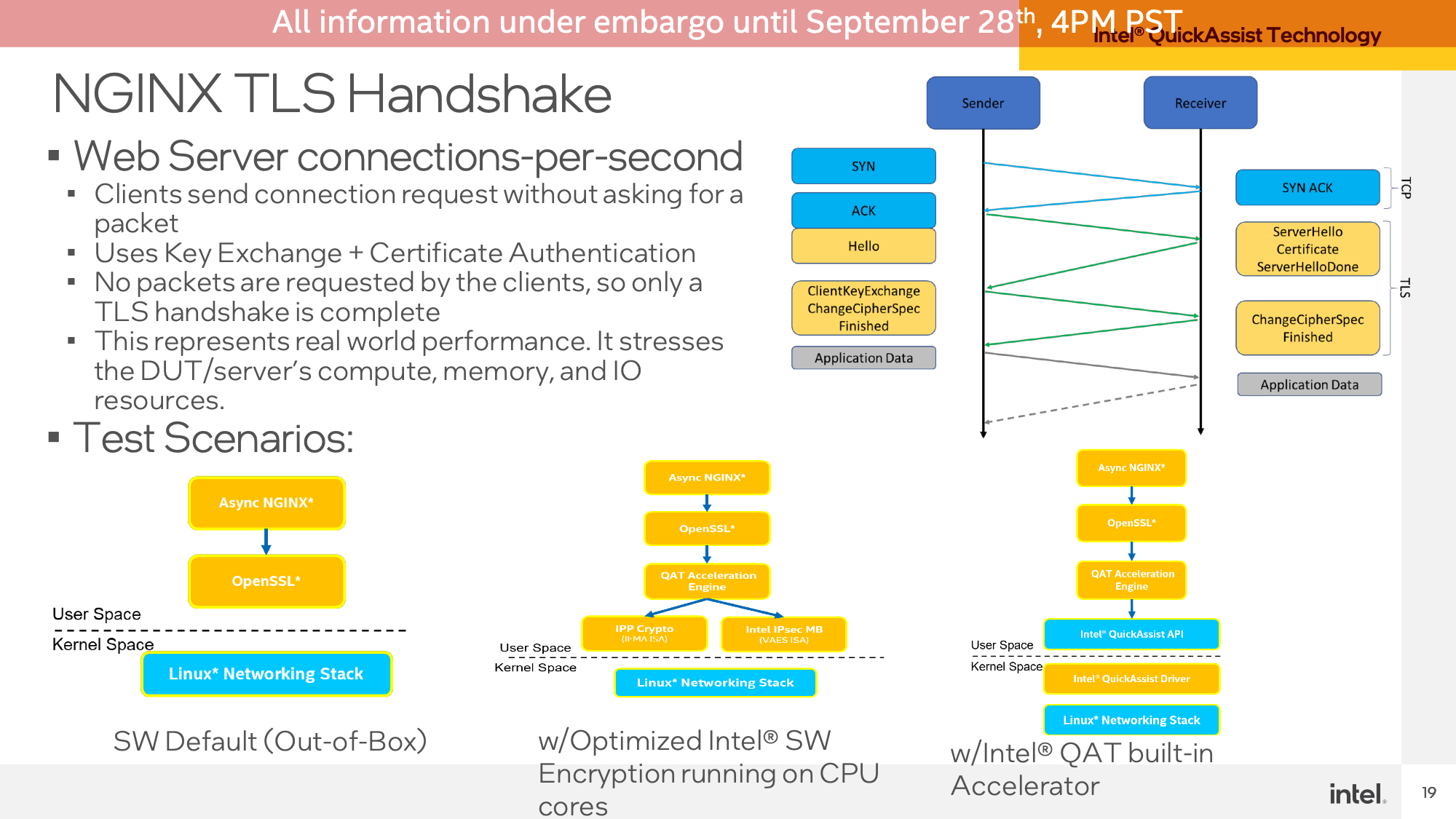
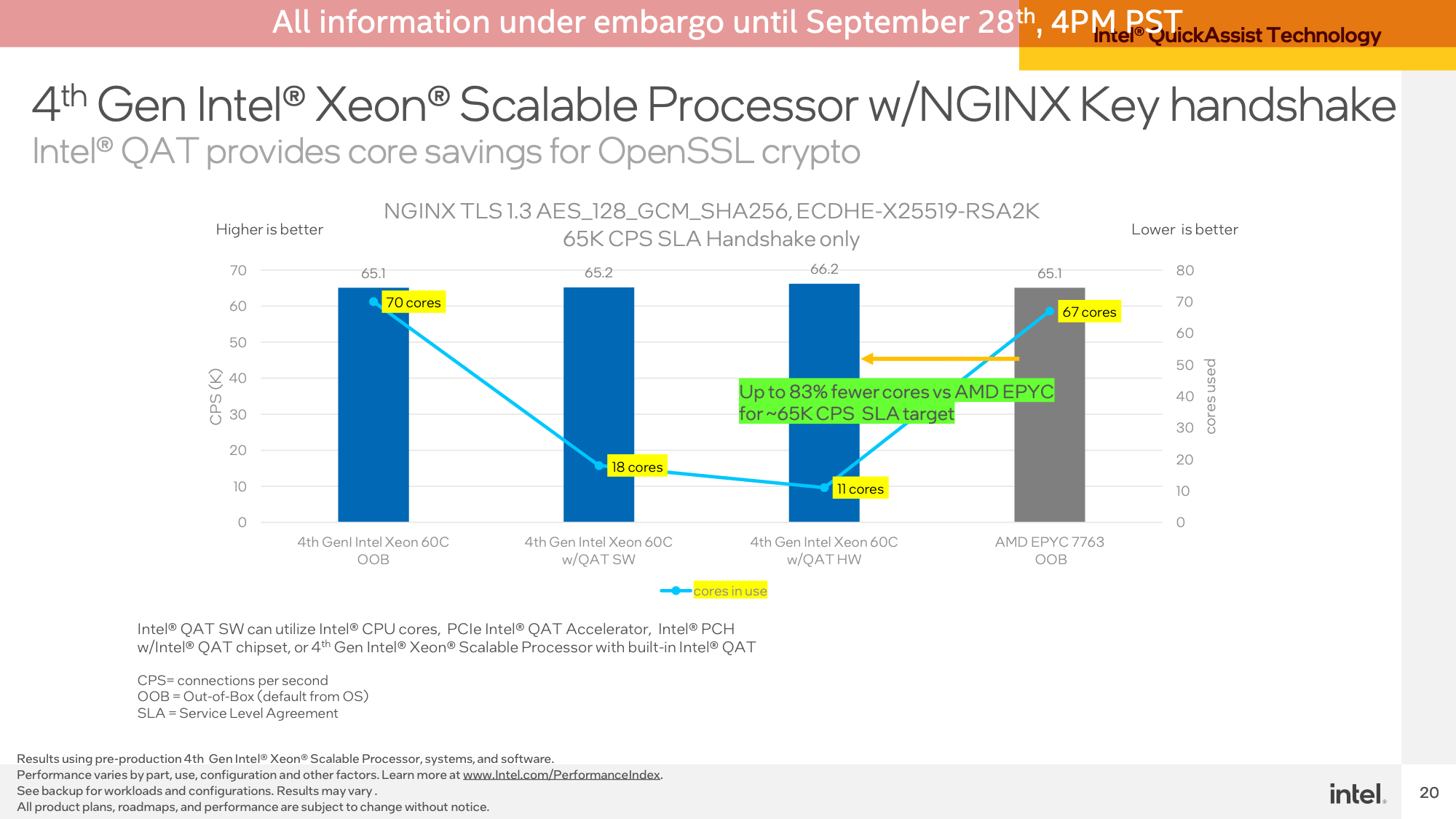
Aiming for roughly iso-performance, Intel was able to achieve roughly 66K connections per second on their Sapphire Rapids server, using just the QAT accelerator and 11 of the 120 (2x60) CPU cores to handle the non-accelerated bits of the demo. This compares to needing 67 cores to achieve the same throughput on Sapphire Rapids without any kind of QAT acceleration, and 67 cores on a dual socket EPYC 7763 server.

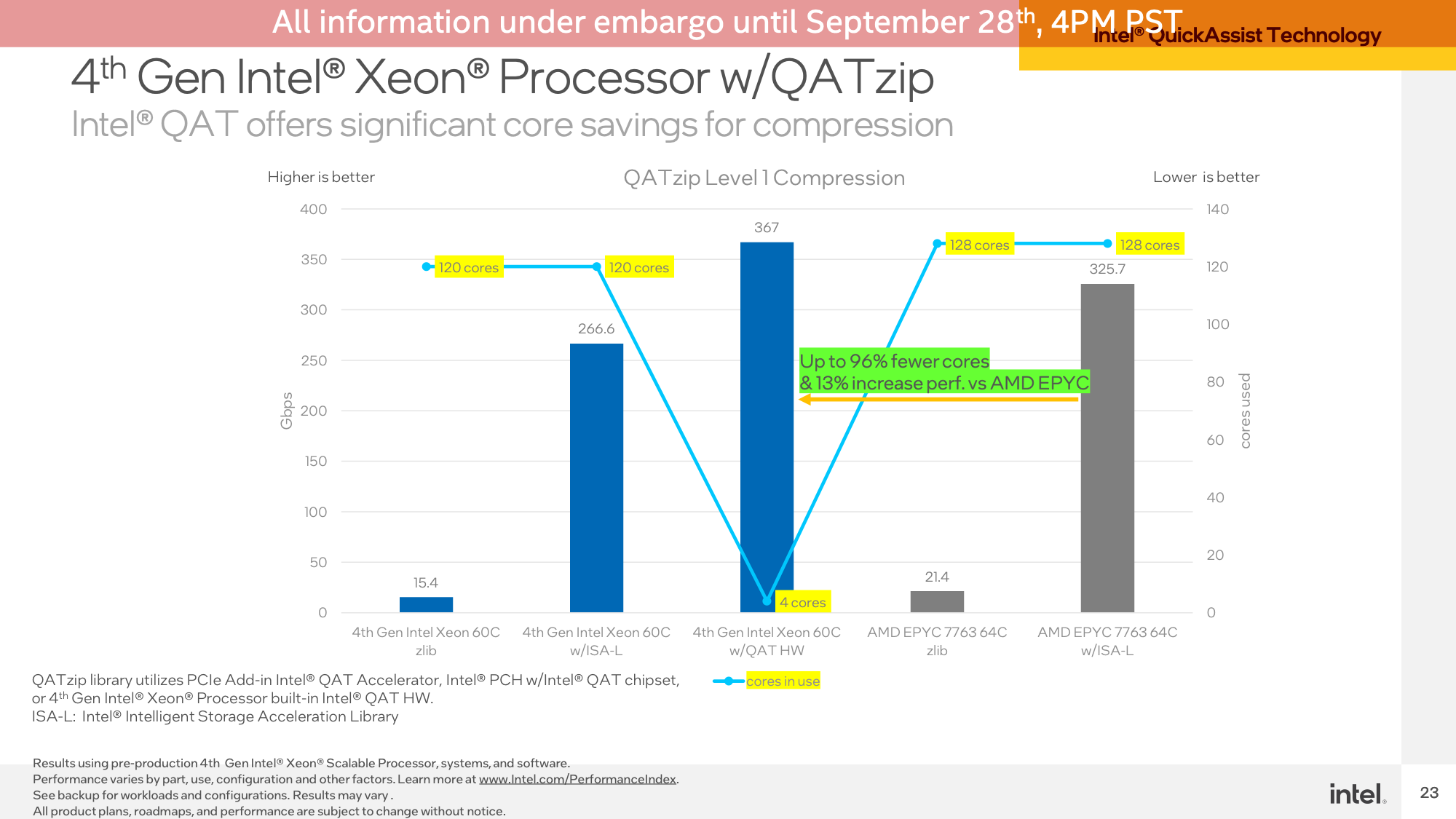
The second QAT demo was measuring compression/decompression performance on the same hardware. As you’d expect for a dedicated accelerator block, this benchmark was a blow-out. The QAT hardware accelerator blew past the CPUs, even coming in ahead of them when they used Intel’s highly optimized ISA-L library. Meanwhile this was an almost entirely-offloaded task, so it was consuming 4 CPU cores’ time versus all 120/128 CPU cores in the software workloads.

In-Memory Analytics Accelerator Demo
The second demo was of the In-Memory Analytics Accelerator. Which, despite the name, doesn’t actually accelerate the actual analyzing portion of the task. Rather it’s a compression/decompression accelerator primed for use with databases so that they can be operated on in memory without a massive CPU performance cost.
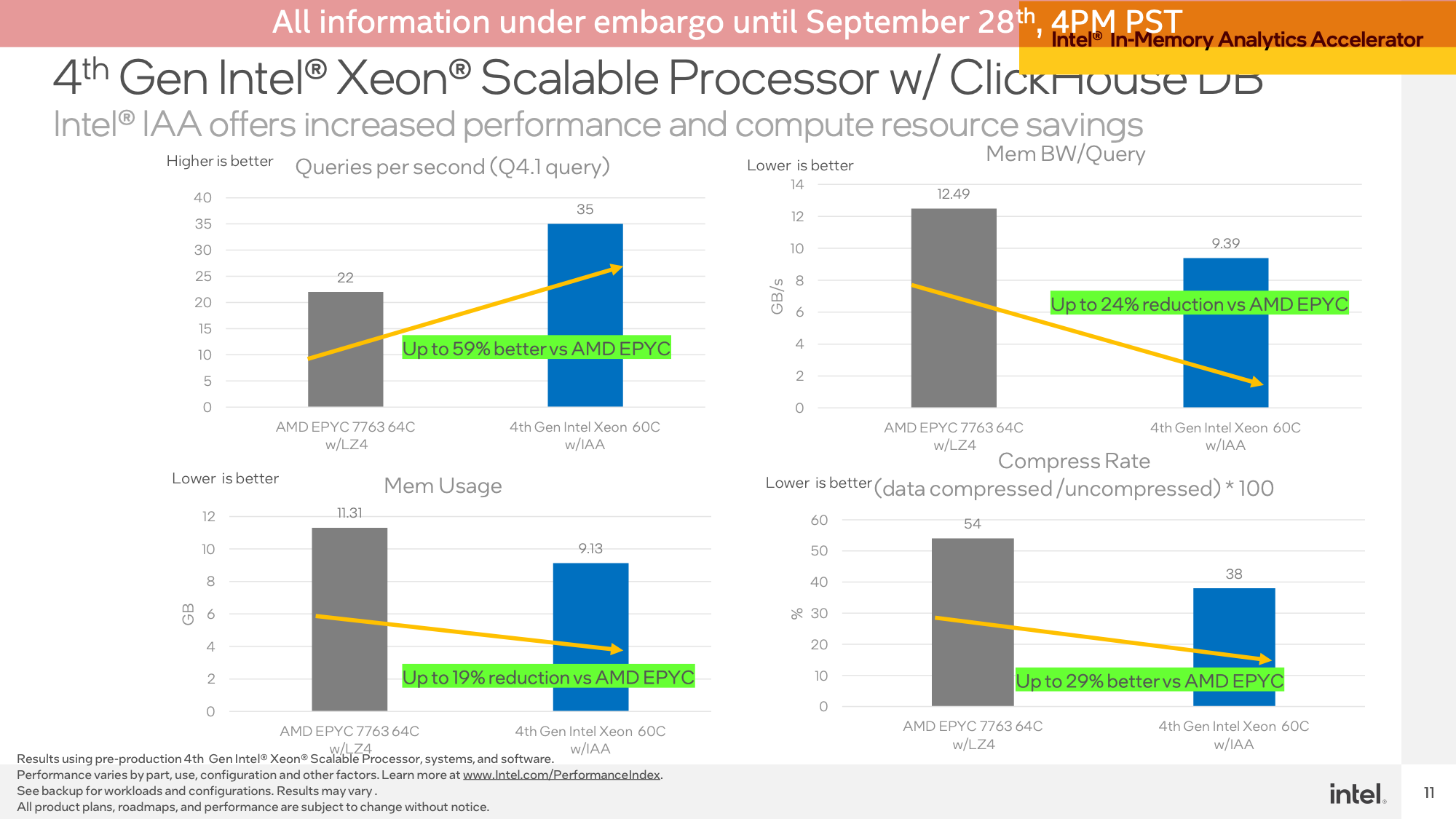
Running the demo on a ClickHouse DB, this scenario demonstrated the Sapphire Rapids system seeing a 59% queries-per-second performance advantage versus an AMD EPYC system (Intel did not run a software-only Intel setup), as well as reduced memory bandwidth usage and reduced memory usage overall.
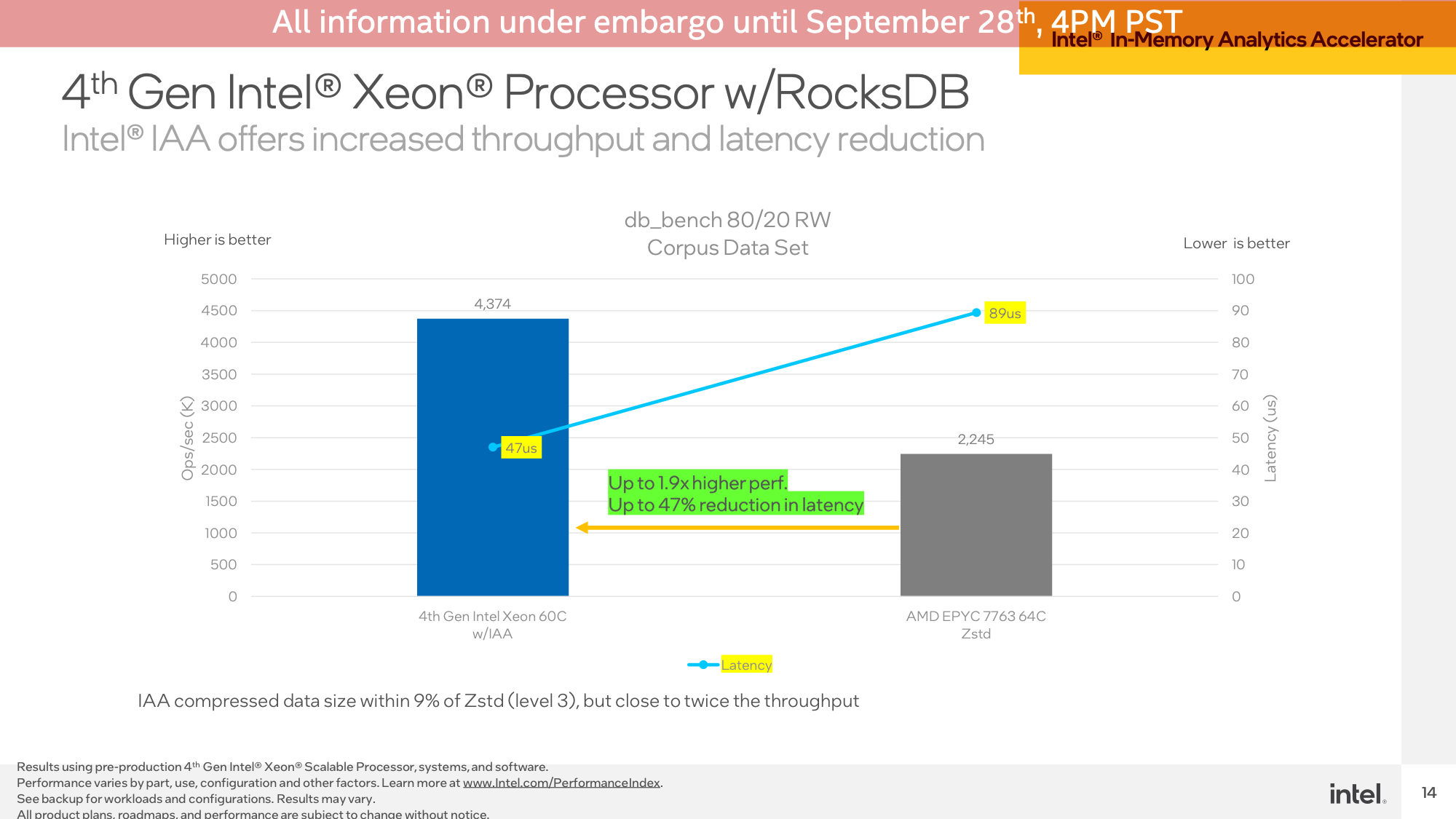
The second IAA demo was a set against RocksDB with the same Intel and AMD systems. Once again Intel demonstrated the IAA-accelerated SPR system coming out well ahead, with 1.9x higher performance and nearly half-lower latency.

Advanced Matrix Extensions Demo
The final demo station Intel had setup was configured for showcasing Advanced Matrix Extensions (AMX) and the Data Streaming Accelerator (DSA).
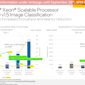
Starting with AMX, Intel ran an image classification benchmark using TensorFlow and the ResNet50 neural network. This test used unaccelerated FP32 operations on the CPUs, AVX-512 accelerated INT8 on Sapphire Rapids, and finally AMX-accelerated INT8 also on Sapphire Rapids.


This was another blow-out for the accelerators. Thanks to the AMX blocks on the CPU cores, the Sapphire Rapids system delivered just under a 2x performance increase over AVX-512 VNNI mode with a batch size of 1, and over 2x with a batch size of 16. And, of course, the scenario looks even more favorable for Intel compared to the EPYC CPUs since the current Milan processors don’t offer AVX-512 VNNI. The overall performance gains here aren’t as great as going from pure CPU to AVX-512, but then AVX-512 was already part-way to being a matrix acceleration block on its own (among other things).
Data Streaming Accelerator Demo
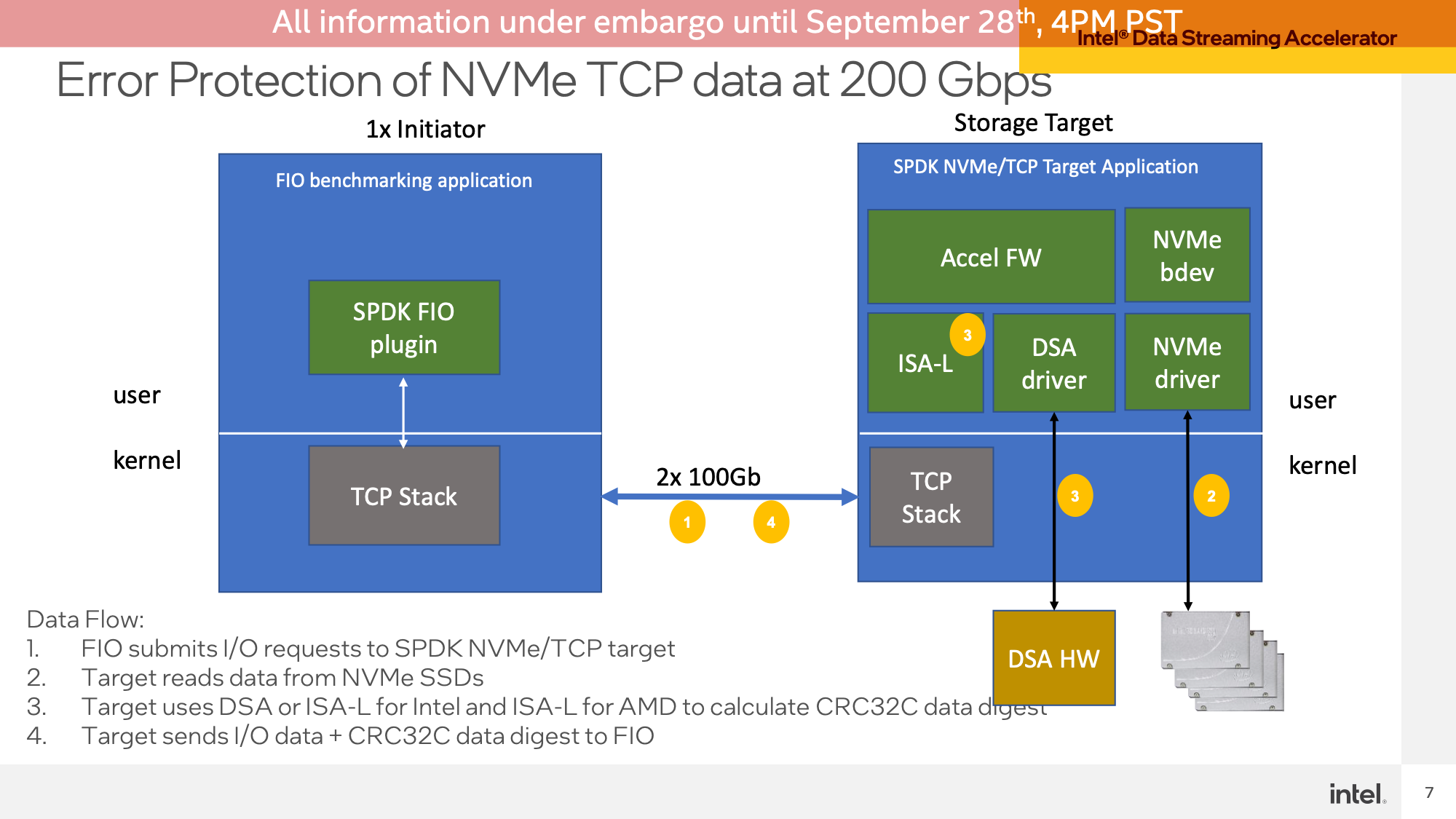
Finally, Intel demoed the Data Streaming Accelerator (DSA) block, which is back to showcasing dedicated accelerator blocks on Sapphire Rapids. In this test, Intel setup a network transfer demo using FIO to have a client read data from a Sapphire Rapids server. DSA is used here to offload the CRC32 calculations used for the TCP packets, an operation that adds up quickly in terms of CPU requirements at the very high data rates Intel was testing – a 2x100GbE connection.
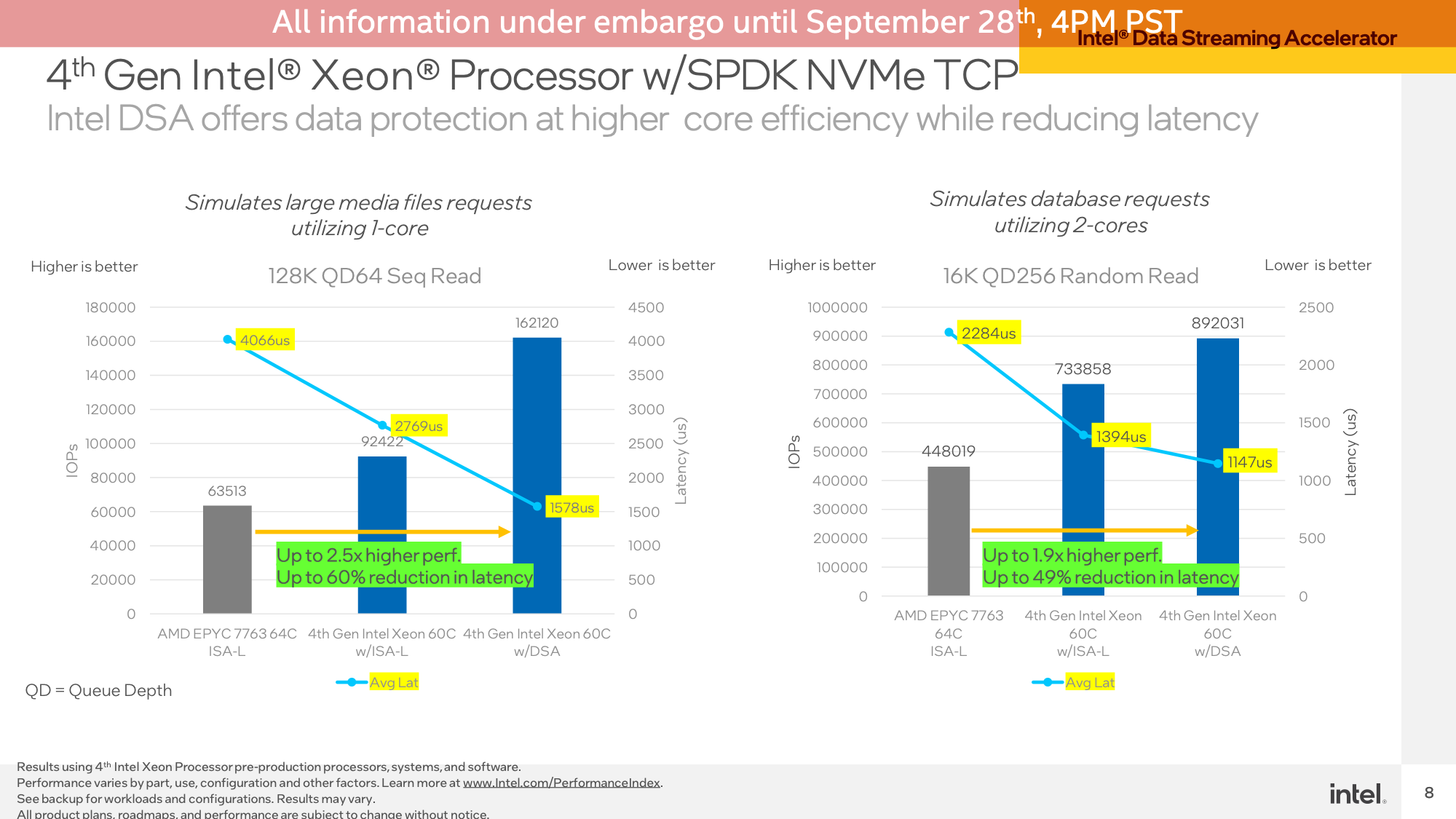
Using a single CPU core here to showcase efficiency (and because a few CPU cores would be enough to saturate the link), the DSA block allowed Sapphire Rapids to deliver 76% more IOPS on a 128K QD64 sequential read as compared to just using Intel’s optimized ISA-L library on the same workload. The lead over the EPYC system was even greater, and the latency with DSA was brought well under 2000us.
A similar test was also done with a smaller 16K QD256 random read, running against 2 CPU cores. The performance advantage for DSA was not as great here – just 22% versus optimized software on Sapphire Rapids – but again the advantage over EPYC was greater, and latencies were lower.
First Thoughts
And there you have it: the first press demo of the dedicated accelerator blocks (and AMX) on Intel’s 4th Generation Xeon (Sapphire Rapids) CPU. We saw it, it exists, and it's the tip of the iceberg for everything that Sapphire Rapids is slated to bring to customers starting next year.
Given the nature of and the purpose for domain specific accelerators, there’s nothing here that I feel should come as a great surprise to regular technical readers. DSAs exist precisely to accelerate specialized workloads, particularly those that would otherwise be CPU and/or energy intensive, and that’s what Intel has done here. And with the competition in the server market expected to be a hot one for general CPU performance, these accelerator blocks are a way for Intel to add further value to their Xeon processors, as well as stand out from AMD and other rivals that are pushing even larger numbers of CPU cores.
Expect to see more on Sapphire Rapids over the coming months, as Intel gets closer to finally shipping their next-generation server CPU.










39 Comments
View All Comments
BushLin - Wednesday, September 28, 2022 - link
Neat. The first question which enters my head is what are the software requirements to make use of the accelerators? i.e. will you need rewritten compression binaries, network drivers specifically making use of the hashing acceleration hardware, new database software..Or are any of these features going to simply make existing software much more efficient?
Jorgp2 - Wednesday, September 28, 2022 - link
?Most software packages support it out of the box, they're not really new things.
Alexey Milovidov - Wednesday, October 12, 2022 - link
You can check the pull request to ClickHouse adding support for QPL:https://github.com/ClickHouse/ClickHouse/pull/3665...
It required some effort, but it is fairly straightforward.
The patches are merged into the main branch and available in the latest release under an experimental flag.
JVlocal - Friday, October 21, 2022 - link
Bonjour les BTS SNIR 2JVlocal - Friday, October 21, 2022 - link
La réponse à la question D c'est dauphinJVlocal - Friday, October 21, 2022 - link
Félicitation, vous avez tout lu, maintenant attendez sagementJVlocal - Friday, October 21, 2022 - link
Bonjour les BTS SNIR 2SarahKerrigan - Wednesday, September 28, 2022 - link
Looks like a decent set of blocks, and a nice way to differentiate from AMD. (Also looks like the kind of stuff RISC/UNIX and mainframe platforms have been doing for years - especially Oracle, but also IBM.)name99 - Thursday, September 29, 2022 - link
And, for that matter, Apple:AMX of course even has the same name!
Data Streaming and the crypto/network acceleration stuff are done via DMA.
The most interesting case is the "In-Memory Analytics" where I can't tell from the article what Intel is ACTUALLY doing (in memory compression?)
It is possible (unclear but certainly possible) that the A15 has genuine PiM hardware. I'm still hoping that we'll eventually get decent M2 cross-sections, or an A16 cross-section which shed light on this. I discuss my thinking about this in vol5 (Packaging) of my M1 books at https://github.com/name99-org/AArch64-Explore (all massively updated about a week ago).
evilpaul666 - Thursday, September 29, 2022 - link
Intel's doing a lot better now that they're not spending all their cash buying back shares of their stock. They should have some really nice products rolling out of the new fabs we paid for in a couple years.